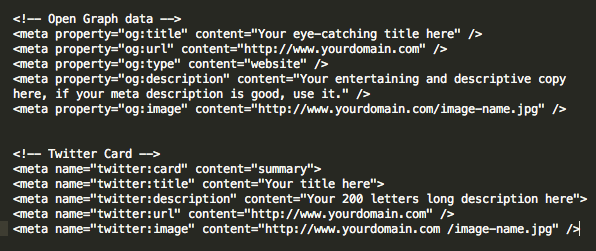
The ultimate guide to the meta robots tag
Содержание:
- Ошибки использования robots и X-Robots-Tag
- Метатег robots: cинтаксис, виды и примеры
- Types of robots meta directives
- What Are Robots Meta Tags?
- Директивы Meta Robots, которые стоит использовать в SEO
- Что такое мета-тег Robots и как его использовать?
- Что такое мета-теги
- Как еще можно использовать robots.txt?
- Как с помощью расширения обнаружить статьи с мета-тегом?
- Отличия между meta robots noindex и Disallow в robots.txt
- X-Robots-Tag—the HTTP header equivalent
- Мета-теги. Виды, задачи и шаблоны для оптимизаторов
- Суть тега
Ошибки использования robots и X-Robots-Tag
Несогласованность с файлом robots.txt
В официальных справках по X-Robots-Tag и метатегу robots в Google и Яндексе сказано, что у поискового робота должен быть доступ к сканированию контента, который нужно скрыть из индекса. В этом случае указание директивы disallow для определенной страницы в файле robots.txt делает невидимыми директивы страницы, в том числе запрещающие индексацию.
Еще одной ошибкой является попытка запретить индексацию страниц с помощью robots.txt. Основная функция robots.txt — в ограничении сканирования, а не запрете индексации. Следовательно, для управления отображением страниц в поиске нужно использовать метатег robots и тег x-robots.
Несвоевременное удаление атрибута noindex с актуальной страницы
Если вы используете директиву noindex, чтобы временно скрыть контент из индекса, важно вовремя удалить ее со страницы и открыть роботу доступ. Например, это может быть страница с запланированным акционным предложением, которое уже вступило в силу
Или же станица, которая была в процессе разработки и теперь полностью готова. Если директиву не убрать, страница не появится в выдаче, а значит не будет генерировать трафик.
Наличие обратных ссылок на страницу с атрибутом nofollow
Команда nofollow может не сработать, если сама страница — не единственный способ для поисковика узнать об URL-адресах, и на них ведут внешние ссылки с «открытых» источников.
Удаление URL-адреса из карты сайта до его деиндексации
Если страница содержит директиву noindex или отдает запрет индексации URL, стоит ли ее удалить из файла sitemap.xml? Такое решение будет неверным, поскольку карта сайта дает роботу возможность быстрее находить все страницы, в том числе те, которые нужно убрать из индекса.
Правильным решением будет создать отдельный файл sitemap.xml со списком страниц, содержащих директивы noindex, и удалять URL оттуда по мере их деиндексации. Чтобы ускорить процесс обхода дополнительной карты сайта роботом, можно загрузить ее в Google Search Console или Яндекс.Вебмастер.
Отсутствие проверки индексации после внесения изменений
При самостоятельной настройке индексации или в ходе работы программиста бывают ситуации, когда важный контент ошибочно оказался под запретом индексации. После внесения изменений страницы сайта нужно проверять.
Как избежать ошибочной деиндексации важных страниц?
Кроме проверки индексации URL указанными выше способами, можно отследить изменения кода на сайте с помощью инструмента «Отслеживание изменений» в SE Ranking.
Как быть, если актуальная страница перестала отображаться в поиске?
Необходимо удалить директивы, запрещающие индексацию страницы, а также проверить, нет ли запрета ее сканирования командой disallow в robots.txt и указан ли ее адрес в файле sitemap. Запросить индексацию URL, а также уведомить поисковики об обновленной карте сайта можно через Яндекс.Вебмастер и Google Search Console.
Больше информации можно найти в статье о принципах индексации сайта в поисковиках.
Метатег robots: cинтаксис, виды и примеры
Напомним, что метатег robots — это информация для робота в html-коде. Этот тег размещают в верхнем разделе <head> в html-документе и у него неизменно есть два атрибута — name и content, в которых указывают название робота и директивы для него. Атрибуты метатега всегда должны быть заполнены. В упрощенном виде он выглядит так:
Атрибут name
Этот параметр определяет тип метатега в зависимости от данных страницы, которые он передает поисковым системам. Например, meta name=»description» — краткое описание страницы в сниппете; meta name=»viewport» нужен для оптимизации сайта для мобильных устройств; meta http-equiv=»Content-Type» задает тип документа и его кодировки.
