Нормализация баз данных
Содержание:
- 1НФ — первая нормальная форма
- «Ничего, кроме ключа»
- Нормализация данных: методы и формулы
- Вторая нормальная форма
- Плюсы
- Пример приведения таблицы ко второй нормальной форме (первичный ключ составной)
- Третья нормальная форма
- Перед началом…
- Нормализация и стандартизация — методы шкалирования данных
- Пример приведения таблиц базы данных к четвертой нормальной форме
- Классический пример приведения таблиц базы данных к четвертой нормальной форме
- Заключение
1НФ — первая нормальная форма
Собственные типы данных СУБД считаются атомарными, исключение могут составлять массивы, в том числе символьные (текстовые) и байтовые. Следует также понимать, что атомарность может быть относительна выбранного взгляда со стороны предметной области и контекста. Например, телефонный номер в базе данных маркетинга содержится в одной колонке, тогда как у телефонных операторов он разделяется на номера АТС, шлейфов и т.п. Колонки для хранения комментариев, подлежащих последующей обработке приложением, также отчасти нарушают принцип атомарности.
По этой же причине не стоит рассматривать отдельно целую и дробные части действительного числа или даже пару «дата-время»: дальнейшая детализация не имеет смысла с точки зрения моделируемой области, где они атомарны.
Предположим, мы нарушили 1НФ и стали хранить фамилии, имена и отчества клиентов в одной колонке. Пока операторы вносили информацию, эта ошибка проектирования особенно не мешала, Однако, на следующем этапе понадобилась отчётность, в которой ФИО клиентов выводились бы в виде фамилии и инициалов. Оказалось, что некоторые записи вместо «Сидоров Петр Иванович» содержат «Петр Иванович Сидоров», в других отчества нет вовсе, в третьих фамилия двойная и не всегда записана через тире, в четвёртых после фамилий расставлены запятые… Эту проблему пришлось решать программированием совсем нетривиальной логики с элементами распознавания по словарю. Было потрачено много времени и средств, но в отчётности нет-нет да и проскакивали непонятные значения типа «Оглы П.Б.Б.».
Следует отметить, что при добавлении к этому учёту клиентов- иностранцев, проектировщиков логической схемы БД не спасла бы и более структурированная форма из трёх колонок для раздельного хранения фамилий, имён и отчеств. Потому что это проблема уровня концептуального проектирования и соответствующих моделей: необходим синтез не привязанной к модели данных структуры, способной вмещать в себя комбинации имён людей разных стран и культур.
«Ничего, кроме ключа»
Билл Кент дал приблизительное определение 3NF, данное Коддом, параллельно традиционному обязательству дать правдивые показания в суде: « неключевой должен содержать факт о ключе, о ключе в целом, и ничего, кроме ключа ». Распространенная вариация дополняет это определение клятвой «Помоги мне, Кодд ».
Требование наличия «ключа» гарантирует, что таблица находится в 1NF ; требование, чтобы неключевые атрибуты зависели от «всего ключа», обеспечивает 2NF ; дальнейшее требование, чтобы неключевые атрибуты зависели от «ничего, кроме ключа», обеспечивает 3NF. Хотя эта фраза является полезной мнемоникой, тот факт, что в ней упоминается только один ключ, означает, что она определяет некоторые необходимые, но не достаточные условия для удовлетворения 2-й и 3-й нормальных форм. И 2NF, и 3NF одинаково относятся ко всем ключам-кандидатам таблицы, а не только к одному ключу.
Крис Дэйт называет краткое изложение Кента «интуитивно привлекательной характеристикой» 3NF и отмечает, что с небольшой адаптацией оно может служить определением немного более сильной нормальной формы Бойса – Кодда : «Каждый атрибут должен представлять собой факт о ключе, в целом ключ, и ничего, кроме ключа «. Версия определения 3NF слабее, чем вариант BCNF Дейта, поскольку первая касается только обеспечения зависимости неключевых атрибутов от ключей. Основные атрибуты (которые являются ключами или их частями) вообще не должны быть функционально зависимыми; каждый из них представляет собой факт о ключе в смысле предоставления части или всего ключа. (Это правило применяется только к функционально зависимым атрибутам, так как его применение ко всем атрибутам неявно запрещает составные ключи-кандидаты, поскольку каждая часть любого такого ключа нарушает условие «весь ключ».)
