Как закрыть сайт wordpress от индексации поисковиков, урок 76
Содержание:
- Пять причин для запрета индексации!
- Рекомендации
- Как правильно настроить robots.txt?
- Что такое файл robots.txt
- Что такое мета-тег Robots и как его использовать?
- Создаем robots самостоятельно
- Контент
- Директивы robots.txt и правила настройки
- Зачем необходимо закрывать внешние ссылки от индексации
- Как узнать сколько страниц в дополнительном индексе?
- Заключение: советы Вебмастерам
Пять причин для запрета индексации!
- Полное индексирование создаёт лишнюю нагрузку на ваш сервер.
- Отнимает драгоценное время самого робота.
- Пожалуй это самое главное, некорректная информация может быть неправильно интерпретирована поисковыми системами. Это приведет к неправильному ранжированию статей и страниц, а в последствии и к некорректной выдаче в результатах поиска.
- Папки с шаблонами и плагинами содержат огромное количество ссылок на сайты создателей и рекламодателей. Это очень плохо для молодого сайта, когда на ваш сайт ссылок из вне еще нет или очень мало.
- Индексируя все копии ваших статей в архивах и комментариях, у поисковика складывается плохое мнение о вашем сайте. Много дублей. Много исходящих ссылок Поисковая машина будет понижать ваш сайт в результатах поиска в плоть до фильтра. А картинки, оформленные в виде отдельной статьи с названием и без текста, приводят робота просто в ужас. Если их очень много, то сайт может загреметь под фильтр АГС Яндекса. Мой сайт там был. Проверено!
Теперь после всего сказанного возникает резонный вопрос: «А можно ли как то запретить индексировать то что не надо?». Оказывается можно. Хотя бы не в приказном порядке, а в рекомендательном. Ситуация не полного запрета индексации некоторых объектов возникает из-за файла sitemap.xml, который обрабатывается после robots.txt. Получается так: robots.txt запрещает, а sitemap.xml разрешает. И всё же решить эту задачу мы можем. Как это сделать правильно сейчас и рассмотрим.
Файл robots.txt для wordpress по умолчанию динамический и реально в wordpress не существует. А генерируется только в тот момент, когда его кто-то запрашивает, будь это робот или просто посетитель. То есть если через FTP соединение вы зайдете на сайт, то в корневой папке файла robots.txt для wordpress вы там просто не найдете. А если в браузере укажите его конкретный адрес http://название_вашего_сайта/robots.txt, то на экране получите его содержимое, как будто файл существует. Содержимое этого сгенерированного файла robots.txt для wordpress будет такое:
User-agent: *
В правилах составления файла robots.txt по умолчанию разрешено индексировать всё. Директива User-agent: * указывает на то, что все последующие команды относятся ко всем поисковым агентам ( * ). Но далее ничего не ограничивается. И как вы понимаете этого не достаточно. Мы с вами уже обсудили папок и записей, имеющих ограниченный доступ, достаточно много.
Чтобы можно было внести изменения в файл robots.txt и они там сохранились, его нужно создать в статичном постоянном виде.
Рекомендации
Не рекомендуется исключать фиды:
Потому что наличие открытых фидов требуется, например, для Яндекс Дзен, когда нужно подключить сайт к каналу (спасибо комментатору «Цифровой»). Возможно открытые фиды нужны где-то еще.
Фиды имеют свой формат в заголовках ответа, благодаря которому поисковики понимают что это не HTML страница, а фид и, очевидно, обрабатывают его иначе.