В случае с метатегом meta name=»robots» атрибут name содержит имя робота, для которого действуют правила, перечисленные в атрибуте content. Его функция аналогична директиве User-agent в robots.txt, содержащей идентификатор бота той или иной поисковой системы.
Значение robots используют, если нужно обратиться к краулерам всех поисковиков. Тег meta «googlebot», «yandex» или «любой другой бот» говорит о том, что инструкции адресованы соответствующему поисковому роботу. Если краулеров несколько, для каждого создают отдельный тег.
Атрибут content
Этот атрибут содержит команды, с помощью которых управляют индексированием контента на странице и отображением его элементов в результатах поиска. В него добавляют директивы из приведенных выше таблиц.
Примечания:
- Оба атрибута не чувствительны к регистру.
- Если значения атрибутов отсутствуют или заполнены неверно, бот проигнорирует запрет индексации.
- При обращении к нескольким роботам используют отдельный метатег robots для каждого. Директивы атрибута content можно перечислять через запятую в одном метатеге robots.
Файл robots.txt и метатег robots meta
При обходе сайта поисковые боты в первую очередь обращаются к файлу robots.txt. В нем они получают рекомендации по сканированию страниц и затем переходят к их обработке. Поэтому если доступ к странице закрыт в файле robots.txt, робот не сможет просканировать страницу и обнаружить в коде запрет индексации.
Если страница содержит атрибут noindex, но при этом закрыта от сканирования в robots.txt, она может отобразиться в результатах поиска — например, если робот найдет страницу, перейдя по обратной ссылке из другого источника. Содержимое файла robots.txt является общедоступным, поэтому нельзя быть уверенными, что на «закрытые» страницы не будет переходов.
Следовательно, закрывая страницу от индексации метатегом robots, стоит убедиться в отсутствии препятствий для ее сканирования в файле robots.txt. К исключениям, когда robots.txt имеет смысл использовать для скрытия из индекса, относятся изображения.
Как внедрять метатег robots
Через html-редактор
Редактирование страниц аналогично работе с текстовым файлом. Нужно найти документ, открыть его в текстовом редакторе, добавить метатеги robots в раздел <head> и сохранить.
Страницы находятся в корневом каталоге сайта, куда можно перейти из персонального аккаунта хостинг-провайдера или по FTP. Перед внесением правок стоит сохранить исходный вариант документа.
Через CMS
Более простой способ закрыть страницу от индексации — через админпанель CMS. Например, SEO-плагины «All in one SEO» и «Yoast SEO» для WordPress дают возможность запретить индексацию или переходы по ссылкам в режиме редактирования страницы.
Как проверить метатег robots
Поисковой машине нужно время, чтобы проиндексировать/деиндексировать страницу. Чтобы убедиться в отсутствии страницы в поиске, нужно воспользоваться сервисом для вебмастеров или плагином для браузера, проверяющим метатеги, например, SEO META in 1 CLICK для Chrome.
Google и Яндекс дают возможность проверить наличие страницы в индексе — для этого есть инструмент «Проверка URL» Google Search Console и аналогичная опция «Проверить статус URL» в Яндекс.Вебмастере.
Если анализ страницы показал, что метатег robots не сработал, нужно проверить, не заблокирован ли этот URL в файле robots.txt, обратившись к этому файлу через строку браузера или используя инструмент для проверки от или Яндекса.
Также проверить наличие страниц в индексе для разных поисковых систем можно с помощью инструмента «Проверка индексации» в SE Ranking.
Types of robots meta directives
There are two main types of robots meta directives: the meta robots tag and the x-robots-tag. Any parameter that can be used in a meta robots tag can also be specified in an x-robots-tag.
We’ll talk about both the meta robots and x-robots tag directives below.
