Мета теги страниц сайта: title, description, keywords, robots и другие
Содержание:
- Комментарии
- Информация о документе
- Что писать в теге meta description?
- Что такое кодировка сайта
- Стандарт кодирования UTF-8
- Модуль ngx_http_charset_module
- Описание страницы и ключевые слова
- About
- Атрибуты
- Настройка области просмотра
- Как установить кодировку сайта
- UTF-8 против UTF-16
- Расшифровка мира кодировки UTF-8
- Что такое кодирование Base64?
Комментарии
Поскольку существует несколько неуправляемых строковых типов и только один управляемый строковый тип, необходимо использовать кодировку, чтобы указать, как управляемые строки должны быть упакованы в неуправляемый код.Because there are several unmanaged string types and only one managed string type, you must use a character set to specify how managed strings should be marshaled to unmanaged code. Это перечисление, предоставляющее параметры кодировки, используется DllImportAttribute и StructLayoutAttribute .This enumeration, which provides character set options, is used by DllImportAttribute and StructLayoutAttribute. Подробное описание маршалинга строк и поведения сопоставления имен, связанных с этим перечислением, см. в разделе Указаниекодировки.For a detailed description of the string marshaling and name matching behavior associated with this enumeration, see Specifying a Character Set.
Информация о документе
Пример:
<meta name=»author» Content=»Остап Бендер»><meta name=»copyright» Content=»»Рога и копыта» Остап Бендер»>
Данные метаописатели предназначены для заявления об авторских правах непосредственно в заголовке html кода, так name=»author» указывает имя автора страницы, а name=»copyright» авторское право (копирайт) в котором может указываться фамилия, имя, отчество автора сайта, название фирмы, бренда.. и т. д. Кроме того включив в заголовок документа такое описание Вы значительно упростите задачу поисковой машине при поиске Вашего сайта по имени автора, названию фирмы, бренду…
Пример:
<meta name =»Generator» Content=»Microsoft Notepad»>
Если хотите можете указать с помощью какого html редактора была написана данная страница.
Что писать в теге meta description?
О том, как правильно составить description, на что заострить внимание, подробно разъясняют поисковые системы Яндекс и Google. Мы постарались обобщить доступную официальную информацию в следующий свод рекомендаций, которые помогут составить оптимальное мета-описание для вашего сайта
Как правильно заполнить meta description:
Уникальность. Для каждой страницы вашего сайта должен быть прописан уникальный по своему содержанию description. В противном случае поисковые системы при достаточной степени схожести контента на страницах, могут посчитать их за дубликаты. И оставить в поисковой выдаче только одну страницу;
Точность. Мета-описание должно точно характеризовать конкретный контент, расположенный на одной странице. Не нужно добавлять описание всего проекта целиком в каждом мета-теге;
Релевантность. Meta description должен соответствовать той информации, которая находится на странице
Не стоит стараться привлечь внимание пользователей, использую в своих мета-описаниях заголовки из желтой прессы;
Размер. Description не должен быть сильно коротким, он не должен состоять из нескольких слов или словосочетаний
Делайте мета-описания размером не менее 100 символов;
Читабельность. Помните, что ваш сниппет будут читать люди, поэтому описание в нем должно быть емким, но в то же время простым и понятным. Не нужно стараться добавить в meta description как можно больше ключевых слов, поисковые системы с большой вероятностью проигнорируют такое описание. Используйте тематически схожие слова и слова-синонимы, чтобы избежать тавтологий;
Ключевые фразы. Ключевые слова не просто могут, они должны присутствовать в мета-описании каждой страницы. 1-3 ключевых слова в description — хорошая практика. Основное ключевое слово старайтесь разместить в первом предложении.
Обобщение. Мета-описание должно обобщать всю самую ценную информацию на странице. Систематизируйте информацию, разбросанную по странице. Например, для карточки товара это может быть краткое описание товара, цена, производитель, состав, доступные характеристики. Для информационной статьи: основная тема, автор, дата публикации;
Формат. Description должен быть написан на том же языке, что и web-страница. Не стоит злоупотреблять заглавными буквами, спецсимволами, вызывающими лозунгами, знаками препинания.
Актуальность. Мета-описание должно соответствовать актуальной информации на странице. Если вы редактируете содержание странице, поддерживайте в актуальном состоянии и description.