-
Прописывание Sitemap после каждого User-agent
Это делать не нужно. Один sitemap должен быть указан один раз в любом месте файла robots.txt. -
Закрыть папки wp-content, wp-includes, cache, plugins, themes
Это устаревшие требования. Однако подобные советы я находил даже в статье с пафосным названием «Самые правильный robots для WordPress 2018»! Для Яндекса и Google лучше будет их вообще не закрывать. Или закрывать «по умному», как это описано выше. -
Закрывать страницы тегов и категорий
Если ваш сайт действительно имеет такую структуру, что на этих страницах контент дублируется и в них нет особой ценности, то лучше закрыть. Однако нередко продвижение ресурса осуществляется в том числе за счет страниц категорий и тегирования. В этом случае можно потерять часть трафика -
Прописать Crawl-Delay
Модное правило. Однако его нужно указывать только тогда, когда действительно есть необходимость ограничить посещение роботами вашего сайта. Если сайт небольшой и посещения не создают значительной нагрузки на сервер, то ограничивать время «чтобы было» будет не самой разумной затеей. -
Ляпы
Некоторые правила я могу отнести только к категории «блогер не подумал». Например: Disallow: /20 — по такому правилу не только закроете все архивы, но и заодно все статьи о 20 способах или 200 советах, как сделать мир лучше
-
Закрывать от индексации страницы пагинации
Это делать не нужно. Для таких страниц настраивается тег , таким образом, такие страницы тоже посещаются роботом и на них учитываются расположенные товары/статьи, а также учитывается внутренняя ссылочная масса. -
Комментарии
Некоторые ребята советуют закрывать от индексирования комментарии и . -
Открыть папку uploads только для Googlebot-Image и YandexImages
User-agent: Googlebot-Image Allow: /wp-content/uploads/ User-agent: YandexImages Allow: /wp-content/uploads/
Совет достаточно сомнительный, т.к. для ранжирования страницы необходима информация о том, какие изображения и файлы на ней размещены.
Как правильно настроить robots.txt?
С синтаксисом robots.txt мы разобрались выше, поэтому сейчас напишем как правильно настроить данный файл. Если для популярных CMS, таких как WordPress и Joomla!, уже есть готовые robots, то для самописного движка или редкой СУ Вам придется все настраивать вручную.
(Даже несмотря на наличие готовых robots.txt редактировать и удалять «уникальный мусор» Вам придется и в ВордПресс. Поэтому этот раздел будет полезен и для владельцев сайтов на ТОПовых CMS)
Что нужно исключать из индекса?
А.) В первую очередь из индекса исключаются дубликаты страниц в любом виде. Страница на сайте должна быть доступна только по одному адресу. То есть, при обращении к ресурсу робот должен получать по каждому URL уникальный контент.
Зачастую дубликаты появляются у систем управления сайтом при создании страниц. К примеру, одна и та же страница может быть доступна по техническому адресу /?p=391&preview=true и одновременно с этим иметь ЧПУ. Так же дубли могут возникать при работе с динамическими ссылками.
Всех их необходимо при помощи масок исключать из индекса.
Disallow: /*?* Disallow: /*% Disallow: /index.php Disallow: /*?page= Disallow: /*&page=
Б.) Все страницы, которые имеют не уникальный контент, желательно убрать из индекса еще до того, как это сделает поисковая система.
В.) Из индекса должны быть исключены все страницы, которые используются при работе сценариев. К примеру, страница «Спасибо, сообщение отправлено!».
Г.) Желательно исключить все страницы, которые имеют индикаторы сессий
Disallow: *PHPSESSID= Disallow: *session_id=
Д.) В обязательном порядке из индекса должны быть исключены все файлы вашей cms. Это файлы панели администрации, различных баз, тем, шаблонов и т.д.
Disallow: /wp-admin Disallow: /wp-includes Disallow: /wp-content/plugins Disallow: /wp-content/cache Disallow: /wp-content/themes Disallow: /trackback
Е.) Пустые страницы и разделы, «не нужный» пользователям контент, результаты поиска и работы калькулятора так же должны быть недоступны роботу.
«Держа в чистоте» Ваш индекс Вы упрощаете жизнь и себе и индексирующему роботу.
Что нужно разрешать индексировать?
Да по сути все, что не запрещено. Есть только один нюанс. Поисковые системы по умолчанию индексируют любой полезный контент Вашего сайта, поэтому использовать директиву Allow в 90% случаев не нужно.
Корректный файл sitemap.xml и качественная перелинковка дадут гарантию, что все «нужные» страницы Вашего сайта будут проиндексированы.
Обязательны ли директивы host и sitemap?
Да, данные директивы обязательны. Прописать их не составит труда, но они гарантируют, что робот точно найдет sitemap.xml, и будет «знать» главное зеркало сайта.
Для каких поисковиков настраивать?
Инструкции файла robots.txt понимают все популярные поисковые системы. Если различий в инструкциях нету, то Вы можете прописать User-agent: * (Все директивы для всех поисковиков).
Однако, если Вы укажите инструкции для конкретного робота, к примеру Yandex, то все другие директивы Яндексом будут проигнорированы.
Нужны ли мне директивы Crawl-delay и Clean-param?