Meta robots tag
The meta robots tag, commonly known as «meta robots» or colloquially as a «robots tag,» is part of a web page’s HTML code and appears as code elements within a web page’s section:

Code sample:
<pre><meta name=»robots» content=»»></pre>
While the general tag is standard, you can also provide directives to specific crawlers by replacing the «robots» with the name of a specific user-agent. For example, to target a directive specifically to Googlebot, you’d use the following code:
<meta name="googlebot" content="">
Want to use more than one directive on a page? As long as they’re targeted to the same «robot» (user-agent), multiple directives can be included in one meta directive – just separate them by commas. Here’s an example:
<meta name="robots" content="noimageindex, nofollow, nosnippet">
This tag would tell robots not to index any of the images on a page, follow any of the links, or show a snippet of the page when it appears on a SERP.
If you’re using different meta robots tag directives for different search user-agents, you’ll need to use separate tags for each bot.
What Are Robots Meta Tags?
A Robots meta tag, also known as robots tags, is a piece of HTML code that’s placed in the <head></head> section of a web page and is used to control how search engines crawl and index the URL.
This is what a robots meta tag looks like in the source code of a page:
These tags are page-specific and allow you to instruct search engines on how you want them to handle the page and whether or not to include it in the index.
What Are Robots Meta Tags Used For?
Robots meta tags are used to control how Google indexes your web page’s content. This includes:
- Whether or not to include a page in search results
- Whether or not to follow the links on a page (even if it is blocked from being indexed)
- Requests not to index the images on a page
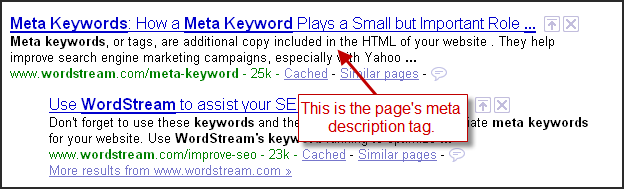
- Requests not to show cached results of the web page on the SERPs
- Requests not to show a snippet (meta description) for the page on the SERPs
In order to understand how you can use the robots meta tag, we need to look at the different attributes and directives. We’ll also share code examples that you can take and drop into your page’s header to request the search engines to index your page in a certain way.
Run a Technical Site Audit
with the Semrush Site Audit Tool
Try for Free →
Try for Free →
Директивы Meta Robots, которые стоит использовать в SEO
Как мы видим из предыдущей таблицы, не все атрибуты метатега Robots поддерживаются поисковой системой Google, под которую оптимизируют сайты большинство разработчиков и SEO-специалистов. Поэтому рассмотрим те атрибуты метатега Robots, которые поддерживаются Google:
- nosnippet,
- noimageindex,
- noarchive,
- unavailable_after.
Все они прописываются в блоке страницы, к которой вы хотите применить те или иные инструкции по индексации.
Nosnippet
Для решения проблемы вам следует использовать инструкцию следующего вида:
Также важно учитывать, что атрибут nosnippet отключает и отображение расширенных сниппетов в результатах поиска. К тому же, исследование HubSpot показало, что сниппеты с расширенной информацией получают в два раза больше кликов
Соответственно, отключение сниппета может стать причиной снижения CTR вашего сайта или отдельных его страниц
К тому же, исследование HubSpot показало, что сниппеты с расширенной информацией получают в два раза больше кликов. Соответственно, отключение сниппета может стать причиной снижения CTR вашего сайта или отдельных его страниц.
Noimageindex
Директива noimageindex позволит скрыть графический контент на вашем сайте из результатов поиска по картинкам. Это может быть полезно, если вы, к примеру, хотите разместить на своём блоге уникальные изображения и при этом минимизировать риск воровства.
Чтобы запретить поисковым системам индексировать изображения, задайте в блоке html-документа следующую директиву:
Действие необходимо повторить с каждой страницей, которая содержит изображения, которые вы хотите скрыть от поисковиков. Учитывайте, что если другие сайты уже ссылались на ваши изображения, поисковики могут продолжать индексировать их.
Запрещая индексацию изображений, не забывайте о том, что поиск по картинкам может приносить хороший дополнительный трафик вашему сайту.
Noarchive
Вопреки распространённому мнению, директива noarchive никак не влияет на ранжирование — эту информацию подтвердил в своем Твиттере ведущий аналитик компании Google, специалист отдела качества поиска по работе с вебмастерами Джон Мюллер (John Mueller).
Директива unavailable_after наиболее актуальна для страниц с акционными предложениями. Так как по истечению времени действия акции они теряют свою актуальность, вы можете указать поисковикам дату крайнего срока индексации контента. Дату и время нужно указывать в формате RFC 850.