Примером таблицы 2NF, которая не соответствует требованиям 3NF, является:
| Турнир | Год | Победитель | Дата рождения победителя |
|---|---|---|---|
| Индиана Invitational | 1998 г. | Аль Фредриксон | 21 июля 1975 г. |
| Кливленд Опен | 1999 г. | Боб Альбертсон | 28 сентября 1968 г. |
| Де-Мойн Мастерс | 1999 г. | Аль Фредриксон | 21 июля 1975 г. |
| Индиана Invitational | 1999 г. | Чип Мастерсон | 14 марта 1977 г. |
Поскольку каждая строка в таблице должна сообщать нам, кто выиграл конкретный турнир в конкретный год, составной ключ {Tournament, Year} представляет собой минимальный набор атрибутов, гарантирующих уникальную идентификацию строки. То есть {Tournament, Year} — это кандидатный ключ для таблицы.
Нарушение 3NF происходит из-за того, что непростой атрибут (дата рождения Победителя) транзитивно зависит от ключа кандидата {Турнир, Год} через непервичный атрибут Победитель. Тот факт, что дата рождения Winner функционально зависит от Winner, делает таблицу уязвимой для логических несоответствий, поскольку ничто не мешает одному и тому же человеку отображаться с разными датами рождения в разных записях.
Чтобы выразить одни и те же факты, не нарушая 3НФ, необходимо разделить таблицу на две части:
|
|
В этих таблицах не могут возникнуть аномалии обновления, потому что, в отличие от ранее, Победитель теперь является кандидатом ключа во второй таблице, что позволяет использовать только одно значение Даты рождения для каждого Победителя.
Нормализация данных: методы и формулы
Существует множество способов нормализации значений признаков, чтобы масштабировать их к единому диапазону и использовать в различных моделях машинного обучения. В зависимости от используемой функции, их можно разделить на 2 большие группы: линейные и нелинейные. При нелинейной нормализации в расчетных соотношениях используются функции логистической сигмоиды или гиперболического тангенса. В линейной нормализации изменение переменных осуществляется пропорционально, по линейному закону.
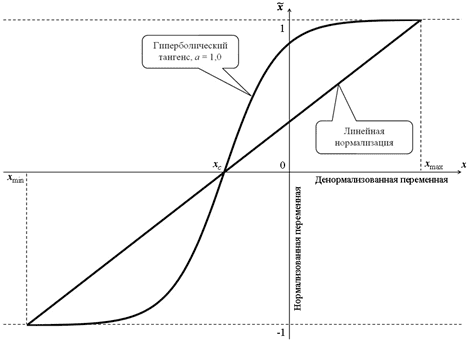
Графическая интерпретация линейной и нелинейной нормализации
На практике наиболее распространены следующие методы нормализации признаков :
- Минимакс – линейное преобразование данных в диапазоне , где минимальное и максимальное масштабируемые значения соответствуют 0 и 1 соответственно;
- Z-масштабирование данных на основе среднего значения и стандартного отклонения: деление разницы между переменной и средним значением на стандартное отклонение;
- десятичное масштабирование путем удаления десятичного разделителя значения переменной.
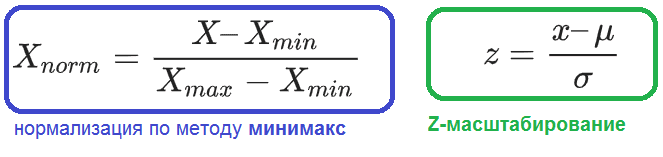
Формулы нормализации данных по методам минимакс и Z-масштабирование
На практике минимакс и Z-масштабирование имеют похожие области применимости и часто взаимозаменяемы. Однако, при вычислении расстояний между точками или векторами в большинстве случае используется Z-масштабирование. А минимакс полезен для визуализации, например, чтобы перенести признаки, кодирующие цвет пикселя, в диапазон .
Вторая нормальная форма
Для приведения таблиц ко второй нормальной форме (2НФ), приводимые таблицы должны быть уже в 1НФ. Нормализация должна проходить по порядку.
Теперь, во второй нормальной форме, должно быть соблюдено условие — любой столбец, который не является ключом (в том числе внешним), должен зависеть от первичного ключа. Обычно такие столбцы, имеющие значения, который не зависят от ключа, легко определить. Если данные, содержащиеся в столбце, не имеют отношения к ключу, который описывает строку, то их следует отделять в свою отдельную таблицу. В старую таблицу надо возвращать первичный ключ.
