Python, библиотека requests: быстрый старт
Содержание:
- 6: Использование Translate API
- XML. Чтение и разбор
- Задержка
- POST отправка Multipart-Encoded файла
- Объект Response
- urllib.request Restrictions¶
- GET и POST запросы с использованием Python
- Сервер сокетов
- Настройте заголовки
- Request Header Fields
- The Message Body
- Заголовки запросов
- Conclusion
- Коды состояния
- Содержимое ответа (response)
- Некоторые дополнительные функции запросов в Python
- Вывод
6: Использование Translate API
Теперь давайте попробуем использовать Yandex Translate API для выполнения запроса на перевод текста на другой язык.
Чтобы использовать API, сначала необходимо зарегистрироваться. После регистрации перейдите в Translate API и создайте ключ API. Получив ключ, добавьте его в свой файл script.py как константу.
Вот ссылка, по которой можно все сделать.
Ключ API нужен нам потому, что с его помощью Яндекс сможет аутентифицировать нас каждый раз, когда мы хотим использовать его API. Ключ API представляет собой упрощенную форму аутентификации, он добавляется в конец URL-адреса запроса при отправке.
Узнать, какой URL нужно отправить, чтобы использовать API, можно в документации Яндекса.
Там можно найти всю информацию, необходимую для использования Translate API для перевода текста.
Если в URL вы видите амперсанды (&), вопросительные знаки (?) и знаки равенства (=), вы можете быть уверены, что такой URL предназначен для запросов GET. Эти символы задают соответствующие параметры URL-адреса.
Обычно в квадратных скобках ([]) указываются опциональные фрагменты. В этом случае таковыми являются format, options и callback, в то время как key, text, and lang обязательно должны присутствовать в запросе.
Давайте добавим код для отправки запроса на этот URL. Вы можете заменить первый созданный нами запрос в файле script.py следующим кодом:
Есть два способа добавить параметры. Их можно добавить в конец URL-адреса напрямую, а можно сделать так, чтобы запросы делали это за нас. Чтобы сделать последнее, мы можем создать словарь для наших параметров. Обязательными элементами будут ключ, текст и язык. Давайте создадим словарь, используя ключ API, текст ‘Hello’ и языки ‘en-es’ (то есть текст нужно перевести с английского на испанский).
Другие языковые коды вы можете найти здесь в столбце 639-1.
Давайте создадим словарь параметров, используя функцию dict(), и передадим ей ключи и значения, которые должны быть в этом словаре. Добавьте в файл script.py:
Теперь мы возьмем словарь параметров и передадим его в функцию .get().
После этого запросы начнут добавляться к URL-адресу самостоятельно.
Теперь давайте добавим оператор print для текста ответа и посмотрим, что вернется в результате.
Здесь мы видим три вещи. Сначала идет код состояния, который в точности совпадает с кодом состояния самого ответа; затем идет язык, который мы выбрали; в конце мы видим переведенный текст.
Попробуйте еще раз, указав в качестве языка en-fr, и вы должны увидеть «Bonjour» в ответе.
Давайте посмотрим на заголовки для этого конкретного ответа.
Очевидно, заголовки будут отличаться, потому что мы обращаемся к другому серверу. В этом случае тип контента – application/json, а не text/html. Это означает, что данные могут быть интерпретированы как JSON.
Когда application/json является типом контента, мы можем сделать так, чтобы запросы преобразовывали ответ в словарь и список, чтобы легче получать доступ к данным.
Чтобы данные были обработаны как JSON, мы используем метод .json() для объекта ответа.
Если вы отобразите его, вы увидите, что данные выглядят так же, но формат немного отличается.
Теперь это не простой текст, который вы получаете из res.text, а версия словаря.
Допустим, мы хотим получить доступ к тексту. Поскольку теперь это словарь, мы можем использовать ключ text.
И теперь мы увидим только данные для этого ключа. В этом случае мы получим список из одного элемента. Если вам нужно получить этот текст в списке, можно получить к нему доступ по индексу.
И теперь на экране будет только переведенное слово.
Меняя параметры, вы будете получать разные результаты. Давайте изменим текст, вместо Hello будет Goodbye, а также изменим целевой язык на испанский и отправим запрос снова.
Также можно попробовать перевести более длинный текст на другие языки и посмотреть, какие ответы дает API.