К примеру, если вам нужно исключить возможность индексации страницы после 25 марта 2019 года, используйте метатег следующего вида:
Отдельно отметим, что для правильного функционирования тега необходимо, чтобы он был прописан до первого обхода роботом. В таком случае запрос на удаление из поисковой выдачи займёт примерно сутки после указанной даты.
Что такое мета-тег Robots и как его использовать?
Это один из многочисленных тегов, используемых для сообщения роботам и/или браузерам т.н. метаданных (т.е. информации об информации). Среди самых известных и часто используемых:
- .
- .
Что прописывать в тег robots?
Выглядит он так:
Вместо многоточия может быть 7 основных вариантов. Каждый вариант — это комбинации специальных указаний index/noindex и follow/nofollow, а также archive/noarchive:
- index, follow. Это сообщает поисковикам о том, что нужно произвести (index), а также следовать (follow) по ссылкам, которые есть на странице.
- all. Аналогично предыдущему пункту.
- noindex,follow или просто noindex. Запрещает индексировать данную страницу, но разрешает роботу переходить по ссылкам, расположенным на ней.
- index,nofollow или просто nofollow. Запрещает переходить по ссылкам, но разрешает индексировать страницу — т.е. содержимое страницы будет отправлено , но другие страницы, на которые стоят ссылки, в индекс не попадут (при условии, что робот иными способами до них не доберётся).
- noindex, nofollow. Указание не индексировать документ и не переходить по ссылкам, содержащимся в нём.
- none. Аналогично предыдущему пункту.
-
noarchive. Данное указание запрещает показывать ссылку на сохранённую копию страницы в результатах выдачи:
Если мета-тег Robots не указан, то принимается значение по умолчанию:
То же самое происходит, если на странице указано несколько этих тегов.
Все вышеперечисленные варианты понимаются большинством поисковых систем и, в частности, Яндексом. Google тоже хорошо распознаёт эти комбинации, но также вводит кое что ещё:
- Вместо name=robots можно указать name=googlebot — «обращение» конкретно к роботу Google.
- content=nosnippet (запрещает показывать ) и content=noodp (запрещает брать содержимое сниппетов из описания сайта в каталоге DMOZ).
- content=noimageindex. При поиске по картинкам запрещает отображение ссылки на источник картинки.
- content=unavailable_after:. В качестве date следует указать дату и время, после которой Гугл перестанет индексировать эту страницу. Едва ли это когда-нибудь пригодится
В общем, Google несколько расширяет содержимое мета-тега Robots.
Куда прописывать meta name robots?
Традиционно, все мета-теги прописываются между «head» и «/head» в HTML-коде страницы.
В WordPress они легко выставляются при помощи популярного плагина All in One Seo Pack:
Мета Robots в All in One Seo Pack
Таким образом, если вам необходимо «спрятать» определённую страницу от поисковых роботов — используйте данный мета-тег.
Случайные публикации:
- Как задать срезы для объявлений РСЯ и зачем это нужно?…ылкой будет показано число 15. Из картинки выше видно, что объявление
- Как найти битые ссылки на сайте — рассматриваем все варианты…закончит сканирование, она предложит вам отчет. ГОВОРИТЕ – НЕТ. Дело в том, что отчет
- Как быстро собрать семантическое ядро с помощью инструментов PromoPultПодбор семантики — это начальный этап SEO. Сгруппированные ключевые фразы служат…
- Составляем правильный description для сайта.Когда пишешь статью на сайт, один из обязательных элементов, это составлен…
-
Что такое чёрное СЕО? Методы black SEO…способы теряют свою силу.
Up от 25 июня 2012 — пришла просто куча видео от
Оставьте комментарий:
Что такое мета-теги
Если быть предельно точным, то под мета-тегами следует понимать (X)HTML-теги <meta>, с помощью которых можно указать служебную информацию о странице. Такая информация размещается внутри контейнера <head>…</head> и не выводится на экран.
К тегам мета относятся:
- description — описание веб-страницы,
- keywords — ключевые слова,
- http-equiv — тип отправляемого документа и кодировка (charset),
- generator — CMS сайта,
- author — автор,
- copyright — авторские права,
- robots — правила индексирования страницы для роботов,
- viewport — данные о настройке области просмотра
- и другие.
Подробнее можно прочитать в справке по HTML или Википедии.
На хабрахабр приводится такое определение: meta-теги — это необязательные атрибуты, размещенные в заголовке страницы, которые могут содержать ее описание, ключевые слова к ней, информацию об авторе, управляющие команды для браузера и поисковых роботов, и прочую служебную информацию, не предназначенную для посетителей.