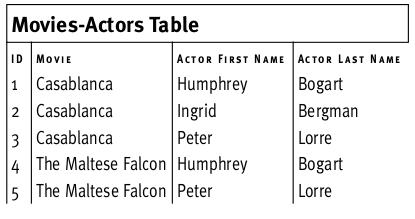
На рисунке выше и названия фильмов и имена актеров нарушают правила 2НФ (сами не являются ключами и не зависят от первичного ключа).
После всех преобразований, база данных с фильмами будет иметь минимум 4 таблицы.
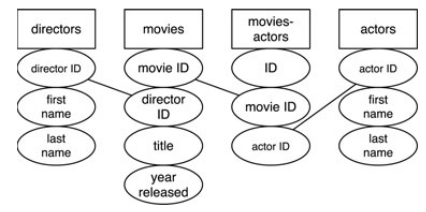
Каждое имя режиссёра, название картины и имя актера хранится только один раз и все неключевые поля зависят от первичного ключа их собственной таблицы.
По факту, нормализация может быть утрированно названа процессом создания все новых и новых таблиц до тех пор, пока избыточность и повторения не будут полностью уничтожены.
Чтобы привести базу ко второй нормальной форме, надо:
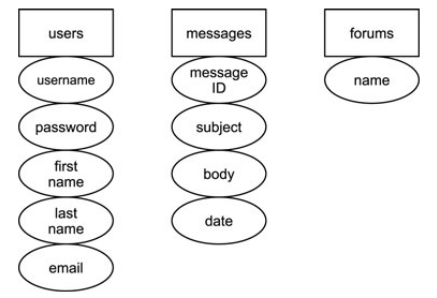
- Определить все столбцы, которые не находятся в прямой зависимости от первичного ключа этой таблицы. На рисунке выше у таблиц users и forums нет первичного ключа. У таблицы messages первичный ключ — message ID, от которого зависят все остальные поля этой таблицы.
- Создаем необходимые поля в таблицах users и forums, выделяем из существующих полей или создаем из новых первичные ключи.
- Создаем внешние ключи и обозначаем их отношения между таблицами. Конечным шагом нормализации до 2НФ будет являться выделение внешних ключей для связи с ассоциированными таблицами. Первичный ключ одной таблицы должен быть внешним ключом в другой. На рисунке снизу показана связь между ключами трех таблиц. Поле user ID таблицы messages является первичным ключом поля user ID таблицы users. Тип связи между ними — один ко многим. Один пользователь может оставить много сообщений, но у сообщения может быть только один пользователь. Такая же связь соединяет таблицы forums и messages через forum ID. У форума может быть много сообщений, но сообщение может находиться только в одном форуме.
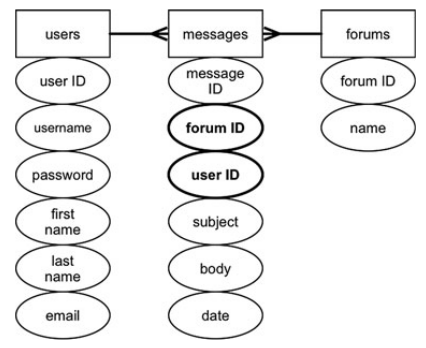
Подсказки:
- Другой способ приведения схемы к 2НФ — посмотреть на отношения между таблицами. Идеальный вариант — создать все отношения вида один-к-многим. Отношения вида многие-к-многим нуждаются в реструктуризации.
- Если взглянуть еще раз на таблицу movies-actors, то можно заметить, что она является промежуточной таблицей. Она превращает отношение многие-к-многим между movies и actors в один-к-многим. Можно вводить такие промежуточные таблицы, у которых все столбцы являются ключами. В таких таблицах не требуется свой собственный первичный ключ, поскольку он может быть комбинацией двух внешних ключей.
- Нормализованная должным образом таблица никогда не будет иметь повторяющихся рядов (двух и более рядов, значения которых не являются ключами и содержат совпадающие данные).
- Чтобы упростить нормализацию, помните, что при приведении к 1НФ вы ищете дубли горизонтально (дубли столбцов), а при приведении к 2НФ — вертикально (дубли рядов).
