15 best wayback machine alternatives 2021
Содержание:
- Introduction
- Как проверять полученные статьи на уникальность
- eval(ez_write_tag([[728,90],’gadget_info_com-medrectangle-3′,’ezslot_4′,118,’0′,’0′]));1. Скриншоты
- Инструкция по ручному удалению рекламного вируса WAYBACK MACHINE
- Origins, growth and storage
- Как скачать все изменения страницы из веб-архива
- Инструкция по получению уникальных статей с вебархива
- Screenshots
- archive.md
- Принцип работы веб-архива
- Which Sites Are Cataloged?
- Archive-It
- r-tools.org
- Archive.is
- Method 2: using FTP
Introduction
wayback is an open source java implementation of the
The Internet Archive
Wayback Machine.
The current production version of the Wayback Machine is implemented in
perl, and lacks in maintainability and extensibility. Also, the code is
not open source. Primary motivation for the new version is to address
these three issues, enabling public distribution of the application, and
easy experimentation with new features and access technologies.
The current Java version of the Wayback Machine supports three access,
or Replay modes of operation: «Archival Url» mode «Proxy» mode, and
«Domain Prefix» mode.
Archival URL mode provides a user experience very close to the current
production Wayback Machine. All query and replay access requests can be
expressed as URLs. In Archival Url replay mode, archived content is
modified as it is returned to users, attempting to make links and
embedded content refer back to the Wayback Machine by rewriting them as
Archival URLs.
Proxy URL mode allows replaying of archived documents within a client
browser by configuring the browser to proxy all HTTP requests through
the Wayback Machine. This has the strong advantage that no Javascript
or server side page markup is required to coerce the client browser to
request additional URLs and embedded content from the Wayback Machine
— content just works as-is. When used with the Firefox plugin
extension, available
here
, client browsers can navigate between versions of the current
document, and the Wayback Machine server will attempt to display images
from the same time period as pages being viewed. The Proxy URL mode
requires special configuration of the client web browser to access the
Wayback Service. This browser configuration is not complex, but it
means that content cannot be accessed as a global URL.
DomainPrefix mode is similar to ArchivalUrl mode, but uses a wildcard
DNS scheme to rewrite URLs, allowing all URL substitution to occur on
the server. This mode is considered experimental.
See the Administrator Manual
to learn more about access modes.
The current Java version can operate in several deployment modes,
ranging from a stand alone application on a single host holding all
archived documents and indexes, up to a highly distributed system where
indexes and archived content is spread across hundreds of machines.
Как проверять полученные статьи на уникальность
Есть несколько способов проверки статей на уникальность и наверное многие из них вам известны. Тем не мене здесь мы приведем лучшие способы проверки контента на уникальность.
- Проверка статей с использованием специализированных сервисов типа etxt.ru, text.ru или адвего. Данный способ подходит когда нужно проверить одну или две статьи, так как проверка занимает длительное время и существуют ограничения по количеству проверок в день с конкретного IP адреса.
- Если вам не жалко немного денег, то для ускорения процесса можно использовать пакетную проверку статей предоставляемую такими сервисами.
- Использовать специализированное программное обеспечение для проверки уникальности статей типа Advego Plagiatus.
Программа для проверки уникальности статей из Вебархива
После чего открываем программу и загружаем наши статьи для пакетной проверки используйте меню программы: «Операции -> Пакетная проверка».
Настройка программы для проверки уникальных статей из вебархива
Если у вас отсутствует необходимость проверять много статей, то просто включите отображение каптчи и вводите ее вручную.
На этом пожалуй все. Мы рассмотрели как можно получить множество уникальных статей абсолютно бесплатно. Желаем вам удачи !
Ссылки используемые в статье
- 1. web.archive.org – интернет архив веб сайтов
- 2. Web Arhcive Downloder – это уникальная программа для сохранения сайтов из интернет архива.
eval(ez_write_tag([[728,90],’gadget_info_com-medrectangle-3′,’ezslot_4′,118,’0′,’0′]));1. Скриншоты
Скриншоты могут стать хорошей альтернативой Wayback Machine, если вы хотите увидеть, как в действительности выглядел сайт в прошлом. Веб-сайты архивирования в Интернете, включая Wayback Machine, копируют код веб-страницы и сохраняют его для дальнейшего использования. Однако Screenshots просто делает снимок веб-страницы, а затем архивирует его.