XML. Чтение и разбор
После получения XML-портянки на этапе отладки не лишним будет проверить визуально данные в ней. Например с помощью сервиса https://jsonformatter.org/xml-parser.
В приходящем респонсе байтовая кодировка(необходимая для раскладывания xml по дереву) находится только в атрибуте content. перепишем для дальнейшей работы его в отдельную переменную responce_xml_content.
В дебагере очень похоже выглядит атрибут text у полученного responce, но он там существует как utf-8.
Большая часть мануалов по парсингу xml написана под чтение из файла и под библиотеку etree. И метод для строки из переменной fromstring в каждом классе работает несколько по разному.
Поэтому оптимальным считаю использование etree из модуля lxml. С ним проверка существования пользователя get-запросом и добавление пользователя post-запросом выглядит лаконично.
Задержка
Часто бывает нужно ограничить время ожидания ответа. Это можно сделать с помощью параметра timeout
Перейдите на
раздел — / #/ Dynamic_data / delete_delay__delay_
и изучите документацию — если делать запрос на этот url можно выставлять время, через которое
будет отправлен ответ.
Создайте файл
timeout_demo.py
следующего содержания
Задержка равна одной секунде. А ждать ответ можно до трёх секунд.
python3 timeout_demo.py
<Response >
Измените код так, чтобы ответ приходил заведомо позже чем наш таймаут в три секунды.
Задержка равна семи секундам. А ждать ответ можно по-прежнему только до трёх секунд.
python3 timeout_demo.py
Traceback (most recent call last):
File «/usr/lib/python3/dist-packages/urllib3/connectionpool.py», line 421, in _make_request
six.raise_from(e, None)
File «<string>», line 3, in raise_from
File «/usr/lib/python3/dist-packages/urllib3/connectionpool.py», line 416, in _make_request
httplib_response = conn.getresponse()
File «/usr/lib/python3.8/http/client.py», line 1347, in getresponse
response.begin()
File «/usr/lib/python3.8/http/client.py», line 307, in begin
version, status, reason = self._read_status()
File «/usr/lib/python3.8/http/client.py», line 268, in _read_status
line = str(self.fp.readline(_MAXLINE + 1), «iso-8859-1»)
File «/usr/lib/python3.8/socket.py», line 669, in readinto
return self._sock.recv_into(b)
File «/usr/lib/python3/dist-packages/urllib3/contrib/pyopenssl.py», line 326, in recv_into
raise timeout(«The read operation timed out»)
socket.timeout: The read operation timed out
During handling of the above exception, another exception occurred:
Traceback (most recent call last):
File «/usr/lib/python3/dist-packages/requests/adapters.py», line 439, in send
resp = conn.urlopen(
File «/usr/lib/python3/dist-packages/urllib3/connectionpool.py», line 719, in urlopen
retries = retries.increment(
File «/usr/lib/python3/dist-packages/urllib3/util/retry.py», line 400, in increment
raise six.reraise(type(error), error, _stacktrace)
File «/usr/lib/python3/dist-packages/six.py», line 703, in reraise
raise value
File «/usr/lib/python3/dist-packages/urllib3/connectionpool.py», line 665, in urlopen
httplib_response = self._make_request(
File «/usr/lib/python3/dist-packages/urllib3/connectionpool.py», line 423, in _make_request
self._raise_timeout(err=e, url=url, timeout_value=read_timeout)
File «/usr/lib/python3/dist-packages/urllib3/connectionpool.py», line 330, in _raise_timeout
raise ReadTimeoutError(
urllib3.exceptions.ReadTimeoutError: HTTPSConnectionPool(host=’httpbin.org’, port=443): Read timed out. (read timeout=3)
During handling of the above exception, another exception occurred:
Traceback (most recent call last):
File «timeout_demo.py», line 4, in <module>
r = requests.get(‘https://httpbin.org/delay/7’, timeout=3)
File «/usr/lib/python3/dist-packages/requests/api.py», line 75, in get
return request(‘get’, url, params=params, **kwargs)
File «/usr/lib/python3/dist-packages/requests/api.py», line 60, in request
return session.request(method=method, url=url, **kwargs)
File «/usr/lib/python3/dist-packages/requests/sessions.py», line 533, in request
resp = self.send(prep, **send_kwargs)
File «/usr/lib/python3/dist-packages/requests/sessions.py», line 646, in send
r = adapter.send(request, **kwargs)
File «/usr/lib/python3/dist-packages/requests/adapters.py», line 529, in send
raise ReadTimeout(e, request=request)
requests.exceptions.ReadTimeout: HTTPSConnectionPool(host=’httpbin.org’, port=443): Read timed out. (read timeout=3)
Если такая обработка исключений не вызывает у вас восторга — измените код используя try except
python3 timeout_demo.py
Response is taking too long.