Description — это ваша визитная карточка. При его составлении постарайтесь понять, почему пользователя должен заинтересовать именно ваш контент. Ответив себе, дайте ответ и пользователям.
Есть ли различия в составлении meta description для разных поисковых систем: Яндекс и Google? Давайте попробуем найти отличия в сниппетах и рекомендациях по составлению мета-описаний.
Что такое кодировка сайта
Все виды кодировок на сайтах, в сообщениях электронной почты, файлах и текстах нужны для одной и той же цели – сохранить информацию в привычном для машины, двоичном представлении.
Представьте, что у вас есть друг, который из всех символов понимает только ноль и единицу. Он с детства не знает ни букв, ни других цифр, и может читать сообщения, состоящие исключительно из сочетаний этих двух символов. Как с ним общаться, как говорить ему слова, как понимать его ответы – типичные вопросы, которые бы возникли у вас в начале общения. Решение следующее: составьте таблицу, по которой каждая буква, символ, цифра или знак препинания будут означать какую-то последовательность из нулей и единиц. Начните общаться с вашим другом по этому правилу, шифруйте все свои слова в двоичный вид и расшифровывайте его ответы.
А что, если таких человек в мире несколько десятков? Каждый имеет своих друзей, и каждый придумал собственную таблицу перевода букв в цифры. Если они встретятся друг с другом, никто ничего не поймёт, все они используют разные табличные языки общения. У одного буква «А» значит — 000101, а у другого этому коду соответствует вопросительный знак. Возникнет страшная путаница, каждый подумает, что его собеседник ошибся или не умеет говорить.
Вернёмся в реальность. Наши необычные друзья – это компьютеры. А их выдуманные языки с таблицами – те самые кодировки.
Стандарт кодирования UTF-8
Стандарт закреплен в RFC (Request For Comments) 3629. Алгоритм кодирования согласно RFC:
xxxxxxx
110xxxxx 10xxxxxx
1110xxxx 10xxxxxx 10xxxxxx
11110xx 10xxxxxx 10xxxxxx 10xxxxxx
Старший бит слева. Началом кода является управляющий символ (выделен жирным):
– используется 8-битная кодировка,
110 – используется 16-битная кодировка,
1110 – используется 24-битная кодировка,
11110 – используется 32 битная кодировка.
В начале каждого последующего байта – биты 10 – управляющий символ (выделен подчеркиванием), означающий продолжение кодирования.
Первые 128 ячеек таблицы Юникод повторяют таблицу ASCII. Для кодирования заглавных и строчных букв русского алфавита используются ячейки с номерами 1040-1103.
Рассмотрим пример кодирования фразы «Папа Hello».
Код в бинарном виде (старший бит справа):
00001011 11111001 (П) 00001011 00001101 (а) 00001011 11111101 (п) 00001011 00001101 (а) 0000010 (пробел) 0001001 (H) 1010011 (e) 0011011 (l) 0011011 (l) 1111011 (o).
Букве П русского алфавита согласно таблицы Юникод соответствует номер 1055, в бинарном представлении 10000011111 – 11 бит. Соответственно данный символ может быть закодирован двумя байтами с использованием префикса 110 – для первого байта и 10 – для второго байта. Английские буквы слова Hello кодируются 1 байтом, а коды совпадают с кодами в таблице ASCII.
Основными преимуществами способа кодирования UTF-8 являются многообразие символов, которые могут быть закодированы, а также возможность кодирования переменным количеством бит, что позволяет сэкономить количество информации, передаваемое в канале связи.
Стандарт кодирования UTF-16
В феврале 2000 года опубликован документ RFC 2781, в котором закреплен стандарт UTF-16, позволяющий кодировать символы таблицы Юникод с помощью 16 или 32 битных значений. Символы с номерами 0-55295 и 57344-65535 кодируются с помощью 16 бит без изменений (без использования префиксов), а остальные символы, номера которых в двоичном представлении формируются количеством бит больше 16, кодируются 32 битами с использованием специального алгоритма. Рассмотрим пример кодирования фразы «Папа Hello».
Код в бинарном виде (старший бит справа):
11111000 00100000 (П) 00001100 001000000 (а) 11111100 00100000 (п) 00001100 001000000 (а) 00000100 00000000 (пробел) 00010010 00000000 (H) 10100110 00000000 (e) 00110110 00000000 (l) 00110110 00000000 (l) 111110110 00000000 (o).