Как это устроено
Снимки экрана используют базу данных WHOIS DomainTools для поиска веб-сайтов для архивирования, а затем используют снимки для их записи. Время и частота создания снимков для определенного веб-сайта зависит от того, сколько раз он обновлялся новым контентом.
Если веб-сайт часто обновляется с большими изменениями, он также будет архивироваться чаще, и вы найдете больше его снимков в истории снимков экрана. Тем не менее, если веб-сайт не обновляется часто или в дизайне сайта не так много изменений, следует ожидать меньше снимков.
На данный момент Screenshots удалось собрать более 250 миллионов снимков, что на самом деле ничто по сравнению с 436 миллиардами страниц, собранных Wayback Machine. Однако, по нашему опыту, скриншоты довольно хорошо покрывали снимки многих популярных сайтов. У них было много снимков блогов, но не так много бизнес-сайтов.
Хотя снимки для средних веб-сайтов, которые были созданы почти год назад и не имеют большого присутствия, не были заархивированы снимками экрана. С другой стороны, Wayback Machine показали свою полную историю. Таким образом, мы предполагаем, что скриншоты лучше всего, когда вы хотите проверить историю популярных сайтов.
Практическое использование
Использование снимков экрана очень просто: вы можете просматривать снимки избранных изображений, основываясь на новостях, популярности и частоте обновлений, или искать конкретный веб-сайт в строке поиска. Во время поиска убедитесь, что вы ввели полный адрес, например, «beebom.com», а не «beebom».

Когда вы будете искать, вы найдете все снимки в горизонтальной панели с синим ползунком под ним. Вы найдете самую последнюю сделанную дату снимка слева от панели и самую старую справа.
Для поиска снимков просто начните перемещать ползунок слева направо, и под ними вы увидите все снимки с датой, когда они были сделаны. Нажатие на снимки покажет их предварительный просмотр ниже.

Вы увидите все детали о сайте, который вы искали, на правой панели в окне предварительного просмотра. Подробная информация включает дату последнего и самого старого снимков экрана, общее количество снимков экрана, первую запись истории WHOIS для домена, общее количество доменов на одном хостинге и ссылку на полную запись WHOIS веб-сайта. Вы также найдете несколько похожих сайтов, которые вы можете заказать.

Основные характеристики: Принимает screeshonts вместо копирования кода, прост в использовании с простым интерфейсом и обеспечивает полную запись WHOIS домена.
Минусы : делает скриншоты реже и не архивирует менее популярные сайты.
Инструкция по ручному удалению рекламного вируса WAYBACK MACHINE
Для того, чтобы самостоятельно избавиться от рекламы WAYBACK MACHINE, вам необходимо последовательно выполнить все шаги, которые я привожу ниже:
- Поискать «WAYBACK MACHINE» в списке установленных программ и удалить ее.
Открыть Диспетчер задач и закрыть программы, у которых в описании или имени есть слова «WAYBACK MACHINE». Заметьте, из какой папки происходит запуск этой программы. Удалите эти папки.
Запретить вредные службы с помощью консоли services.msc.
Удалить “Назначенные задания”, относящиеся к WAYBACK MACHINE, с помощью консоли taskschd.msc.
С помощью редактора реестра regedit.exe поискать ключи с названием или содержащим «WAYBACK MACHINE» в реестре.
Проверить ярлыки для запуска браузеров на предмет наличия в конце командной строки дополнительных адресов Web сайтов и убедиться, что они указывают на подлинный браузер.
Проверить плагины всех установленных браузеров Internet Explorer, Chrome, Firefox и т.д.
Проверить настройки поиска, домашней страницы. При необходимости сбросить настройки в начальное положение.
Очистить корзину, временные файлы, кэш браузеров.