POST отправка Multipart-Encoded файла
Если кодирование многостраничное, то с помощью запросов можно сделать загрузку файлов проще. Возможны различные действия с Multipart-Encoded файлами:
- Загрузка.
- Изменение имени файла, типа контента, заголовков.
- Отправка строк, которые используются в виде файлов.
Приведем пример, как осуществляется POST-отправка файла.
>>> url = ‘https://httpbin.org/post’
>>> files = {‘file’: open(‘report.xls’, ‘rb’)}
>>> r = requests.post(url, files=files)
>>> r.text
{
…
“files”: {
“file”: “<censored…binary…data>”
},
…
}
В некоторых случаях придется отправлять запросы потоком. К сожалению, такая функция не поддерживается стандартной библиотекой requests, тем не менее можно воспользоваться специальным пакетом, который поддерживает эту возможность. Чтобы получить более детальную информацию, необходимо воспользоваться официальной документацией requests-toolbelt.
Специалисты рекомендуют открывать все файлы в бинарном режиме, даже если они текстовые. Иначе могут время от времени возникать ошибки.
Объект Response
Response — это объект для проверки результатов запроса.
Давайте сделаем тот же запрос, но на этот раз сохраним его в переменную, чтобы мы могли более подробно изучить его атрибуты и поведение:
В этом примере вы захватили значение, возвращаемое значение , которое является экземпляром Response, и сохранили его в переменной response. Название переменной может быть любым.
Код ответа HTTP
Первый кусок данных, который можно получить из ответа — код состояния (он же код ответа HTTP). Код ответа информирует вас о состоянии запроса.
Например, статус означает, что ваш запрос был успешно выполнен, а статус означает, что ресурс не найден. Есть множество других ответов сервера, которые могут дать вам информацию о том, что произошло с вашим запросом.
Используя вы можете увидеть статус, который вернул вам в ответ сервер:
вернул 200 — это значит, что запрос успешно выполнен и сервер отдал вам запрашиваемые данные.
Иногда эту информацию можно использовать в коде для принятия решений:
Если сервер возвращает 200, то программа выведет , если код ответа 400, то программа выведет .
Requests делает еще один шаг к тому, чтобы сделать это проще. Если вы используете экземпляр Response в условном выражении, то он получит значение , если код ответа между 200 и 400, и False во всех остальных случаях.
Поэтому вы можете сделать проще последний пример, переписав :
Помните, что этот метод не проверяет, что код состояния равен 200.
Причиной этого является то, что ответы с кодом в диапазоне от 200 до 400, такие как и , тоже считаются истинными, так как они дают некоторый обрабатываемый ответ.
Например, статус 204 говорит о том, что запрос был успешным, но в теле ответа нет содержимого.
Поэтому убедитесь, что вы используете этот сокращенный вид записи, только если хотите узнать был ли запрос успешен в целом. А затем обработать код состояния соответствующим образом.
Если вы не хотите проверять код ответа сервера в операторе , то вместо этого вы можете вызвать исключение, если запрос был неудачным. Это можно сделать вызвав :
Если вы используете , то HTTPError сработает только для определенных кодов состояния. Если состояние укажет на успешный запрос, то исключение не будет вызвано и программа продолжит свою работу.
Теперь вы знаете многое о том, что делать с кодом ответа от сервера. Но когда вы делаете GET-запрос, вы редко заботитесь только об ответе сервера — обычно вы хотите увидеть больше.
Далее вы узнаете как просмотреть фактические данные, которые сервер отправил в теле ответа.
Content
Ответ на Get-запрос, в теле сообщения часто содержит некую ценную информацию, известную как «полезная нагрузка» («Payload»). Используя атрибуты и методы Response, вы можете просматривать payload в разных форматах.