Плюсы
Нормализация не является обязательной, но приносит следующие преимущества:
— упрощается процесс выборки. Речь идет об упрощении работы по составлению запросов, то есть пользователь сможет получать нужную информацию относительно простыми запросами;
— обеспечивается целостность данных. Можно говорить о минимизации искажения информации и снижении вероятности потери данных;
— улучшается масштабируемость. При соблюдении правил нормализации формируются благоприятные предпосылки к росту БД;
— отсутствует избыточность (data redundancy). Избыточность — известная проблема непродуктивного использования свободного места на жестком диске, затрудняющая обслуживание БД. В отдельных случаях эту проблему усугубляет и то, что в случае необходимости изменения записей однотипных данных, хранимых в нескольких местах (таблицах), пользователю придется вносить требуемые изменения везде, что весьма трудоемкое занятие. Гораздо проще сделать так, чтобы, к примеру, данные о городах хранились только в таблице Cities и нигде больше. Если подытожить вышесказанное, избыточность предполагает дублирование данных, а это не только усложняет работу с БД, но и увеличивает ее размер;
— отсутствие несогласованных зависимостей. Несогласованные зависимости затрудняют доступ к данным, ведь путь к такой информации может быть неправилен и нелогичен. В той же таблице Cities логично искать города, количество жителей и т. п., но не адреса и имена жителей — для этой информации уже нужна другая таблица — Citizens.
Пример приведения таблицы ко второй нормальной форме (первичный ключ составной)
А теперь давайте рассмотрим другую ситуацию, в которой первичный ключ у нас будет составным.
Представим, что наша организация выполняет несколько проектов, в которых может быть задействовано несколько участников, и нам необходимо хранить информацию об этих проектах. В частности мы хотим знать, кто участвует в каждом из проектов, продолжительность этого проекта, ну и возможно какие-то другие сведения. При этом мы понимаем, что отдельно взятый сотрудник может участвовать в нескольких проектах.
Для хранения таких данных мы создали следующую таблицу.
Таблица проектов организации в первой нормальной форме.
| Название проекта | Участник | Должность | Срок проекта (мес.) |
| Внедрение приложения | Иванов И.И. | Программист | 8 |
| Внедрение приложения | Сергеев С.С. | Бухгалтер | 8 |
| Внедрение приложения | John Smith | Менеджер | 8 |
| Открытие нового магазина | Сергеев С.С. | Бухгалтер | 12 |
| Открытие нового магазина | John Smith | Менеджер | 12 |
Как видим, она в первой нормальной форме, значит, мы можем пытаться приводить ее ко второй нормальной форме.
Как Вы помните, чтобы привести таблицу ко второй нормальной форме, необходимо определить для нее первичный ключ.
Посмотрев на эту таблицу, мы понимаем, что четко идентифицировать каждую строку мы можем только с помощью комбинации столбцов, например, «Название проекта» + «Участник», иными словами, зная «Название проекта» и «Участника», мы можем четко определить конкретную запись в таблице, т.е. каждое сочетание значений этих столбцов является уникальным.
Таким образом, мы определили первичный ключ и он у нас составной, т.е. состоящий их двух столбцов.
Таблица проектов организации. Внедрен составной первичный ключ.
| Название проекта | Участник | Должность | Срок проекта (мес.) |
| Внедрение приложения | Иванов И.И. | Программист | 8 |
| Внедрение приложения | Сергеев С.С. | Бухгалтер | 8 |
| Внедрение приложения | John Smith | Менеджер | 8 |
| Открытие нового магазина | Сергеев С.С. | Бухгалтер | 12 |
| Открытие нового магазина | John Smith | Менеджер | 12 |
Так как первичный ключ составной, нам необходимо проверить еще и второе требование, которое гласит, что «Все неключевые столбцы таблицы должны зависеть от полного ключа».
Другими словами, остальные столбцы, которые не входят в первичный ключ, должны зависеть от всего первичного ключа, т.е. от всех столбцов, а не от какого-то одного.
Чтобы это проверить, мы можем задать себе несколько вопросов.
Можем ли мы определить «Должность», зная только название проекта? Нет. Для этого нам необходимо знать и участника. Значит, пока все хорошо, по этой части ключа мы не можем четко определить значение неключевого столбца. Идем дальше и проверяем другую часть ключа.
Можем ли мы определить «Должность» зная только участника? Да, можем. Значит наш первичный ключ плохой, и требование второй нормальной формы не выполняется.
Что делать в этом случае?