Номера букв русского и английского алфавитов таблицы Юникод передаются без изменений при помощи 16 бит, старшие незначащие биты принимают нулевое значение.
Рассмотрим подробнее алгоритм кодирования символов, номера которых превышают значение 65535. Для примера в качестве символа используем букву древнетюркского алфавита, представленную на рис.2:
Рис.2. Буква древнетюркского алфавита.
Номер предложенного символа в таблице Юникод – 68620 (0х10COC).
Алгоритм преобразования номера символа в код UTF-16 состоит из нескольких шагов:
-
Из значения номера символа вычесть число 0х10000. Данная операция позволяет привести размерность бинарного представления номера символа к 20 битам. Для предложенного символа получим: 0х10COC – 0x10000 = 0xC0C.
-
Для полученного значения выделить старшие 10 бит и младшие 10 бит. В примере число 0хС0С в бинарном виде представляется, как 00000000110000001100, где жирным выделены 10 старших бит, а подчеркиванием – 10 младших.
-
К шестнадцатеричному значению 0xD800 (11011000 00000000) прибавить значение 0х03 (00000000 00000011), сформированное 10 старшими битами, полученными на предыдущем шаге. 0xD800 + 0х03 = 0хD803 (11011000 00000011) – 16 старших бит кодового слова UTF-16.
-
К шестнадцатеричному значению 0xDC00 (11011000 00000000) прибавить значение 0х0C (00000000 00001100), сформированное 10 младшими битами, полученными на шаге №2. 0xDС00 + 0х0С = DС0С (11011100 00001100) – 16 младших бит кодового слова UTF-16.
-
Кодовое слово UTF-16, соответствующее символу в примере, формируется из бит, полученных на шагах 3 и 4: 0хD803DC0C (11011000 00000011 11011100 00001100).
Модуль ngx_http_charset_module
Модуль добавляет указанную
кодировку в поле “Content-Type” заголовка ответа.
Кроме того, модуль может перекодировать данные из одной кодировки в другую
с некоторыми ограничениями:
- перекодирование осуществляется только в одну сторону — от сервера к клиенту,
- перекодироваться могут только однобайтные кодировки
- или однобайтные кодировки в UTF-8 и обратно.
| Синтаксис: | |
|---|---|
| Умолчание: |
charset off; |
| Контекст: | , , , |
Добавляет указанную кодировку в поле “Content-Type”
заголовка ответа.
Если эта кодировка отличается от указанной в директиве
, то выполняется перекодирование.
Параметр отменяет добавление кодировки
в поле “Content-Type” заголовка ответа.
Кодировка может быть задана с помощью переменной:
В этом случае необходимо, чтобы все возможные значения переменной
присутствовали хотя бы один раз в любом месте конфигурации в виде
директив , или
.
Для кодировок ,
и для этого достаточно включить в конфигурацию
файлы , и
.
Для других кодировок можно просто сделать фиктивную таблицу перекодировки,
например:
Кроме того, кодировка может быть задана в поле “X-Accel-Charset”
заголовка ответа.
Эту возможность можно запретить с помощью директив
,
,
,
и
.
| Синтаксис: | |
|---|---|
| Умолчание: |
— |
| Контекст: |
Описывает таблицу перекодирования из одной кодировки в другую.
Таблица для обратного перекодирования строится на основании тех же данных.
Коды символов задаются в шестнадцатеричном виде.
Неописанные символы в пределах 80-FF заменяются на “”.
При перекодировании из UTF-8 символы, отсутствующие в однобайтной кодировке,
заменяются на “”.
Пример:
При описании таблицы перекодирования в UTF-8, коды кодировки UTF-8 должны
быть указаны во второй колонке, например:
Полные таблицы преобразования из в
и из и
в
входят в дистрибутив и находятся в файлах ,
и .
| Синтаксис: | |
|---|---|
| Умолчание: |
charset_types text/html text/xml text/plain text/vnd.wap.wml application/javascript application/rss+xml; |
| Контекст: | , , |
Эта директива появилась в версии 0.7.9.
Разрешает работу модуля в ответах с указанными MIME-типами
в дополнение к “”.
Специальное значение “” соответствует любому MIME-типу
(0.8.29).
| Синтаксис: | |
|---|---|
| Умолчание: |
override_charset off; |
| Контекст: | , , , |
Определяет, выполнять ли перекодирование для ответов,
полученных от проксированного сервера или от FastCGI/uwsgi/SCGI/gRPC-сервера,
если в ответах уже указана кодировка в поле “Content-Type”
заголовка ответа.