Чтобы увидеть содержимое ответа в байтах, используйте :
Пока дает вам доступ к необработанным байтам полезной нагрузки ответа, вы можете захотеть преобразовать их в строку с использованием кодировки символов UTF-8. Response это сделает за вас, когда вы укажите :
Поскольку для декодирования байтов в строки требуется схема кодирования, Requests будет пытаться угадать кодировку на основе заголовков ответа. Вы можете указать кодировку явно, установив перед указанием :
Если вы посмотрите на ответ, то вы увидите, что на самом деле это последовательный JSON контент. Чтобы получить словарь, вы можете взять строку, которую получили из и десериализовать ее с помощью . Однако, более простой способ сделать это — использовать .
Тип возвращаемого значения — это словарь, поэтому вы можете получить доступ к значениям в объекте по ключу.
Вы можете делать многое с кодом состояний и телом сообщений. Но если вам нужна дополнительная информация, такая как метаданные о самом ответе, то вам нужно взглянуть на заголовки ответа.
Заголовки
Заголовки ответа могут дать вам полезную информацию, такую как тип ответа и ограничение по времени, в течение которого необходимо кэшировать ответ.
Чтобы посмотреть заголовки, укажите :
возвращает похожий на словарь объект, позволяющий получить доступ к значениям объекта по ключу. Например, чтобы получить тип содержимого ответа, вы можете получить доступ к Content-Type:
Используя ключ или — вы получите одно и то же значение.
Теперь вы узнали основное о Response. Вы увидели его наиболее используемые атрибуты и методы в действии. Давайте сделаем шаг назад и посмотрим как изменяются ответы при настройке Get-запросов.
urllib.request Restrictions¶
-
Currently, only the following protocols are supported: HTTP (versions 0.9 and
1.0), FTP, local files, and data URLs.Changed in version 3.4: Added support for data URLs.
-
The caching feature of has been disabled until someone
finds the time to hack proper processing of Expiration time headers. -
There should be a function to query whether a particular URL is in the cache.
-
For backward compatibility, if a URL appears to point to a local file but the
file can’t be opened, the URL is re-interpreted using the FTP protocol. This
can sometimes cause confusing error messages. -
The and functions can cause arbitrarily
long delays while waiting for a network connection to be set up. This means
that it is difficult to build an interactive Web client using these functions
without using threads. -
The data returned by or is the raw data
returned by the server. This may be binary data (such as an image), plain text
or (for example) HTML. The HTTP protocol provides type information in the reply
header, which can be inspected by looking at the Content-Type
header. If the returned data is HTML, you can use the module
to parse it. -
The code handling the FTP protocol cannot differentiate between a file and a
directory. This can lead to unexpected behavior when attempting to read a URL
that points to a file that is not accessible. If the URL ends in a , it is
assumed to refer to a directory and will be handled accordingly. But if an
attempt to read a file leads to a 550 error (meaning the URL cannot be found or
is not accessible, often for permission reasons), then the path is treated as a
directory in order to handle the case when a directory is specified by a URL but
the trailing has been left off. This can cause misleading results when
you try to fetch a file whose read permissions make it inaccessible; the FTP
code will try to read it, fail with a 550 error, and then perform a directory
listing for the unreadable file. If fine-grained control is needed, consider
using the module, subclassing , or changing
_urlopener to meet your needs.
GET и POST запросы с использованием Python
Существует два метода запросов HTTP (протокол передачи гипертекста): запросы GET и POST в Python.
Что такое HTTP/HTTPS?
HTTP — это набор протоколов, предназначенных для обеспечения связи между клиентами и серверами. Он работает как протокол запроса-ответа между клиентом и сервером.
Веб-браузер может быть клиентом, а приложение на компьютере, на котором размещен веб-сайт, может быть сервером.
Итак, чтобы запросить ответ у сервера, в основном используют два метода:
- GET: запросить данные с сервера. Т.е. мы отправляем только URL (HTTP) запрос без данных. Метод HTTP GET предназначен для получения информации от сервера. В рамках GET-запроса некоторые данные могут быть переданы в строке запроса URI в формате параметров (например, условия поиска, диапазоны дат, ID Объекта, номер счетчика и т.д.).
- POST: отправить данные для обработки на сервер (и получить ответ от сервера). Мы отправляем набор информации, набор параметров для API. Метод запроса POST предназначен для запроса, при котором веб-сервер принимает данные, заключённые в тело сообщения POST запроса.