Origins, growth and storage
In 1996, Brewster Kahle, with Bruce Gilliat, developed software to crawl and download all publicly accessible World Wide Web pages, the Gopher hierarchy, the Netnews bulletin board system, and downloadable software. The information collected by these «crawlers» does not collect all the information available on the Internet since much of the data is restricted by the publisher or stored in databases that are not accessible. These «crawlers» also respect the robots exclusion standard for websites wishing to opt-out of appearing in search results or being cached. To overcome inconsistencies in partially cached websites, Archive-It.org was developed in 2005 by the Internet Archive as a means of allowing institutions and content creators to voluntarily harvest and preserve collections of digital content, and create digital archives.
The digital library grew and grew and grew. But a lot of people knew about it. Information was kept on digital tape for five years, with Kahle occasionally allowing researchers and scientists to tap into the clunky database. When the archive reached its five-year anniversary, it was unveiled and opened to the public in a ceremony at the University of California-Berkeley.
Snapshots usually become available more than 6 months after they are archived, or in some cases, even later, 24 months or longer. The frequency of snapshots is variable, so not all tracked web site updates are recorded. Intervals of several weeks or years sometimes occur.
After August 2008 sites had to be listed on the Open Directory in order to be included. According to Jeff Kaplan of the Internet Archive in November 2010, other sites were still being archived, but more recent captures would only become visible after the next major indexing, an infrequent operation.
As of 2009 the Wayback Machine contained approximately three petabytes of data and was growing at a rate of 100 terabytes each month; the growth rate reported in 2003 was 12 terabytes/month. The data is stored on PetaBox rack systems manufactured by Capricorn Technologies.
In 2009 the Internet Archive migrated its customized storage architecture to Sun Open Storage, and hosts a new datacenter in a Sun Modular Datacenter on Sun Microsystems’ California campus.
In 2011 a new, improved version of the Wayback Machine, with an updated interface and fresher index of archived content, was made available for public testing.
In March 2011 it was said on the Wayback Machine forum that «The Beta of the new Wayback Machine has a more complete and up-to-date index of all crawled materials into 2010, and will continue to be updated regularly. The index driving the classic Wayback Machine only has a little bit of material past 2008, and no further index updates are planned, as it will be phased out this year.»
Как скачать все изменения страницы из веб-архива
Если вас интересует не весь сайт, а определённая страница, но при этом вам нужно проследить все изменения на ней, то в этом случае используйте программу Waybackpack.
К примеру для скачивания всех копий главной страницы сайта suip.biz, начиная с даты (—to-date 2017), эти страницы должны быть помещены в папку (-d /home/mial/test), при этом программа должна следовать HTTP редиректам (—follow-redirects):
waybackpack suip.biz -d ./suip.biz-copy --to-date 2017 --follow-redirects
Структура директорий:
Чтобы для указанного сайта (hackware.ru) вывести список всех доступных копий в веб-архиве (—list):
waybackpack hackware.ru --list
Инструкция по получению уникальных статей с вебархива
1. Запускаем ваш любимый браузер и вводим адрес web.archive.org.