Если перекодирование разрешено, то в качестве исходной кодировки
используется кодировка, указанная в полученном ответе.
| Синтаксис: | |
|---|---|
| Умолчание: |
— |
| Контекст: | , , , |
Задаёт исходную кодировку ответа.
Если эта кодировка отличается от указанной в директиве
, то выполняется перекодирование.
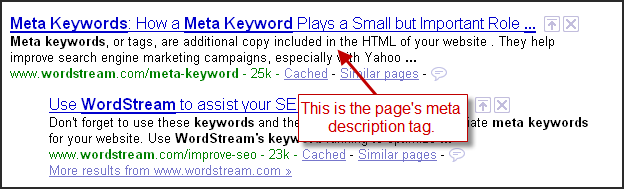
Описание страницы и ключевые слова
Пример:
<meta name=»description» Content=»Производим закупку по выгодным ценам рогов и копыт!»>
Description — краткое описание страницы. Данное описание частенько используется поисковыми системами для вывода в результатах поиска, по какому либо запросу, информации о сайте и его назначении.
Пример:
<meta name=»keywords» Content =»рога, копыта, рожки, рог, копыто, копытце, закупка, покупка, приобретение, выгодно, продать, купить, сбыть, реализовать, корова, бык, коровьи, бычьи, оплата, деньги, наличные, цена, цене»>
Keywords — ключевые слова веб-страницы, опять таки предназначены для поисковых машин.
Представьте что Вы ищете в какой либо поисковой системе сайт с информацией о том где можно продать те же рога и копыта 🙂 Какие слова и фразы Вы будите вводить в строке «Поиск»? ну наверно что то типа: «Где продать коровьи рога?» или «Реализовать копыта по выгодной цене» Так вот если определить ключевые слова и так сказать предугадать мысли потенциального посетителя можно надеяться на то, что та или иная поисковая система выдаст ссылку на Ваш сайт в первых строчках результата поиска. Конечно ввод данного метоописателя не есть гарант того что именно Ваш сайт займет первые места в поиске по данным словам, но всё же не стоит им пренебрегать. Впрочем, оптимизация и раскрутка сайта это отдельная тема для разговора.
Помните что описание description не должно превышать по длине более 200 символов, а ключевые слова keywords 1000 символов, иначе это может пагубно отразится при продвижении Вашего сайта в ТОП поисковых систем.
About
- Character set: Our website uses the UTF-8 character set, so your input data is transmitted in that format. Change this option if you want to convert the data to another character set before encoding. Note that in case of text data, the encoding scheme does not contain the character set, so you may have to specify the appropriate set during the decoding process. As for files, the binary option is the default, which will omit any conversion; this option is required for everything except plain text documents.
- Newline separator: Unix and Windows systems use different line break characters, so prior to encoding either variant will be replaced within your data by the selected option. For the files section, this is partially irrelevant since files already contain the corresponding separators, but you can define which one to use for the «encode each line separately» and «split lines into chunks» functions.
- Encode each line separately: Even newline characters are converted to their Base64 encoded forms. Use this option if you want to encode multiple independent data entries separated with line breaks. (*)
- Split lines into chunks: The encoded data will become a continuous text without any whitespaces, so check this option if you want to break it up into multiple lines. The applied character limit is defined in the MIME (RFC 2045) specification, which states that the encoded lines must be no more than 76 characters long. (*)
- Perform URL-safe encoding: Using standard Base64 in URLs requires encoding of «+», «/» and «=» characters into their percent-encoded form, which makes the string unnecessarily longer. Enable this option to encode into an URL- and filename- friendly Base64 variant (RFC 4648 / Base64URL) where the «+» and «/» characters are respectively replaced by «-» and «_», as well as the padding «=» signs are omitted.
- Live mode: When you turn on this option the entered data is encoded immediately with your browser’s built-in JavaScript functions, without sending any information to our servers. Currently this mode supports only the UTF-8 character set.