Чтобы сделать HTTP-запросы в python, мы можем использовать несколько HTTP-библиотек, таких как:
- HTTPLIB
- URLLIB
- REQUESTS
Самая элегантная и простая из перечисленных выше библиотек — это Requests. Библиотека запросов не является частью стандартной библиотеки Python, поэтому вам нужно установить ее, чтобы начать работать с ней.
Если вы используете pip для управления вашими пакетами Python, вы можете устанавливать запросы, используя следующую команду:
pip install requests
Если вы используете conda, вам понадобится следующая команда:
conda install requests
После того, как вы установили библиотеку, вам нужно будет ее импортировать
Давайте начнем с этого важного шага:
import requests
Синтаксис / структура получения данных через GET/POST запросы к API
Есть много разных типов запросов. Наиболее часто используемый, GET запрос, используется для получения данных.
Когда мы делаем запрос, ответ от API сопровождается кодом ответа, который сообщает нам, был ли наш запрос успешным. Коды ответов важны, потому что они немедленно сообщают нам, если что-то пошло не так.
Чтобы сделать запрос «GET», мы будем использовать функцию.
Метод используется, когда вы хотите отправить некоторые данные на сервер.
Ниже приведена подборка различных примеров использования запросов GET и POST через библиотеку REQUESTS. Безусловно, существует еще больше разных случаев. Всегда прежде чем, писать запрос, необходимо обратиться к официальной документации API (например, у Yandex есть документация к API различных сервисов, у Bitrix24 есть документация к API, у AmoCRM есть дока по API, у сервисов Google есть дока по API и т.д.). Вы смотрите какие методы есть у API, какие запросы API принимает, какие данные нужны для API, чтобы он мог выдать информацию в соответствии с запросом. Как авторизоваться, как обновлять ключи доступа (access_token). Все эти моменты могут быть реализованы по разному и всегда нужно ответ искать в официальной документации у поставщика API.
#GET запрос без параметров
response = requests.get('https://api-server-name.com/methodname_get')
#GET запрос с параметрами в URL
response = requests.get("https://api-server-name.com/methodname_get?param1=ford¶m2=-234¶m3=8267")
# URL запроса преобразуется в формат https://api-server-name.com/methodname_get?key2=value2&key1=value1
param_request = {'key1': 'value1', 'key2': 'value2'}
response = requests.get('https://api-server-name.com/methodname_get', params=param_request)
#GET запрос с заголовком
url = 'https://api-server-name.com/methodname_get'
headers = {'user-agent': 'my-app/0.0.1'}
response = requests.get(url, headers=headers)
#POST запрос с параметрами в запросе
response = requests.post('https://api-server-name.com/methodname_post', data = {'key':'value'})
#POST запрос с параметрами через кортеж
param_tuples =
response = requests.post('https://api-server-name.com/methodname_post', data=param_tuples)
#POST запрос с параметрами через словарь
param_dict = {'param': }
response = requests.post('https://api-server-name.com/methodname_post', data=payload_dict)
#POST запрос с параметрами в формате JSON
import json
url = 'https://api-server-name.com/methodname_post'
param_dict = {'param': 'data'}
response = requests.post(url, data=json.dumps(param_dict))
Сервер сокетов
Мы сохраним программу сервера сокетов, как socket_server.py. Чтобы использовать соединение, нам нужно импортировать модуль сокета.
Затем последовательно нам нужно выполнить некоторую задачу, чтобы установить соединение между сервером и клиентом.
Мы можем получить адрес хоста с помощью функции socket.gethostname(). Рекомендуется использовать адрес порта пользователя выше 1024, поскольку номер порта меньше 1024 зарезервирован для стандартного интернет-протокола.
Смотрите приведенный ниже пример кода сервера:
import socket
def server_program():
# get the hostname
host = socket.gethostname()
port = 5000 # initiate port no above 1024
server_socket = socket.socket() # get instance
# look closely. The bind() function takes tuple as argument
server_socket.bind((host, port)) # bind host address and port together
# configure how many client the server can listen simultaneously
server_socket.listen(2)
conn, address = server_socket.accept() # accept new connection
print("Connection from: " + str(address))
while True:
# receive data stream. it won't accept data packet greater than 1024 bytes
data = conn.recv(1024).decode()
if not data:
# if data is not received break
break
print("from connected user: " + str(data))
data = input(' -> ')
conn.send(data.encode()) # send data to the client
conn.close() # close the connection
if __name__ == '__main__':
server_program()
Итак, наш сервер сокетов работает на порту 5000 и будет ждать запроса клиента. Если вы хотите, чтобы сервер не завершал работу при закрытии клиентского соединения, просто удалите условие if и оператор break. Цикл while используется для бесконечного запуска серверной программы и ожидания клиентского запроса.