Если Вы используете динамические ссылки или же передаете параметры в URL, то Вам скорее всего понадобиться Clean-param, дабы не вводить робота в заблуждение. мы описали выше
Данная директива поможет Вам избежать ненужных дубликатов в поиске, что очень важно
зависит исключительно от Вашего хостинга. Если Вы чувствуете, что сервер уже не справляется запросами, то желательно увеличить время межу ними.
Что такое файл robots.txt
Если robots.txt найден, то прочитывает все директивы, а в конце видит адрес файла sitemap.xml. Дальше робот, в соответствии с картой сайта, обходит все материалы предоставленные для индексации. Делает он это в пределах какого-то ограниченного промежутка времени. Именно поэтому, если вы создали сайт на несколько тысяч страниц и выложили его целиком, то робот просто не успеет обойти все страницы за один заход. И в индекс попадут только те, которые он успел просмотреть. А ходит робот по всему сайту и тратит на это свое время. И не факт что в первую очередь он будет просматривать именно те странички, которые вы так ждёте в результатах поиска.
Если робот файл robots.txt не находит, то считает, что индексировать разрешено всё. И начинает шарить по всем закаулкам. Сделав полную копию всего, что ему удалось найти, он покидает ваш сайт, до следующего раза. Как вы понимаете, после такого обшаривания в базу индекса поисковика попадает всё, что надо и всё, что не надо. То что надо вы знаете — это ваши статьи, страницы, картинки, ролики и т.д. А вот чего индексировать не надо?
Для WordPress это оказывается очень важный вопрос. Ответ на него затрагивает и ускорение индексации содержимого вашего сайта, и его безопасность. Дело в том, что всю служебную информацию индексировать не надо. А файлы WordPress вообще желательно спрятать от чужих глаз. Это уменьшит вероятность взлома вашего сайта.
WordPress создаёт очень много копий ваших статей с разными адресами, но одним и тем же содержанием. Выглядит это так:
//название_сайта/название_статьи,
//название_сайта/название_рубрики/название_статьи,
//название_сайта/название_рубрики/название_подрубрики/название_статьи,
//название_сайта/название_тега/название_статьи,
//название_сайта/дата_создания_архива/название_статьи
С тегами и архивами вообще караул. К скольким тегам привязана статья, столько копий и создаётся. При редактировании статьи, сколько архивов в разные даты будет создано, столько и новых адресов с практически похожим содержанием появится. А есть ещё копии статей с адресами для каждого комментария. Это вообще просто ужас.
Огромное количество дублей поисковые системы оценивают как плохой сайт. Если все эти копии проиндексировать и предоставить в поиске то вес главной статьи размажется на все копии, что очень плохо. И не факт, что будет показана в результате поиска именно статья с главным адресом. Следовательно надо запретить индексирование всех копий.
WordPress оформляет картинки как отдельные статьи без текста. В таком виде без текста и описания они как статьи выглядят абсолютно некорректно. Следовательно нужно принять меры чтобы эти адреса не попали в индекс поисковиков.
Почему же не надо всё это индексировать?
Что такое мета-тег Robots и как его использовать?
Это один из многочисленных тегов, используемых для сообщения роботам и/или браузерам т.н. метаданных (т.е. информации об информации). Среди самых известных и часто используемых:
- .
- .
Что прописывать в тег robots?
Выглядит он так:
Вместо многоточия может быть 7 основных вариантов. Каждый вариант — это комбинации специальных указаний index/noindex и follow/nofollow, а также archive/noarchive:
- index, follow. Это сообщает поисковикам о том, что нужно произвести (index), а также следовать (follow) по ссылкам, которые есть на странице.
- all. Аналогично предыдущему пункту.
- noindex,follow или просто noindex. Запрещает индексировать данную страницу, но разрешает роботу переходить по ссылкам, расположенным на ней.
- index,nofollow или просто nofollow. Запрещает переходить по ссылкам, но разрешает индексировать страницу — т.е. содержимое страницы будет отправлено , но другие страницы, на которые стоят ссылки, в индекс не попадут (при условии, что робот иными способами до них не доберётся).
- noindex, nofollow. Указание не индексировать документ и не переходить по ссылкам, содержащимся в нём.
- none. Аналогично предыдущему пункту.
-
noarchive. Данное указание запрещает показывать ссылку на сохранённую копию страницы в результатах выдачи:
Если мета-тег Robots не указан, то принимается значение по умолчанию:
То же самое происходит, если на странице указано несколько этих тегов.