(*) These options cannot be enabled simultaneously since the resulting output would not be valid for the majority of applications.Safe and secureCompletely freeDetails of the Base64 encodingDesignExampleMan is distinguished, not only by his reason, but …ManTWFu
| Text content | M | a | n | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| ASCII | 77 | 97 | 110 | |||||||||
| Bit pattern | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 |
| Index | 19 | 22 | 5 | 46 | ||||||||
| Base64-encoded | T | W | F | u |
Атрибуты
| Атрибут | Значение | Описание |
|---|---|---|
| charset | character_set | Задает кодировку символов для HTML документа. |
| content | text | Задает значение, связанное с атрибутами name и http-equiv, в зависимости от контекста. |
| http-equiv | content-security-policycontent-typedefault-stylerefresh | Фактически эквивалентен гипертекстовому заголовку (имитация http-заголовка), формируют заголовок страницы и определяют его обработку. Как правило, они управляют действиями браузеров и используются для формирования информации, выдаваемой обычными http-заголовками. |
| name | application-nameauthordescriptiongeneratorkeywords | Определяет имя документа на уровне метаданных. |
| scheme | format/URI (универсальный идентификатор ресурса) | Не поддерживается в HTML 5. Указывает полезную информацию о схеме или названии самой схемы, которая должна быть использована для уточнения значения свойства атрибута content. |
Настройка области просмотра
Обращаю Ваше внимание на то, что область просмотра определяет, как веб-страница отображается на мобильном устройстве,
если она не задана, то ширина страницы считается равной стандартному значению, и она уменьшается на мобильном устройстве, чтобы поместиться на его экране. Для того, чтобы мобильные браузеры автоматически не изменяли размер страниц сайта, необходимо
в теге разместить метатег, который сообщает браузеру, как обрабатывать размеры страницы и изменять ее масштаб:
Для того, чтобы мобильные браузеры автоматически не изменяли размер страниц сайта, необходимо
в теге <head> разместить метатег, который сообщает браузеру, как обрабатывать размеры страницы и изменять ее масштаб:
<meta name = "viewport" content = "width=device-width, initial-scale = 1">
- Атрибут name задает имя документа метаданным, значение «viewport» дает подсказку браузеру о размере начального размера области просмотра. Функция атрибута content задать значения для этого атрибута.
- Значение width=device-width атрибута content сообщает, что ширина страницы устанавливается в соответствии с размером экрана устройства в аппаратно-независимых пикселях (device-independent pixel, dip), что позволяет странице пересчитывать положение элементов для корректного отображения на различных экранах. По аналогии допускается указать значения для высоты height=device-height.
- Значение initial-scale=1 атрибута content сообщает браузеру, что необходимо установить соответствие 1:1 для пикселей CSS и аппаратно-независимых пикселей вне зависимости от ориентации устройства (альбомной или портретной).
Если все страницы Вашего сайта адаптированы для просмотра на мобильных устройствах, то размещение вышеуказанного мета тега является обязательным.
Доступные значения:
| Значение атрибута | Определение |
|---|---|
| width | Определяет ширину в пикселях области просмотра (значение — положительное целое число или device-width). |
| height | Определяет высоту в пикселях области просмотра (значение — положительное целое число или device-height). |
| initial-scale | Определяет соотношение между шириной устройства (device-width в портретном режиме или device-height в ландшафтном режиме) и размером области просмотра. Чем больше число, тем выше масштаб. Значение — положительное целое число от 0.0 до 10.0. |
| minimum-scale | Определяет минимальное значение zoom (оно должно быть меньше или равно maximum-scale). Значение — положительное целое число от 0.0 до 10.0. |
| maximum-scale | Определяет максимальное значение zoom (оно должно быть больше или равно minimum-scale). Значение — положительное целое число от 0.0 до 10.0. |
| user-scalable | Логическое значение, которое определяет, может ли пользователь увеличить масштаб веб-страницы. Значение по умолчанию yes (пользователь может увеличивать масштаб). |
Как установить кодировку сайта
Вы открыли сайт, но вместо текста видите непонятные закорючки, иностранные символы или цифры. Чтобы привести страницу к обычному виду, нужно вручную задать используемую кодировку.
- Mozilla Firefox
- Заходим в меню – три горизонтальные полосы справа.
- Выбираем категорию «Еще».
- Далее раздел «Кодировка текста».
- Выбираем необходимую опцию.
Opera
- Заходим настройки.
- Выбираем «Веб-сайты».
- Переходим в блок «Отображение».
- Далее – «Настроить шрифты».
- В конце выбираете кодировку.
Google Chrome
- Перейдите в меню – три точки справа вверху.
- Выберите пункт «Дополнительные инструменты».