Настройте заголовки
Python Requests не заставляет вас использовать заголовки при отправке запросов, однако есть несколько умных сайтов, которые не дадут вам прочитать ничего важного, если определенные заголовки не присутствуют. Однажды я столкнулся с ситуацией: HTML, который я видел в браузере отличался от того, который был в моем скрипте
Так что делать запросы настолько правильными, насколько вы можете – очень хорошая практика. Меньшее, что вы должны сделать – это установить User-Agent
Однажды я столкнулся с ситуацией: HTML, который я видел в браузере отличался от того, который был в моем скрипте. Так что делать запросы настолько правильными, насколько вы можете – очень хорошая практика. Меньшее, что вы должны сделать – это установить User-Agent.
Python
headers = {
‘user-agent’: ‘Mozilla/5.0 (Macintosh; Intel Mac OS X 10_11_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/53.0.2785.143 Safari/537.36’
}
r = requests.get(url, headers=headers, timeout=5)
|
1 2 3 4 5 |
headers={ ‘user-agent»Mozilla/5.0 (Macintosh; Intel Mac OS X 10_11_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/53.0.2785.143 Safari/537.36’ } r=requests.get(url,headers=headers,timeout=5) |
Request Header Fields
We will study General-header and Entity-header in a separate chapter when we will learn HTTP header fields. For now, let’s check what Request header fields are.
The request-header fields allow the client to pass additional information about the request, and about the client itself, to the server. These fields act as request modifiers.Here is a list of some important Request-header fields that can be used based on the requirement:
-
Accept-Charset
-
Accept-Encoding
-
Accept-Language
-
Authorization
-
Expect
-
From
-
Host
-
If-Match
-
If-Modified-Since
-
If-None-Match
-
If-Range
-
If-Unmodified-Since
-
Max-Forwards
-
Proxy-Authorization
-
Range
-
Referer
-
TE
-
User-Agent
You can introduce your custom fields in case you are going to write your own custom Client and Web Server.
The Message Body
According to the HTTP specification, , , and the less common requests pass their data through the message body rather than through parameters in the query string. Using , you’ll pass the payload to the corresponding function’s parameter.
takes a dictionary, a list of tuples, bytes, or a file-like object. You’ll want to adapt the data you send in the body of your request to the specific needs of the service you’re interacting with.
For example, if your request’s content type is , you can send the form data as a dictionary:
>>>
You can also send that same data as a list of tuples:
>>>
If, however, you need to send JSON data, you can use the parameter. When you pass JSON data via , will serialize your data and add the correct header for you.
httpbin.org is a great resource created by the author of , Kenneth Reitz. It’s a service that accepts test requests and responds with data about the requests. For instance, you can use it to inspect a basic request:
>>>
Заголовки запросов
Каждый HTTP-запрос имеет заголовки. Это метаданные, которые описывают HTTP-запрос, но не отображаются в теле запроса. Объект запроса PSR 7 Slim предоставляет несколько методов для проверки своих заголовков.
Получить все заголовки
Вы можете получить все заголовки HTTP-запросов в качестве ассоциативного массива с помощью метода объекта запроса PSR 7 . Результирующие ключи ассоциативного массива — это имена заголовков, и его значения сами представляют собой числовой массив строковых значений для их соответствующего заголовка.
Figure 5: Извлечение и повторение всех заголовков HTTP-запросов в качестве ассоциативного массива.
Получить один заголовок
Вы можете получить значения одного заголовка с помощью метода объекта PSR 7 Request. Это возвращает массив значений для данного заголовка. Помните, что один HTTP-заголовок может иметь более одного значения!
Figure 6: Получить значения для определенного HTTP-заголовка.
Вы также можете получить строку, разделенную запятыми, со всеми значениями для данного заголовка с помощью метода объекта запроса PSR 7 . В отличие от метода, этот метод возвращает строку, разделенную запятыми.
Figure 7: Get single header’s values as comma-separated string.