Все вышеперечисленные варианты понимаются большинством поисковых систем и, в частности, Яндексом. Google тоже хорошо распознаёт эти комбинации, но также вводит кое что ещё:
- Вместо name=robots можно указать name=googlebot — «обращение» конкретно к роботу Google.
- content=nosnippet (запрещает показывать ) и content=noodp (запрещает брать содержимое сниппетов из описания сайта в каталоге DMOZ).
- content=noimageindex. При поиске по картинкам запрещает отображение ссылки на источник картинки.
- content=unavailable_after:. В качестве date следует указать дату и время, после которой Гугл перестанет индексировать эту страницу. Едва ли это когда-нибудь пригодится
В общем, Google несколько расширяет содержимое мета-тега Robots.
Куда прописывать meta name robots?
Традиционно, все мета-теги прописываются между «head» и «/head» в HTML-коде страницы.
В WordPress они легко выставляются при помощи популярного плагина All in One Seo Pack:
Мета Robots в All in One Seo Pack
Таким образом, если вам необходимо «спрятать» определённую страницу от поисковых роботов — используйте данный мета-тег.
Случайные публикации:
- Как задать срезы для объявлений РСЯ и зачем это нужно?…ылкой будет показано число 15. Из картинки выше видно, что объявление
- Как найти битые ссылки на сайте — рассматриваем все варианты…закончит сканирование, она предложит вам отчет. ГОВОРИТЕ – НЕТ. Дело в том, что отчет
- Как быстро собрать семантическое ядро с помощью инструментов PromoPultПодбор семантики — это начальный этап SEO. Сгруппированные ключевые фразы служат…
- Составляем правильный description для сайта.Когда пишешь статью на сайт, один из обязательных элементов, это составлен…
-
Что такое чёрное СЕО? Методы black SEO…способы теряют свою силу.
Up от 25 июня 2012 — пришла просто куча видео от
Оставьте комментарий:
Создаем robots самостоятельно
Сам процесс создания файла до безобразия прост. Необходимо просто создать текстовой документ, назвав его «robots». После этого, подключившись через FTP соединение, загрузить в корневую папку Вашего сайта. Обязательно проверьте, что бы роботс был доступен по адресу ваш домен/robots.txt. Не допускается наличие вложений, к примеру ваш домен/page/robots.txt.
Если Вы пользуетесь web ftp — файловым менеджером, который доступен в панели управления у любого хост-провайдера, то файл можно создать прямо там.
В итоге, у нас получается пустой роботс. Все инструкции мы будем вписывать вручную. Как это сделать, мы опишем ниже.
Используем online генераторы
Если создание своими руками это не для Вас, то существует множество online генераторов, которые помогут в этом. Но нужно помнить, что никакой генератор не сможет без Вас исключить из поиска весь «мусор» и не добавит главное зеркало, если Вы не знаете какое оно. Данный вариант подойдет лишь тем, кто не хочет писать рутинные повторяющиеся для большинства сайтов инструкции.
Сгенерированный онлайн роботс нужно будет в любом случае править «руками», поэтому без знаний синтаксиса и основ Вам не обойтись и в этом случае.
Используем готовые шаблоны
В Интернете есть множество шаблонов для распространенных CMS, таких как WordPress, Joomla!, MODx и т.д. От онлайн генераторов они отличаются только тем, что сам текстовой файл Вам нужно будет сделать самостоятельно. Шаблон позволяет не писать большинство стандартных директив, однако он не гарантирует правильную и полную настройку для Вашего ресурса. При использовании шаблонов так же нужны знания.
Контент
Проблемы, связанные с закрытием контента на сайте:
Страница оценивается поисковыми роботами комплексно, а не только по текстовым показателям. Увлекаясь закрытием различных блоков, часто удаляется и важная для оценки полезности и ранжирования информация.
Приведём пример наиболее частых ошибок:
– прячется шапка сайта. В ней обычно размещается контактная информация, ссылки. Если шапка сайта закрыта, поисковики могут не узнать, что вы позаботились о посетителях и поместили важную информацию на видном месте;
Зачем на сайте закрывают часть контента?
Обычно есть несколько целей:
– сделать на странице акцент на основной контент, убрав из индекса вспомогательную информацию, служебные блоки, меню;
– сделать страницу более уникальной, полезной, убрав дублирующиеся на сайте блоки;
– убрать «лишний» текст, повысить текстовую релевантность страницы.