В этом случае мы будем выполнять действие, которое выполняется, наверное, в 99% случаев на протяжении всего процесса нормализации базы данных – это декомпозиция.
Чтобы декомпозировать нашу таблицу и привести базу данных к нормализованной форме, мы должны создать следующие таблицы.
Проекты.
| Идентификатор проекта | Название проекта | Срок проекта (мес.) |
| 1 | Внедрение приложения | 8 |
| 2 | Открытие нового магазина | 12 |
Участники.
| Идентификатор участника | Участник | Должность |
| 1 | Иванов И.И. | Программист |
| 2 | Сергеев С.С. | Бухгалтер |
| 3 | John Smith | Менеджер |
Связь проектов и участников этих проектов.
| Идентификатор проекта | Идентификатор участника |
| 1 | 1 |
| 1 | 2 |
| 1 | 3 |
| 2 | 2 |
| 2 | 3 |
Мы создали 3 таблицы:
- Проекты, в нее мы добавили искусственный первичный ключ
- Участники, в нее мы также добавили искусственный первичный ключ
- Связь между проектами и участниками, она нужна для реализации связи «Многие ко многим», так как между этими таблицами связь именно такая
После того как мы привели таблицы базы данных ко второй нормальной форме, мы можем переходить к приведению таблиц до третьей нормальной формы (3NF). Описание, требования и пример приведения таблиц до третьей нормальной формы мы рассмотрим в следующем материале.
На сегодня это все, надеюсь, материал был Вам полезен, пока!
Нравится75Не нравится
Третья нормальная форма
Значения в записи, которая не входит в ключ этой записи, не относятся к таблице. В общем, в любое время содержимое группы полей может применяться к более чем одной записи в таблице, рассмотрите возможность размещения этих полей в отдельной таблице.
Например, в таблице набора сотрудников может быть включено имя и адрес университета кандидата. Но для групповой рассылки необходим полный список университетов. Если сведения о университетах хранятся в таблице Candidates, нет возможности перечислять университеты без текущих кандидатов. Создайте отдельную таблицу университетов и привяжете ее к таблице Кандидаты с ключом кода университета.
ИСКЛЮЧЕНИЕ: применение третьей обычной формы, хотя теоретически желательно, не всегда является практическим. Если у вас есть таблица Клиентов и вы хотите устранить все возможные зависимости между полями, необходимо создать отдельные таблицы для городов, почтовых индексов, представителей продаж, классов клиентов и любого другого фактора, который может быть дублирован в нескольких записях. В теории, нормализация стоит очистки. Однако многие небольшие таблицы могут ухудшать производительность или превышать возможности открытого файла и памяти.
Возможно, более целесообразно применять третью нормальную форму только к данным, которые часто меняются. Если остаются некоторые зависимые поля, спроектировать приложение, чтобы потребовать от пользователя проверить все связанные поля при их смене.
Перед началом…
Перед тем, как мы начнем изучать правила нормализации и применять их, мы должны разобраться со следующими понятиями.
Избыточность
Одним из основных моментов, который нужно учитывать при проектировании таблиц — уменьшение пространства для хранения данных. Таблицы должны быть спроектированы таким образом, чтобы повторяющиеся данные хранились отдельно, в одной или нескольких таблицах. Хранение повторяющихся данных не только требует больше места, но также приводит к более серьезным проблемам.
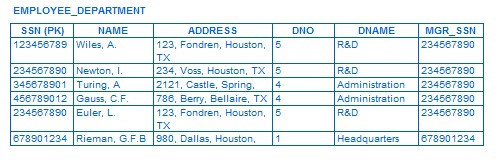 Таблица с данными о сотрудниках из разных отделов, содержит избыточные данные
Таблица с данными о сотрудниках из разных отделов, содержит избыточные данные
Обратите внимание, что данные в полях DNAME и DNO неоднократно повторяются в таблице. Такой вид избыточности данных приводит к аномалиям обновления, вставки и удаления
Аномалии вставки
Если нам понадобится добавить в таблицу информацию о новом сотруднике, который не «привязан» к какому-либо отделу, данные об отделе в добавляемой записи окажутся пустыми, а это явно неоправданная трата пространства. Кроме того, при вставке данных нового сотрудника, скажем, в отдел с идентификатором ‘4’, другие поля, относящиеся к отделу, также должны будут повториться. Пример: отдел 4, поле DNAME должно содержать значение ‘Administrator’, а поле MGR_SSN — содержимое должно быть равно ‘234567890’.