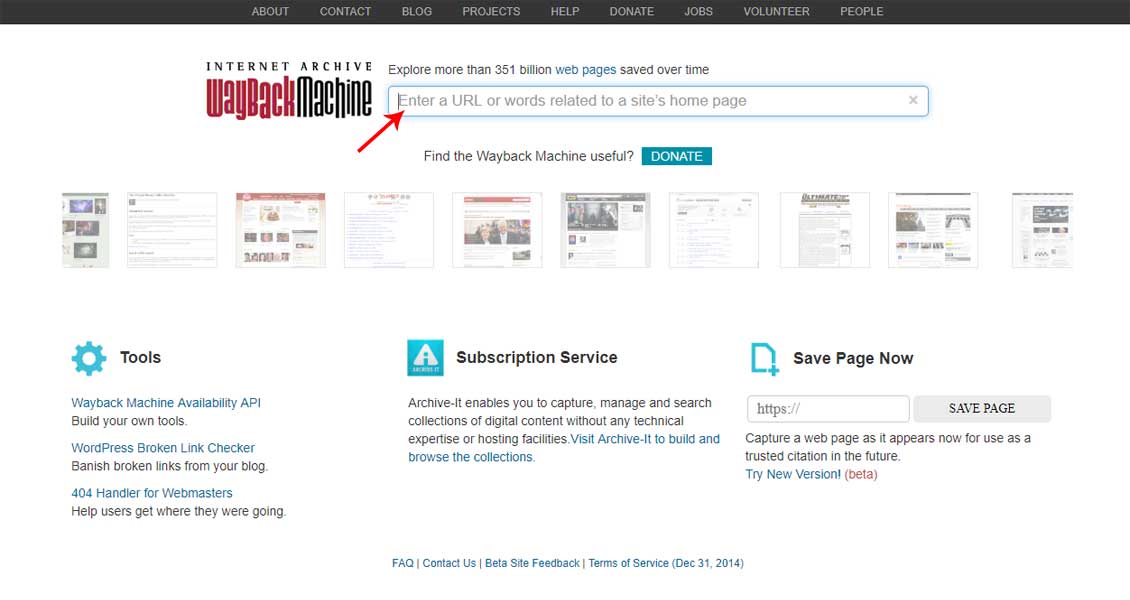
Главная страница вебархива, где будем искать статьи
2. В поисковой строке набираем интересующую вас тематику, например «траляля»
3. Смотрим выдачу сайтов из вебархива
4. Анализируем домены по следующим признакам
4.1. Количество страниц в вебархиве должно быть больше 50

Выдача вебархива, где можно увидеть сколько страниц в архиве
4.2. Проверяем сайт на работоспособность, для этого копируем домен и вставляем в адресную строку браузера. В нашем случае это домен www.generix.com.ua, он оказался свободен.
4.3. Если же домен будет занят и на нем будет находится сайт по схожей тематике то повторите пункты 4.1 и 4.2
4.4. Проверяем таким образом все домены в выдаче вебархива и сохраняем в блокнот те домены которые нам подходят.
5. Скачиваем программу Web Archive Downloader и с помощью нее сохраняем на компьютер архивные копии сайтов, более подробно по работе с программой вы можете ознакомиться в разделе FAQ.
6. Проверяем полученные статьи на уникальность (как читайте ниже)
7. Используем полученные уникальные статьи по назначению
В принципе все, как вы видите ничего сложного нет, осталось разобраться как проверять статьи на уникальность массово. Ведь вы скачаете их
большое количество.
Screenshots
Screenshots can be a good alternative to Wayback Machine, if you want to see how a website actually looked like in the past. Internet archiving websites, including Wayback Machine, copy the web page code and save it for future reference. However, Screenshots just takes a snapshot of a web page and then archives it.
How it Works
Screenshots use the WHOIS database of DomainTools to find the websites to archive and then use snapshots to make a record of them. The time and frequency of taking snapshots for a particular website depends on how many times it got updated with new content.
If a website gets updated frequently with big changes, then it will also be archived more often and you will find more snapshots of it in Screenshots’ history. However, if a website doesn’t get updated frequently or there are not many changes in the design of the website, then you should expect fewer snapshots.
So far, Screenshots has been able to amass over 250 millions snapshots, which is actually nothing compared to 436 billion pages collected by Wayback Machine. However in our experience, Screenshots covered snapshots of many of the popular websites quite well. They had many snapshots of blogs, but not so many of business websites.
Although, snapshots for average websites that have been created hardly a year ago and don’t have much presence were not archived by Screenshots. On the other hand, Wayback Machine showed their complete history. So we guess Screenshots is best when you want to check history of popular websites.
Practical Use
Using Screenshots is dead simple, you either browse snapshots of featured images based on news, popularity and frequency of updates or search for a particular website in the search bar. While searching, make sure you enter complete address, for example “beebom.com” not “beebom”.
When you will search, you will find all the snapshots in a horizontal pane with a blue slider below it. You will find the latest snapshot taken date at the left of the pane and oldest on the right.