В этой статье мы не будем точны с технической точки зрения и к мета-тегам отнесем те служебные теги, которые 1) важны в SEO и 2) используются в любом месте веб-документа, т.е. не обязательно привязаны к контейнеру <head>. В связи с этим, приведем такое определение.
Как еще можно использовать robots.txt?
Содержимое robots.txt может включать не только список директив для обращения к поисковым системам. Поскольку файл является общедоступным, некоторые компании подходят к его созданию творчески и с юмором. Иногда там можно обнаружить картинку, логотип бренда и даже предложение о работе. Реализация нестандартного robots.txt осуществляется с помощью комментариев # и других символов.

Пользователи, которых заинтересовал robots.txt сайта, вероятнее всего разбираются в оптимизации. Поэтому документ может быть дополнительным способом поиска SEO-специалистов.
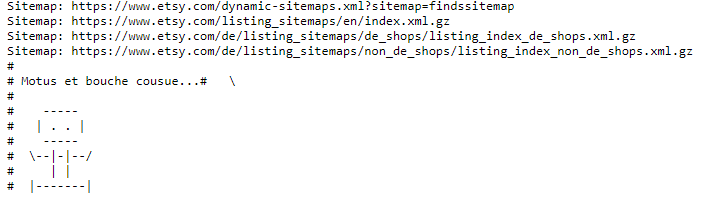
На сайте TripAdvisor:

На сайте маркетплейса Esty:
Как с помощью расширения обнаружить статьи с мета-тегом?
Значок грустного робота на странице канала
При установленном расширении проверка главной страницы канала производится автоматически. Если канал отмечен как неиндексируемый, то в меню расширения пункт «Неиндексируемые» заменяется значением «Канал не индексируется».
Если в меню расширения в редакторе указано «Канал не индексируется», значит в коде страницы канала присутствует <meta property=»robots» content=»none» />
Ещё раз подчеркну, что наличие этого кода, а значит и соответствующего оповещения в меню — норма для новых каналов.
Значок «грустного робота» на странице публикации
При установленном расширении на странице публикации может отображаться значок грустного робота.
Если в публикации есть такой значок, значит в коде страницы есть <meta name=»robots» content=»noindex» />
Соответственно, для того чтобы его увидеть нужно зайти на страницу публикации. Но зато не нужно изучать исходный код страницы.
Поиск публикаций с мета-тегом
Если вы решите проверить не одну, а десяток публикаций, то придётся заходить в каждую и проверять наличие мета-тега в каждой из них. Вручную это неудобно, поэтому в расширении предусмотрена возможность автоматической проверки.
Для того чтобы начать поиск нужно выбрать пункт меню «Неиндексируемые».
Правда, этот пункт меню будет недоступен, если весь канал отмечен, как неиндексируемый — нет смысла запускать проверку, теги будут обнаружены на всех публикациях.
При первом запуске будет отображено большое страшное предупреждение о том, что процедура поиска производится на страх и риск пользователя.
Дело в том, что стандартной процедуры поиска публикаций с мета-тегом в Дзене не предусмотрено, и расширению приходится буквально открывать каждую проверяемую публикацию и заглядывать в код страницы.
Теоретически это может быть воспринято как DDOS-атака или как попытка накрутить просмотры. На практике с этим проблем не было, но предупредить я вас обязан.
Можно проверить все публикации на канале, а можно проверить лишь 20 последних.
Процедура поиска может занять продолжительное время, по завершении вы получите список публикаций, на которых обнаружен мета-тег.
На моём канале только на одной публикации есть этот мета-тег.
Отличия между meta robots noindex и Disallow в robots.txt
Как мета-тег, так и robots.txt используются с целью запрета от индексации страниц для поисковых роботов. Но нужно учитывать особенности каждого в во избежание непредсказуемого результата.
Принципиальные отличия
Как мы уже знаем, есть два основных способа закрытия сайта от индексации:
-
<meta name="robots" content="noindex, follow"/> <!-- — запрет на индексацию контента страницы. -->
- директива Disallow в robots.txt запрет на сканирование.
В первом случае, поисковые роботы увидев данный мета-тег, не индексируют документ или убирают из своего index (если она ранее была проиндексирована). Распространяется только на ту страницу, на которой указан мета-тег.