Всего этого можно достичь без того, чтобы прятать часть контента!У вас очень большое меню?
Выводите на страницах только те пункты, которые непосредственно относятся к разделу.
Много возможностей выбора в фильтрах?
Выводите в основном коде только популярные. Подгружайте остальные варианты, только если пользователь нажмёт кнопку «показать всё». Да, здесь используются скрипты, но никакого обмана нет – скрипт срабатывает по требованию пользователя. Найти все пункты поисковик сможет, но при оценке они не получат такое же значение, как основной контент страницы.
На странице большой блок с новостями?
Сократите их количество, выводите только заголовки или просто уберите блок новостей, если пользователи редко переходят по ссылкам в нём или на странице мало основного контента.
Поисковые роботы хоть и далеки от идеала, но постоянно совершенствуются. Уже сейчас Google показывает скрытие скриптов от индексирования как ошибку в панели Google Search Console (вкладка «Заблокированные ресурсы»). Не показывать часть контента роботам действительно может быть полезным, но это не метод оптимизации, а, скорее, временные «костыли», которые стоит использовать только при крайней необходимости.
Мы рекомендуем:
– относиться к скрытию контента, как к «костылю», и прибегать к нему только в крайних ситуациях, стремясь доработать саму страницу;
– удаляя со страницы часть контента, ориентироваться не только на текстовые показатели, но и оценивать удобство и информацию, влияющую на коммерческие факторы ранжирования;
– перед тем как прятать контент, проводить эксперимент на нескольких тестовых страницах. Поисковые боты умеют разбирать страницы и ваши опасения о снижение релевантности могут оказаться напрасными.
Давайте рассмотрим, какие методы используются, чтобы спрятать контент:
Тег noindex
У этого метода есть несколько недостатков. Прежде всего этот тег учитывает только Яндекс, поэтому для скрытия текста от Google он бесполезен
Помимо этого, важно понимать, что тег запрещает индексировать и показывать в поисковой выдаче только текст. На остальной контент, например, ссылки, он не распространяется
Это видно из самого .
Поддержка Яндекса не особо распространяется о том, как работает noindex. Чуть больше информации есть в одном из обсуждений в официальном блоге.
Вопрос пользователя:
Ответ:
В каких случаях может быть полезен тег:
– если есть подозрения, что страница понижена в выдаче Яндекса из-за переоптимизации, но при этом занимает ТОПовые позиции по важным фразам в Google. Нужно понимать, что это быстрое и временное решение. Если весь сайт попал под «Баден-Баден», noindex, как неоднократно подтверждали представители Яндекса, не поможет;
– чтобы скрыть общую служебную информацию, которую вы из-за корпоративных ли юридических нормативов должны указывать на странице;
– для корректировки сниппетов в Яндексе, если в них попадает нежелательный контент.
Скрытие контента с помощью AJAX
Это универсальный метод. Он позволяет спрятать контент и от Яндекса, и от Google. Если хотите почистить страницу от размывающего релевантность контента, лучше использовать именно его. Представители ПС такой метод, конечно, не приветствую и рекомендуют, чтобы поисковые роботы видели тот же контент, что и пользователи.
Технология использования AJAX широко распространена и если не заниматься явным клоакингом, санкции за её использование не грозят. Недостаток метода – вам всё-таки придётся закрывать доступ к скриптам, хотя и Яндекс и Google этого не рекомендуют делать.
Директивы robots.txt и правила настройки
User-agent. Это обращение к конкретному роботу поисковой системы или ко всем роботам. Если прописывается конкретное название робота, например «YandexMedia», то общие директивы user-agent не используются для него. Пример написания:
User-agent: YandexBot Disallow: /cart # будет использоваться только основным индексирующим роботом Яндекса
Disallow/Allow. Это запрет/разрешение индексации конкретного документа или разделу. Порядок написания не имеет значения, но при 2 директивах и одинаковом префиксе приоритет отдается «Allow». Считывает поисковый робот их по длине префикса, от меньшего к большему. Если вам нужно запретить индексацию страницы — просто введи относительный путь до нее (Disallow: /blog/post-1).