- Откройте раздел «Кодировка».
- Откроется окно с выбором различных кодировок.
UTF-8 против UTF-16
Как я уже упоминал, UTF-8 – не единственный метод кодирования символов Unicode – существует также UTF-16. Эти методы различаются количеством байтов, необходимых для хранения символа. UTF-8 кодирует символ в двоичную строку из одного, двух, трех или четырех байтов. UTF-16 кодирует символ Unicode в строку из двух или четырех байтов.
Это различие видно из их названий. В UTF-8 наименьшее двоичное представление символа составляет один байт или восемь битов. В UTF-16 наименьшее двоичное представление символа составляет два байта или шестнадцать бит.
И UTF-8, и UTF-16 могут переводить символы Unicode в двоичные файлы, удобные для компьютера, и обратно. Однако они несовместимы друг с другом. Эти системы используют разные алгоритмы для сопоставления кодовых точек с двоичными строками, поэтому двоичный вывод для любого заданного символа будет отличаться от обоих методов:
| символ | Двоичная кодировка UTF-8 | Двоичная кодировка UTF-16 |
| А | 01000001 | 01000001 11011000 00001110 11011111 |
| 𠜎 | 11110000 10100000 10011100 10001110 | 01000001 11011000 00001110 11011111 |
Кодировка UTF-8 предпочтительнее UTF-16 на большинстве веб-сайтов, потому что она использует меньше памяти. Напомним, что UTF-8 кодирует каждый символ ASCII всего одним байтом. UTF-16 должен кодировать эти же символы в двух или четырех байтах. Это означает, что текстовый файл на английском языке с кодировкой UTF-16 будет как минимум вдвое больше размера того же файла с кодировкой UTF-8.
UTF-16 более эффективен, чем UTF-8, только на некоторых неанглоязычных сайтах. Если веб-сайт использует язык с символами, находящимися дальше в библиотеке Unicode, UTF-8 будет кодировать все символы как четыре байта, тогда как UTF-16 может кодировать многие из тех же символов только как два байта. Тем не менее, если ваши страницы заполнены буквами ABC и 123, придерживайтесь UTF-8.
Расшифровка мира кодировки UTF-8
Это было много слов о словах, поэтому давайте резюмируем то, что мы рассмотрели:
- Компьютеры хранят данные, включая текстовые символы, как двоичные (единицы и нули).
- ASCII был ранним способом кодирования или отображения символов в двоичный код, чтобы компьютеры могли их хранить. Однако в ASCII не было достаточно места для представления нелатинских символов и чисел в двоичном формате.
- Юникод был решением этой проблемы. Юникод присваивает уникальный «код» каждому символу на каждом человеческом языке.
- UTF-8 – это метод кодировки символов Unicode. Это означает, что UTF-8 берет кодовую точку для данного символа Юникода и переводит ее в строку двоичного кода. Он также делает обратное, считывая двоичные цифры и преобразуя их обратно в символы.
- UTF-8 в настоящее время является самым популярным методом кодирования в Интернете, поскольку он может эффективно хранить текст, содержащий любой символ.
- UTF-16 – еще один метод кодирования, но он менее эффективен для хранения текстовых файлов (за исключением тех, которые написаны на некоторых неанглийских языках).
Перевод Unicode – это не то, о чем большинству из нас нужно думать при просмотре или разработке веб-сайтов, и именно в этом суть – создать бесшовную систему обработки текста, которая работает для всех языков и веб-браузеров. Если он работает хорошо, вы этого не заметите.
Но если вы обнаружите, что страницы вашего веб-сайта занимают чрезмерно много места или если ваш текст завален буквами and и, пора применить ваши новые знания о UTF-8.
Источник записи: https://blog.hubspot.com
Что такое кодирование Base64?
Прежде чем перейти к этому, давайте определим, что мы подразумеваем под Base64.
Base64 – это способ, с помощью которого 8-битные двоичные данные кодируются в формат, который можно представить в 7 битах. Для этого используются только символы A-Z, a-z, 0-9, + и / для представления данных. Символ = используется для данных прокладок. Например, при таком кодировании три 8-битных байта превращаются в четыре 7-битных байта.
Термин base 64 происходит от стандарта Multipurpose Internet Mail Extensions (MIME), который широко используется для HTTP и XML, и изначально был разработан для кодирования вложений электронной почты и их правильной передачи.