To search snapshots, just start moving the slider from left to right and you will see all the snapshots with the date they were taken, below them. Clicking on the snapshots will show a preview of them below.
You will see all the details about the website you searched for in the right panel to the Preview window. The details include, latest and oldest screenshots date, total number of screenshots, WHOIS first history record for the domain, total number of domains on the same hosting and link to complete WHOIS record of the website. You will also find some similar websites that you may like to checkout.
Key Features: Takes screeshonts instead of copying code, easy to use with simple interface and provides complete WHOIS record of the domain.
Cons: Takes screenshots less frequently and doesn’t archives less popular websites.
archive.md
Адреса данного Архива Интернета:
На главной странице говорящие за себя поля:
- Архивировать страницу, которая сейчас онлайн
- Искать сохранённые страницы
Для поиска по сохранённым страницам можно как указывать конкретный URL, так и домены, например:
- microsoft.com покажет снимки с хоста microsoft.com
- *.microsoft.com покажет снимки с хоста microsoft.com и всех его субдоменов (например, www.microsoft.com)
- покажет архив данного url (поиск чувствителен к регистру)
- поиск архивных url начинающихся с http://twitter.com/burg
Данный сервис сохраняет следующие части страницы:
- Текстовое содержимое веб страницы
- Изображения
- Содержимое фреймов
- Контент и изображения загруженные или сгенерированные с помощью Javascript на сайтах Web 2.0
- Скриншоты размером 1024×768 пикселей.
Не сохраняются следующие части веб-страниц:
- Flash и загружаемый им контент
- Видео и звуки
- RSS и другие XML-страницы сохраняются ненадёжно. Большинство из них не сохраняются, или сохраняются как пустые страницы.
Архивируемая страница и все изображения должны быть менее 50 Мегабайт.
Для каждой архивированной страницы создаётся ссылка вида http://archive.is/XXXXX, где XXXXX это уникальный идентификатор страницы. Также к любой сохранённой странице можно получить доступ следующим образом:
- http://archive.is/2013/http://www.google.de/ — самый новый снимок в 2013 году.
- http://archive.is/201301/http://www.google.de/ — самый новый снимок в январе 2013.
- http://archive.is/20130101/http://www.google.de/ — самый новый снимок в течение дня 1 января 2013.
Дату можно продолжить далее, указав часы, минуты и секунды:
- http://archive.is/2013010103/http://www.google.de/
- http://archive.is/201301010313/http://www.google.de/
- http://archive.is/20130101031355/http://www.google.de/
Для улучшения читаемости, год, месяц, день, часы, минуты и секунды могут быть разделены точками, тире или двоеточиями:
- http://archive.is/2013-04-17/http://blog.bo.lt/
- http://archive.is/2013.04.17-12:08:20/http://blog.bo.lt/
Также возможно обратиться ко всем снимкам указанного URL:
http://archive.is/http://www.google.de/
Все сохранённые страницы домена:
http://archive.is/www.google.de
Все сохранённые страницы всех субдоменов
http://archive.is/*.google.de
Чтобы обратиться к самой последней версии страницы в архиве или к самой старой, поддерживаются адреса вида:
- http://archive.is/newest/http://reddit.com/
- http://archive.is/oldest/http://reddit.com/
Чтобы обратиться к определённой части длинной страницы имеется две опции:
В доменах поддерживаются национальные символы:
- http://archive.is/www.maroñas.com.uy
- http://archive.is/*.测试
Обратите внимание, что при создании архивной копии страницы архивируемому сайту отправляется IP адрес человека, создающего снимок страницы. Это делается через заголовок X-Forwarded-For для правильного определения вашего региона и показа соответствующего содержимого.
Принцип работы веб-архива
Прежде чем пытаться восстанавливать сайт из веб-архива, необходимо понять принцип его работы, который является не совсем очевидным. С особенностями работы сталкиваешься только тогда, когда скачаешь архив сайта. Вы наверняка замечали, попадая на тот или иной сайт, сообщение о том, что домен не продлен или хостинг не оплачен. Поскольку бот, который обходит сайты и скачивает страницы, не понимает что подобная страница не является страницей сайта, он скачивает её как новую версию главной страницы сайта.