Аномалии обновления
Если мы изменим значение какого-либо поля, относящегося к отделу, например, DNAME или MGR_SSN, мы должны будем изменить это значение у записей всех сотрудников, которые работают в этом отделе. Иначе, база данных будет находиться в несогласованном состоянии.
Аномалии удаления
Предположим, мы удалим информацию об одном сотруднике, например, последнюю запись из представленной выше таблицы. Только у этой записи значение в поле DNO равно ‘1’, в результате этого действия получится, что информация об отделе будет потеряна. Это нелепо, потому что мы хотим удалить информацию о сотруднике, а не обо всем отделе.
Функциональные зависимости
Функциональные зависимости — основа нормализации баз данных. Под функциональной зависимостью подразумевается зависимость значения одного поля (столбца) от другого. Например, по значению поля SSN определенного работника, мы сможем найти его адрес. Это значит, что поле адрес функционально зависимо от поля SSN. Символическая запись этой зависимости выглядит так:
{SSN} → {ADDRESS}
Аналогично,
{SSN} → {ENAME, ADDRESS} {SSN, DNO} → {MGR_SSN}
Когда значение одного или нескольких полей точно идентифицируют запись, значение такого поля называется «первичным ключом».
Нормализация и стандартизация — методы шкалирования данных
Нормализация (normalization) и стандартизация (standardization) являются методами изменения диапазонов значений – шкалирования. Шкалирование особенно полезно в машинном обучении (Machine Learning), поскольку разные атрибуты могут измеряться в разных диапазонах, или значения одного атрибута варьируются слишком сильно. Например, один атрибут имеет диапазон от 0 до 1, а второй — от 1 до 1000. Для задачи регрессии второй атрибут оказывал бы большое влияние на обучение, хотя не факт, что он является более важным, чем первый. Нормализация и стандартизация отличаются своими подходами:
-
Нормализация подразумевает изменение диапазонов в данных без изменения формы распределения,
-
Стандартизация изменяет форму распределения данных (приводится к нормальному распределению).
Обычно достаточно нормализовать данные. Например, в глубоком обучении (Deep Learning) требуется перевести цвета изображений RGB из диапазона 0-255 к диапазону 0-1. А вот стандартизацию стоит применять при использование алгоритмов, которые основываются на измерении расстояний, например, k ближайших соседей или метод опорных векторов (SVM).
Пример приведения таблиц базы данных к четвертой нормальной форме
Представим, что мы работаем в каком-то учебном заведении, где есть курсы, которые изучают студенты, преподаватели, которые читают эти курсы, и аудитории, в которых преподаватели проводят занятия по курсам.
Курсы.
| Идентификатор курса | Название курса |
| 1 | SQL |
| 2 | Python |
| 3 | JavaScript |
Преподаватели.
| Идентификатор преподавателя | ФИО |
| 1 | Иванов И.И. |
| 2 | Сергеев С.С. |
| 3 | John Smith |
Аудитории.
| Идентификатор аудитории | Название аудитории |
| 1 | 101 |
| 2 | 203 |
| 3 | 305 |
| 4 | 407 |
| 5 | 502 |
При этом мы понимаем, что один и тот же курс могут преподавать разные преподаватели, и необязательно в какой-то одной аудитории, один раз курс может читаться в одной аудитории, а в другой раз совсем в другой аудитории, например, на курс записалось гораздо меньше студентов и чтобы не занимать аудиторию большого размера, под этот поток могут выделить аудиторию меньшего размера.
Также стоит отметить, что под каждый курс подходит только определенный набор аудиторий, например, те, которые оснащены необходимым оборудованием, или те, которые имеют соответствующую вместимость для конкретно этого курса.
В учебном заведении, конечно же, постоянно возникают вопросы с составлением расписания, однако для того чтобы его составлять, необходимо предварительно знать возможности этого учебного заведения. Иными словами, какие преподаватели могут преподавать тот или иной курс, а также в каких аудиториях тот или иной курс может читаться.
Для этого нам необходимо соединить эти три сущности в одной таблице. В итоге у нас получается следующая таблица (для наглядности здесь представлены текстовые значения, а не идентификаторы).