User-agent: Yandex Disallow: / Allow: /articles # Запрещаем индексацию сайта, кроме 1 раздела articles
Регулярные выражения с * и $. Звездочка означает любую последовательность символов (в том числе и пустую). Знак доллара означает прерывание. Примеры использования:
Disallow: /page* # запрещает все страницы, конструкции http://site.ru/page Disallow: /arcticles$ # запрещаем только страницу http://site.ru/articles, разрешая страницы http://site.ru/articles/new
Директива Sitemap. Если вы используете карту сайта (sitemap.xml) – то в robots.txt она должна указываться так:
Sitemap: http://site.ru/sitemap.xml
Директива Host. Как вам известно у сайтов есть зеркала (читаем, Как склеить зеркала сайта). Данное правило указывает поисковому боту на главное зеркало вашего ресурса. Относится к Яндексу. Если у вас зеркало без WWW, то пишем:
Host: site.ru
Crawl-delay. Задает задержу (в секундах) между скачками ботом ваших документов. Прописывается после директив Disallow/Allow.
Crawl-delay: 5 # таймаут в 5 секунд
Clean-param. Указывает поисковому боту, что не нужно скачивать дополнительно дублирующую информацию (идентификаторы сессий, рефереров, пользователей). Прописывать Clean-param следует для динамических страниц:
Clean-param: ref /category/books # указываем, что наша страница основная, а http://site.ru/category/books?ref=yandex.ru&id=1 это та же страница, но с параметрами
Главное правило: robots.txt должен быть написан в нижнем регистре и лежать в корне сайта. Пример структуры файла:
User-agent: Yandex Disallow: /cart Allow: /cart/images Sitemap: http://site.ru/sitemap.xml Host: site.ru Crawl-delay: 2
Зачем необходимо закрывать внешние ссылки от индексации
Опытные вебмастера всегда закрывают внешние или ненужные ссылки на своих блогах. Для чего они так делают? Все дело как раз заключается в том, что любая веб страница имеет определенный вес.
Однако, вес страницы перераспределяется при простановке в ней различных ссылок.
Если на первой странице проставлена анкор ссылка на вторую страницу, то часть веса отдается второй странице
И не важно, внешняя это ссылка или внутренняя
Чтобы было понятнее, поясню на примере. Предположим, что первая страница имеет вес равный 10 баллов. После постановки ссылки на вторую страницу, вес каждой страницы будет равняться по 5 баллов.
Тем самым получается, что чем больше ссылок на определенную страницу, тем больше ее вес.
Поэтому наша задача в основном заключается в том, чтобы не отдавать вес со своих страниц другим блогам, а удерживать внутри своего.
Мой пример с баллами является приближённым. На самом деле, вес самой ссылки зависит от многих факторов, в числе которых релевантность, ключевые слова, удаленность от начала страницы и других.
Если Вы хотите быстро продвинуть какую-либо страницу, то необходимо будет ссылаться на нее с других страниц. В этом как раз и заключается один из элементов грамотной внутренней перелинковки страниц блога.
Учесть также нужно и то, что чем больше ссылок Вы поставите на странице, тем меньше веса останется на этой странице!
Кроме того, большое количество ссылок плохо тем, что страницы, на которые ссылается эта, также получат ничтожные веса.
Если Вы хотите в будущем зарабатывать на продаже постовых, то учтите, что заказчики, как правило, предъявляют особые требования к страницам размещения.
Одним из этих требований является ограниченное количество внешних ссылок на странице с постовым. Обычно это не более 3-5 внешних ссылок.
Надеюсь, я убедил Вас в том, что закрыть внешние ссылки от индексации нужно в срочном порядке. Приступим к выполнению задуманного.
Как узнать сколько страниц в дополнительном индексе?
Тут все относительно просто. Покажу на примере моего блога. Запрос в гугле
Покажет сколько страниц в основном индексе, сейчас их «About 558 results».
Запрос без знаков «/&», покажет сколько страниц всего в индексе:
Сейчас у меня в индексе всего «About 1,660 results». Выходит у меня 1660-558=1102 страниц в дополнительном индексе. В основном индексе у меня 34% страниц. Честно говоря, это не такой уж и плохой результат. Если же у вас более 50% страниц в основном индексе, то это уже считается хорошим достижением.
Следующий вопрос конечно будет «А как мне посмотреть какие именно страницы в дополнительном индексе?». Тут уже не все так просто, раньше это можно было выяснить с помощью такого запроса:
То есть показать все страницы в индексе, за исключением страниц из основного индекса. Но сейчас такой запрос не работает.