Обнаружение заголовка
Вы можете проверить наличие заголовка с помощью метода объекта PSR 7 Request .
Figure 8: Обнаружение присутствия определенного заголовка HTTP-запроса.
Conclusion
You’ve come a long way in learning about Python’s powerful library.
You’re now able to:
- Make requests using a variety of different HTTP methods such as , , and
- Customize your requests by modifying headers, authentication, query strings, and message bodies
- Inspect the data you send to the server and the data the server sends back to you
- Work with SSL Certificate verification
- Use effectively using , , Sessions, and Transport Adapters
Because you learned how to use , you’re equipped to explore the wide world of web services and build awesome applications using the fascinating data they provide.
Take the Quiz: Test your knowledge with our interactive “HTTP Requests With the «requests» Library” quiz. Upon completion you will receive a score so you can track your learning progress over time:
Коды состояния
Прежде всего мы проверим код состояния. Коды HTTP находятся в диапазоне от 1XX до 5XX. Наверняка вы уже знакомы с кодами состояния 200, 404 и 500.
Далее мы приведем краткий обзор значений кодов состояния:
- 1XX — информация
- 2XX — успешно
- 3XX — перенаправление
- 4XX — ошибка клиента (ошибка на вашей стороне)
- 5XX — ошибка сервера (ошибка на их стороне)
Обычно при выполнении наших собственных запросов мы хотим получить коды состояния в диапазоне 200.
Библиотека Requests понимает, что коды состояния 4XX и 5XX сигнализируют об ошибках, и поэтому при возврате этих кодов состояния объекту ответа на запрос присваивается значение .
Проверив истинность ответа, вы можете убедиться, что запрос успешно обработан. Например:
script.py
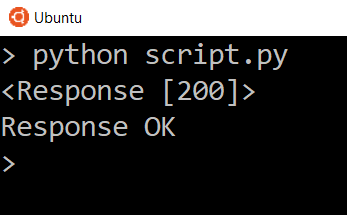
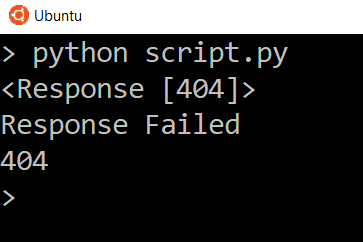
Сообщение Response Failed появится только при возврате кода состояния 400 или 500. Попробуйте заменить URL на несуществующий, чтобы увидеть ошибку ответа 404.
Чтобы посмотреть код состояния, добавьте следующую строку:
script.py
Так вы увидите код состояния и сможете сами его проверить.
Содержимое ответа (response)
Теперь поговорим о том, как прочитать, что сервер ответил нам. В качестве примера снова будем использовать GitHub.
>>> import requests
>>> r = requests.get(‘https://api.github.com/events’)
>>> r.text
‘[{“repository”:{“open_issues”:0,”url”:”https://github.com/…
Ответ сервера поступает в закодированном виде. Библиотека Requests будет автоматически производить декодирование. Как правило, если ответ пришел в кодировке Unicode, то не должно возникать никаких проблем.
Если кодировка другая, Request пытается определить, какая она, основываясь на заголовке HTTP-запроса. Можно также изменить кодировку, используя r.encoding.
>>> r.encoding
‘utf-8’
>>> r.encoding = ‘ISO-8859-1’
Последовательность действий, которая необходима в каждом конкретном случае, отличается. Так, в HTML и XML можно указать кодировку непосредственно в блоке заголовка. В таком случае сначала необходимо определить кодировку с помощью r.content, а потом установить правильную кодировку с помощью r.encoding. Это даст возможность пользоваться правильной кодировкой документа.
Если появляется необходимость, то есть возможность использовать пользовательские кодировки. Для этого необходимо ее зарегистрировать в модуле codecs, а потом просто использовать ее имя в качестве значения r.encoding.
Некоторые дополнительные функции запросов в Python
Наша статья в основном посвящена двум наиболее основным, но очень важным методам HTTP. Но модуль запросов поддерживает множество таких методов, как PUT, PATCH, DELETE и т. Д.
Одной из ключевых причин, по которой модуль “запросы” так известен среди разработчиков, являются такие дополнительные функции, как:
- Объект сеансов: Он в основном используется для хранения одних и тех же файлов cookie между различными запросами, обеспечивая более быстрый ответ.