Во втором случае, роботам запрещается даже заходить на сайт. Используя директиву Disallow, можно скрыть от индексации как один документ, так и целую директорию прописав в файле назначение, которое заканчивается слешем “/dist/profile/”.
Есть 2 важных момента:
- поисковая система Yandex рассматривает файл robots.txt как обязательную директиву, а для Google это всего лишь рекомендация. Даже если Google проиндексирует документ, то его содержание не будет иметь веса и это не скажется на ранжировании сайта, ведь стояла рекомендация “не индексировать”
- Поисковый робот может обращаться к файлу robots.txt не при каждом заходе на ваш сервер. Это значит, если ресурс ранее уже был проиндексирован, то может еще какое-то время находится в index, даже если страница закрыта в файле robots.txt.
Случаи использования meta robots noindex и Disallow в robots.txt
Мета-тег robots используется в том случае, когда мы хотим убрать определенный документ из index, даже если она уже была ранее проиндексирована. Для удобства, чтобы не перегружать robots.txt.
Писать Disallow есть смысл когда ваш сайт еще не попала в index. Это делается для запрета сканирования документов, служебных файлов и динамических частей ресурса.
X-Robots-Tag—the HTTP header equivalent
Non-HTML files such as images and PDF files don’t have an HTML source that you can include a meta robots directive in. If you want to signal your crawling and indexing preferences to search engines for these files, your best bet is to use the HTTP header.
Let’s briefly touch on HTTP headers.
When a visitor or search engine requests a page from a web server, and the page exists, the web server typically responds with three things:
- HTTP Status Code: the three-digit response to the client’s request (e.g. ).
- HTTP Headers: headers containing for example the that was returned and instructions on how long the client should cache the response.
- HTTP Body: the body (e.g. , , etc.), which is used to render and display the page in a browser.
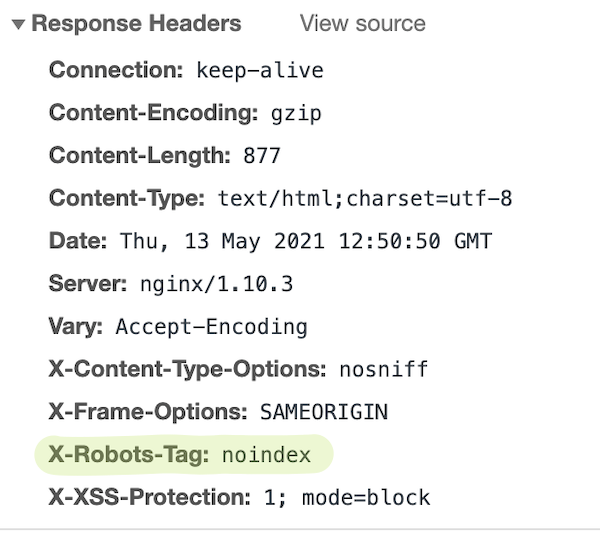
The can be included in the HTTP Headers. Here’s a screenshot of a page’s HTTP response headers taken from Chrome Web Inspector, for a page that contains a :
So how does this work in practice?
Configuring X-Robots-Tag on Apache
For example, if you’re using the Apache web server, and you’d like to add a to the HTTP response for all of your PDF files, add the following snippet to your file or file:
Or perhaps you want to make images of file types , , , and non-indexable:
Are your meta robots tags and X-Robots-Tags in conflict?
Do a quick check with ContentKing and find out if you’re sending Google into a tailspin!
Configuring X-Robots-Tag on nginx
Meanwhile on the nginx web server, you need to edit a site’s file.
To remove all PDF files from search engines’ indices across an entire site, use this:
And to noindex the images, use this:
Note that tweaking your web server configuration can negatively impact your entire website’s SEO performance. Unless you’re comfortable with making changes to your web server’s configuration, it’s best to leave these changes to your server administrator.
Because of this, we highly recommend monitoring your sites with ContentKing. Our platform immediately flags any changes so that you can revert the changes before they have a negative impact on your SEO performance.
Мета-теги. Виды, задачи и шаблоны для оптимизаторов
В контейнер заголовка также могут быть добавлены тэги, содержащие кодировку, ключевые слова web-страницы, а также код для подключения файлов каскадных таблиц стилей CSS, языка программирования JavaScript, VBScript и т.д.
Пример простейшей HTML странички, содержащей только основные тэги:
Результат работы указанного кода изображен на рисунке.