Я догадался выйти из ситуации другим методом. Разобьем сайт на части и проверим в какой из этих частей больше всего страниц в сопливом индексе. Например если вы увлекаетесь тегами, то таких страниц в сопливом индексе должно быть достаточно много, так как там дублирующийся контент, а если еще страница с тегом указывает только на одну-две статьи, то этого контента раз-два и обчелся. Под страницей с тегами подразумеваю страницы с такими адресами: elims.org.ua/blog/tag/span/
Итак, запрос «site:elims.org.ua inurl:/blog/tag/» показал 254 результата, а запрос «site:elims.org.ua/& inurl:/blog/tag/» — 3 результата. Выходит 251 страница с тегами основного подблога «/blog/» находится в сопливом индексе. Теперь я знаю над чем можно поработать. По аналогии можно проинспектировать остальные части сайта.
Заключение: советы Вебмастерам
Совет #1
Если ваш сайт не индексируется поисковыми системами, или его страницы начали массово пропадать из поисковой выдачи, первым делом необходимо проверить файл robots.txt на предмет запрета индексации сайта. При необходимости снимите запрет на полезные страницы, которые должны участвовать в выдаче.
Если файл robots.txt не запрещает индексирование сайта, проверьте содержимое мета-тегов в head вашего сайта, адресованных поисковым роботам
Обратите внимание на наличие на вашем сайте следующих тегов:
<meta name="robots" content="noindex"/> — запрещает индексировать содержимое страницы <meta name="robots" content="nofollow"/> — запрещает переходить по ссылкам на странице <meta name="robots" content="none"/> — запрещает переходить по ссылкам и индексировать содержимое страницы <meta name="robots" content="noindex, nofollow"/> — аналогичен предыдущему тегу
Наличие данных тегов может негативно повлиять на представление вашего сайта в поисковых системах.
Совет #2
Хотя бы 1 раз в 2-3 недели заглядывайте в Яндекс Вебмастер в разделы «Индексирование — Статистика обхода» и «Индексирование — Страницы в поиске». Отслеживайте страницы, которые обходит поисковый робот на вашем сайте.
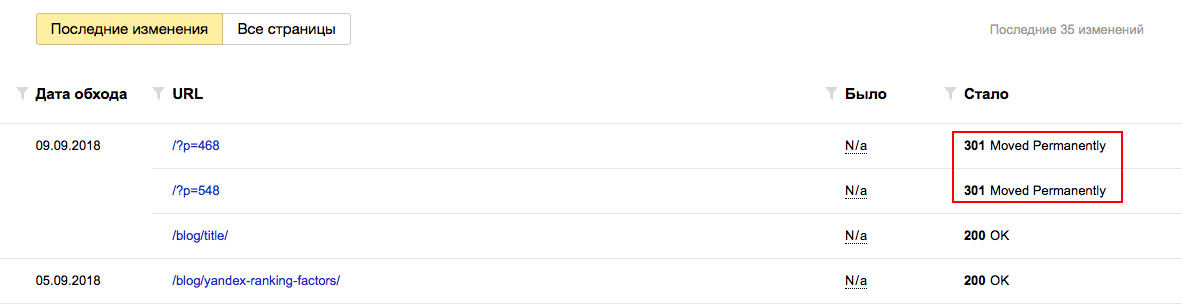
Если робот обходит технические страницы, или страницы, которые отвечают редиректом, их следуют запретить директивой Disallow в robots.txt. Таким образом вы сузите объем страниц, который необходимо обойти поисковому роботу и повысите эффективность индексации своего сайта.

Аналогична ситуация с разделом «Страницы в поиске». С его помощью вы можете не только отследить документы, которые больше не участвуют в поиске, но и проверить свой сайт на предмет наличия поискового спама. Если в данном разделе вы также найдете технические страниц, либо сервисные страницы с параметрами, которые не должны принимать участие в ранжировании, добавьте запрет на их обход в robots.txt.
Заключение
Файл robots.txt является одним из важнейших инструментов SEO-оптимизации. Через него можно напрямую влиять на индексирование абсолютно любых страниц и разделов сайта. Грамотно составленный robots.txt поможет вам сэкономить место в ограниченном краулинговом бюджете, избавит поисковые роботы от переобхода сотен ненужных технических страниц, избавит выдачу от поискового спама, а ваш сервер от излишней нагрузки. Создавайте robots.txt с умом!