Таким образом получается если мы скачаем архив сайта, то вместо главной страницы будем иметь сообщение регистратора или хостера о том, что сайт не работает. Чтобы этого избежать, нам необходимо изучить архив сайта. Для этого потребуется просмотреть все копии и выбрать одну или несколько где на главной странице страница сайта, а не заглушка регистратора или хостера.
Which Sites Are Cataloged?
Many popular websites are automatically archived by the Wayback Machine. However, you can use the Wayback Machine to manually archive virtually any page. Websites are often abandoned or changed completely, so the Wayback machine acts as a way to preserve the culture of the Internet by keeping a digital “hard copy” of a website. Be aware that text and images are left intact; however, some outbound links and embedded items (e.g. videos) are not.
It is important to note that The Wayback Machine only scans and archives public sites. This means that password protected sites or ones located on private servers cannot be archived. In addition, if a website prohibits search engines from including it in search results, Wayback Machine will not be able to archive it.
Archive-It
Do you or your organization have a website that needs to be indexed and archived frequently? If so, manually archiving each individual web page using the methods above can be incredibly tedious and costly. Fortunately, the Internet Archive provides a service called Archive-It that can automate the archiving process for you.
This service is not free; however, it can be ideal for those who want to back up their content with a “set it and forget it” mentality. Just stipulate which pages you would like to save and how often. This paid subscription is perfect for those who wish to save their web content on a regular basis.
Do you use the Wayback Machine? If so, do you visit it purely for fun or do you find it a useful tool? Are there other ways to back up content on the Web? Let us know in the comments!
r-tools.org
Первое, что бросается в глаза дизайн сайта стороват. Ребята, пора обновлять!
Плюсы:
- Подходит для парсинга сайтов у которых мало html страниц и много ресурсов другого типа. Потомучто они рассчитывают цену по html страницам
- возможность отказаться от сайта, если качество не устроило. После того как система скачала сайт, вы можете сделать предпросмотр и отказаться если качество не устроило, но только если еще не заказали генерацию архива. (Не проверял эту функцию лично, и не могу сказать на сколько хорошо реализован предпросмотр, но в теории это плюс)
- Внедрена быстрая интеграция сайта с биржей SAPE
- Интерфейс на русском языке
Минусы:
- Есть демо-доступ — это плюс, но я попробовал сделать 4 задания и не получил никакого результата.
- Высокие цены. Парсинг 25000 стр. обойдется в 2475 руб. , а например на Архивариксе 17$. Нужно учесть, что r-tools считает html страницы, архиварикс файлы. Но даже если из всех файлов за 17$ только половина html страницы, все равно у r-tools выходит дороже. (нужно оговориться, что считал при $=70руб. И возможна ситуация, когда r-tools будет выгоден написал про это в плюсах)
Archive.is
Archive.is является еще одной хорошей альтернативой Wayback Machine и, возможно, лучше, чем скриншоты для большинства людей. Это не один из самых привлекательных веб-сайтов или простой в навигации, но его база данных и методы архивирования восполняют его.
Archive.is позволит вам выполнять поиск по истории веб-сайта и снимать скриншот любого домена по запросу, который будет сохранен для всеобщего просмотра. Это делает его идеальным решением для получения всех подробностей о веб-сайте, включая данные и графические данные.
Как это устроено
Archive.is архивирует веб-сайт по запросу или в соответствии с частотой действий на конкретном веб-сайте. Это займет и скриншот и код сайта во время архивирования. Однако, в отличие от Wayback Machine, он не отправляет сканеры для архивирования веб-страниц. Это означает, что веб-сайт не может остановить Archive.is от архивирования с использованием файла robot.txt.
Если существует веб-сайт, который может блокировать сканирование Wayback Machine своего сайта, вам следует выбрать Archive.is, чтобы получить доступ к нему.