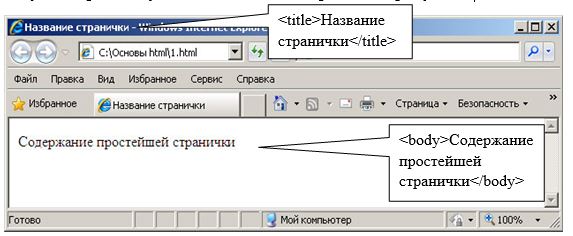
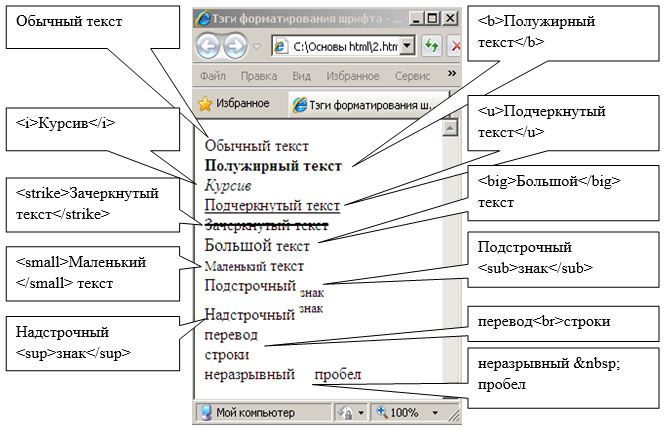
Как видно из примера текст «Содержание простейшей странички» отображается обычным текстом. Для того чтобы произвести форматирование этого текста, необходимо использовать специальные тэги. Пример использования тэгов форматирования представлен на рисунке.
Для изменения шрифта, его цвета и размера используется тэг <font> с параметрами “face”, “color” и “size”. Например для того чтобы задать шрифт “arial” красного цвета и 14 размера необходимо написать следующий код:
Для выделения абзаца в тексте используется тэг <p>, в контейнер которого как правило помещается каждый абзац текста. Для создания заголовка используются тэги <h1>, <h2>, <h3>, <h4>, <h5>, <h6>.
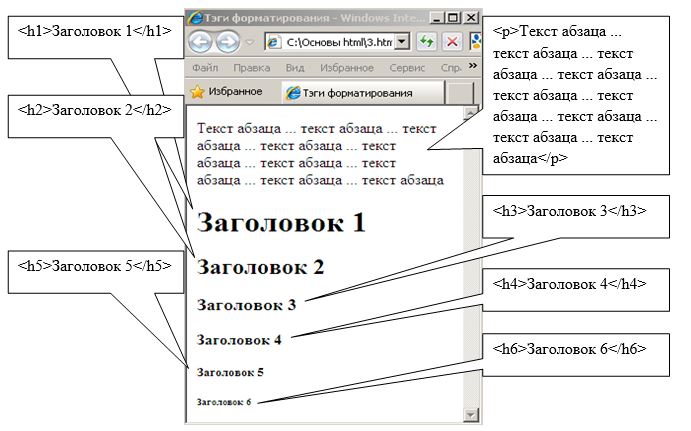
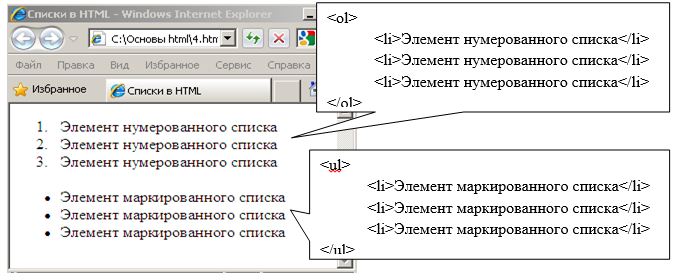
Для формирования списков в теле документа используются контейнеры <ol></ol>, <ul></ul> и <li></li>. Причем тэг <ol> формирует нурмерованный список, тэг <ul> — маркированный список, а в тэгах <li> помещаются элементы списка. Пример кода отображения списков, представленный в виде нумерованного и маркированного списков представлен на рисунке.
Для связи двух и более Web-страниц между собой используются гиперссылки, для создания которых используется тэг <a>. Причем в тэгах гиперссылок используются дополнительные атрибуты, позволяющие либо перейти к другой web-странице, либо переместиться внутри данной страницы. Второй способ желательно использовать в большом документе, имеющем несколько смысловых разделов.
Пример использования гиперссылок представлен на рисунке.