- Поддержка прокси-серверов SOCKS: Хотя вам необходимо установить отдельную зависимость (называемую ” запросы”), она может значительно повысить производительность для нескольких запросов, особенно если скорость сервера ограничивает ваш IP-адрес.
- Проверка SSL: Вы можете принудительно проверить, правильно ли веб-сайт поддерживает SSL с помощью запросов, предоставив дополнительный аргумент” в методе get (). Если веб – сайт не показывает надлежащей поддержки SSL, скрипт выдаст ошибку.
Вывод
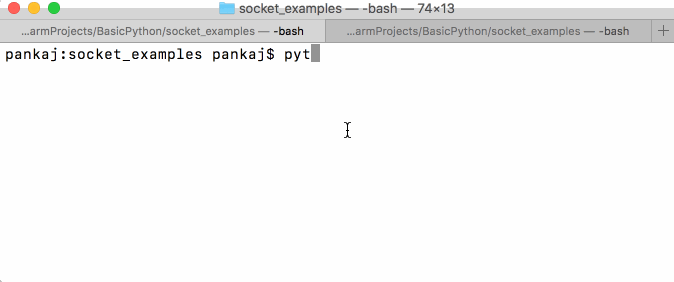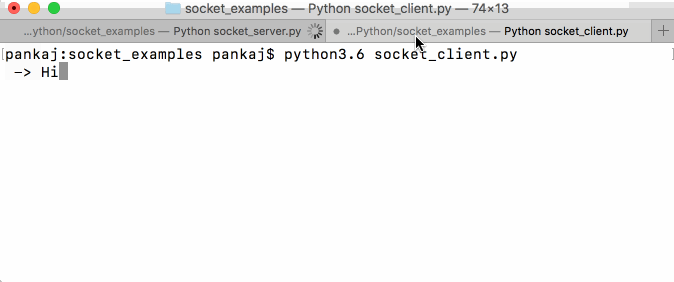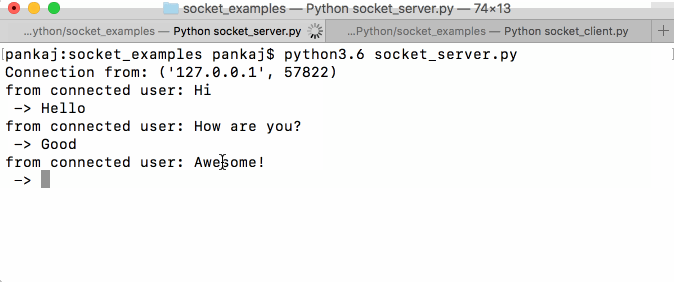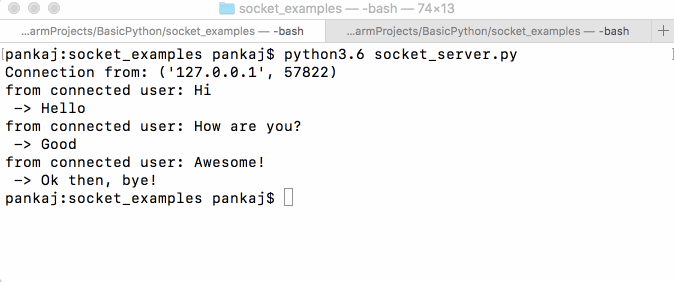
Чтобы увидеть результат, сначала запустите программу сервера сокетов. Затем запустите клиентскую программу. После этого напишите что-нибудь из клиентской программы. Затем снова напишите ответ от серверной программы.
Наконец, напишите «до свидания» из клиентской программы, чтобы завершить обе программы. Ниже короткое видео покажет, как это работало на моем тестовом прогоне примеров программ сервера сокетов и клиента.
pankaj$ python3.6 socket_server.py
Connection from: ('127.0.0.1', 57822)
from connected user: Hi
-> Hello
from connected user: How are you?
-> Good
from connected user: Awesome!
-> Ok then, bye!
pankaj$
pankaj$ python3.6 socket_client.py -> Hi Received from server: Hello -> How are you? Received from server: Good -> Awesome! Received from server: Ok then, bye! -> Bye pankaj$
Обратите внимание, что сервер сокетов работает на порту 5000, но клиенту также требуется порт сокета для подключения к серверу. Этот порт назначается случайным образом при вызове клиентского соединения
В данном случае это 57822.