Практическое использование
Веб-сайт Archive.is не так привлекателен, как Wayback Machine или Screenshots. Хотя, это довольно просто для навигации с наименьшим количеством вариантов для беспокойства. На главной странице вы найдете две панели поиска, одну красную сверху и другую синюю снизу. Красная панель поиска — это место, где вы можете запросить архивирование веб-страницы, а синим цветом вы можете просмотреть историю любого веб-сайта.
Архив спроса
В красной строке поиска вы можете потребовать архивирование любого веб-сайта, а Archive.is скопирует код и сделает его снимок экрана. Просто введите URL-адрес страницы веб-сайта в строку поиска и нажмите «сохранить страницу».
Archive.is начнет обработку и после небольшой задержки (в зависимости от размера страницы) вы увидите заархивированную страницу и снимок экрана с ней.
Примечание . Вы не ограничены простым добавлением URL-адреса целевой страницы определенного веб-сайта, вы можете добавить URL-адрес любой страницы веб-сайта. Просто зайдите на страницу, которую вы хотите заархивировать, и скопируйте / вставьте ее URL в архиве. При поиске он будет заархивирован.
Проверить архивную историю веб-сайта
В синей строке поиска ниже вы можете ввести URL-адрес веб-сайта, и вы увидите всю его историю. Будет два варианта: самый старый и самый новый. Самая старая содержит самую старую заархивированную веб-страницу, а самая новая содержит самые последние заархивированные страницы и возвращаясь оттуда.
Вы увидите все заархивированные страницы, начиная с самых последних и возвращаясь назад, вместе с данными, указанными под каждой веб-страницей. Вы можете просто нажать на любую веб-страницу, чтобы увидеть ее детали.
Откроется архивированная веб-страница, и вы можете легко перемещаться по ней. Вы можете нажать на «Снимок экрана», чтобы увидеть скриншот этой конкретной веб-страницы.
В наших результатах скриншоты архивировались 9gag 21 раз, а с другой стороны, Archive.is архивировал его 1063 раза. С этим небольшим примером вы можете взвесить частоту архивирования сайта.
Основные характеристики: архивирует как код, так и снимок экрана веб-страницы, огромную базу данных, обменивается результатами и загружает их, а также запрашивает архивирование любого веб-сайта в любое время.
Минусы: непривлекательный интерфейс, сложно ориентироваться на нужной веб-странице и не предоставляет много информации о конкретной веб-странице.
Method 2: using FTP
This Tutorial explains how you can recover a website from the Waybackmachine. It also explains exactly how you can upload the files with Cpanel and FTP.
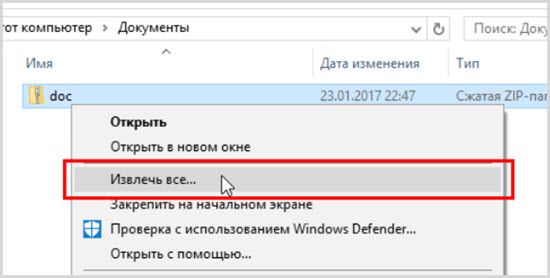
- 1. Download the .zip file with all the HTML files. Extract the files (unzip) to a folder of your choice.
- 2. You need to transfer the files to the server using FTP software. If you don’t have an FTP client already, then we recommend FileZilla: https://filezilla-project.org/
-
3. If you don’t already have an FTP account at your hosting provider, then create one. If your host uses cPanel, then find the icon that says «FTP Accounts» (most hosting providers use cPanel: Hostgator, Godaddy, BlueHost : all of them use cPanel)
cPanel example:It’s usually easier to create an FTP account when adding a domain to your hosting:
- 4. Find the IP address of your server. In GoDaddy you can find your IP address on the hosting dashboard:
-
5. We use FileZilla for Windows in this guide, but you can also download it for Apple computers.
You should now have an FTP account and know your IP address. Open an FTP client. We use FileZilla in this guide.
— Fill in your username and password.
— The username should be
— Host should be the IP address of your server, that will host the Wayback files.
— Port can be blank.
— Press Quickconnect to connect. - 6. Now select all the files and move them to the remote site:
- 7. Your site should work now.