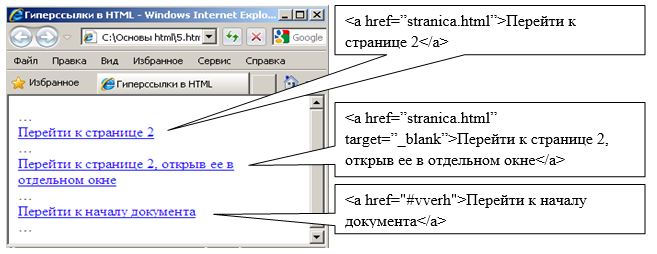
При указании URL адреса другой страницы необходимо указывать либо полный абсолютный путь к странице «полный путь/папка/страница» либо относительный (относительно данной страницы) «папка/страница». Параметр “target” позволяет открыть web-страницу в новом или существующем окне браузера.
Для вставки изображения на web-страницу используется тэг <img> с параметрами src (путь к изображению), width (ширина изображения), height (высота изображения), border (рамка вокруг рисунка). Пример кода вставки изображения:
Часто при создании Web-страниц необходимым является задание фонового цвета или фонового изображения. Для этого используются атрибуты тэга <body> «bgcolor» или «background-image». Пример вставки фонового цвета:
Пример вставки фонового изображения:
Указанные атрибуты могут быть использованы не только для тэга <body>, но и для тэгов таблицы, области и других, которые будут рассмотрены в следующих темах.
Суть тега
Тег <noindex> – это HTML-тег, который запрещает Яндексу индексировать ту или иную область страницы сайта. Для поисковой системы Google этот тег не работает, более того, в Google вообще не предусмотрена возможность исключения части текста страницы из индекса.
Заблуждение №1. Основная ошибка людей, которые используют этот тег, заключается в убеждении, что если часть какого-либо текста помещена между открывающимся и закрывающимся тегом <noindex>, то робот Яндекса не станет читать и анализировать этот текст.
Единственное, что данный тег запрещает – это помещение содержимого в индексную базу, но это содержимое в любом случае будет прочитано и проанализировано роботом.
Пример: На странице вашего сайта расположен некоторый текст, использующий прямые вхождения предложений из других сторонних источников. Следовательно, эти предложения снижают уникальность вашего текста, а вам необходимо, чтобы уникальность была 100%. Вы решаете закрыть эти предложения тегом <noindex>, чтобы Яндекс считал ваш текст уникальным. Это заблуждение.
Абсолютно весь текст вашей страницы будет прочитан и обработан роботом, и ему будет известно, что текст вашей страницы не является уникальным.
Сама суть тега <noindex> – «не индексировать», значит запрета на чтение нет.
Предположим, что поисковый робот зашел на вашу страницу и начал сканировать содержимое. В какой-то момент робот находит открытие тега <noindex>, что является сигналом роботу – дальше текст не индексировать. Но чтобы найти то место кода, где тег <noindex> закрывается, роботу необходимо прочесть содержимое, идущее после открытия данного тега. Следовательно, даже теоретически нельзя запретить роботам читать содержимое с помощью тега <noindex>.
Для чего же тогда нужен тег <noindex>?
Он нужен непосредственно для того, чтобы запретить роботу выдавать в выдаче своей поисковой системы какую-либо информацию. Это могут быть, к примеру, контакты, которые по каким-либо причинам не должны отображаться в выдаче.
Заблуждение №2. Ещё одно заблуждение, которое часто встречается среди владельцев сайтов, – это мнение, что ссылка, помещенная в тег <noindex>, не будет учтена поисковым роботом. Как я говорил ранее, всё, что находится внутри тега <noindex>, будет прочитано и проанализировано роботом Яндекса. И ссылки не являются исключением. Единственное отличие размещенных обычным образом ссылок от ссылок в теге <noindex> – это то, что текст (анкор) ссылки не будет проиндексирован.
Существует два способа написания тега <noindex> в коде:
- <noindex>Текст, запрещённый к индексированию</noindex>
- <!–noindex–>Текст, запрещённый к индексированию<!–/noindex–>
Второй вариант более верный. Так как тег не входит в официальную спецификацию языка разметки HTML, то его присутствие в коде может вызвать недопонимание у других поисковых систем, которые будут считать его наличие за ошибку. Чтобы сделать код страницы валидным, для всех поисковых роботов рекомендуется использовать закомментированный вариант написания
Яндекс такое написание распознает, а другие поисковые роботы не будет обращать внимание на его присутствие