Таблица связей курсов, преподавателей и аудиторий.
| Курс | Преподаватель | Аудитория |
| SQL | Иванов И.И. | 101 |
| SQL | Иванов И.И. | 203 |
| SQL | Сергеев С.С. | 305 |
| SQL | Сергеев С.С. | 407 |
| Python | John Smith | 502 |
| Python | John Smith | 305 |
В данном случае первичный ключ здесь состоит из всех трех столбцов, поэтому эта таблица автоматически находится в третьей нормальной форме и нормальной форме Бойса-Кодда. Однако она не находится в четвертой нормальной форме, так как здесь есть многозначная зависимость
Курс ->-> Преподаватель
Курс ->-> Аудитория
Т.е. для каждого курса в этой таблице может быть несколько преподавателей, а также несколько аудиторий.
При этом, Вы понимаете, что преподавателю без разницы, в какой аудитории читать лекцию, ровно так же как и самой аудитории без разницы, какой преподаватель в ней будет работать))
Иными словами, эти два атрибута «Преподаватель» и «Аудитория» никак не зависят друг от друга, но они оба по отдельности зависят от курса.
Но что же плохого в этой таблице и в этой многозначной зависимости? Вы можете спросить.
Чтобы ответить на этот вопрос, мы можем задать себе несколько других вопросов.
Что будет если, например, преподаватель «Иванов И.И.» уволился? Нам нужно будет удалить две строки из этой таблицы, но удалив эти строки, мы удалим всю информацию и о аудиториях 101 и 203. Но они на самом-то деле есть и должны участвовать в планировании расписания. Это аномалия, и это плохо.
Или другая ситуация, что будет, если курсу назначен преподаватель, но аудитория еще не определена? Или наоборот, с аудиторией уже определились, а вот преподаватель еще не известен.
Мы должны создать записи либо с NULL либо со значениями по умолчанию, и это также является аномалией.
Многозначные зависимости плохи как раз тем, что их нельзя независимо друг от друга редактировать. Иными словами, чтобы внести изменения в одну зависимость, мы неизбежно должны затронуть другую зависимость.
Поэтому главное правило четвертой нормальной формы звучит следующим образом:
Решение в данном случае как всегда – декомпозиция.
Мы должны вынести каждую многозначную зависимость в отдельную таблицу, т.е. разнести независимые друг от друга атрибуты, в нашем случае «Преподаватель» и «Аудитория», по разным таблицам.
Связь курсов и преподавателей.
| Курс | Преподаватель |
| SQL | Иванов И.И. |
| SQL | Сергеев С.С. |
| Python | John Smith |
Связь курсов и аудиторий.
| Курс | Аудитория |
| SQL | 101 |
| SQL | 203 |
| SQL | 305 |
| SQL | 407 |
| Python | 502 |
| Python | 305 |
Классический пример приведения таблиц базы данных к четвертой нормальной форме
Чтобы стало еще понятней, давайте закрепим знания и рассмотрим классический пример, который обычно используется в литературе для пояснения четвертой нормальной формы.
Таблица связей студентов, курсов и хобби.
| Студент | Курс | Хобби |
| Иванов И.И. | SQL | Футбол |
| Иванов И.И. | Java | Хоккей |
| Сергеев С.С. | SQL | Волейбол |
| Сергеев С.С. | SQL | Теннис |
| John Smith | Python | Футбол |
| John Smith | Java | Теннис |
Данная таблица хранит информацию о студентах, в частности здесь хранятся курсы, которые посещает студент, и увлечения этого студента, т.е. хобби.
Отсюда следует, что каждый студент может посещать несколько курсов и иметь несколько увлечений.
Первичный ключ здесь также составной и состоит он из всех трех столбцов.
При этом мы можем заметить, что курс и хобби никак не связаны и не зависят друг от друга, но по отдельности зависят от студента.
Таким образом, мы можем наблюдать в этой таблице нетривиальную многозначную зависимость
Студент ->-> Курс
Студент ->-> Хобби
Поэтому эта таблица не находится в четвертой нормальной форме.
Кроме всех тех аномалий, связанных с редактированием данных, которые мы уже рассмотрели на предыдущем примере, в данном случае еще продемонстрирована проблема неоднозначной выборки данных.
Допустим, нам необходимо получить информацию о хобби студентов, которые посещают курс по SQL. Очевидным действием станет выборка с условием Курс = SQL, в результате мы получим 3 хобби: футбол, волейбол и теннис.
Результат выборки. Хобби студентов, которые посещают курс по SQL.
| Студент | Курс | Хобби |
| Иванов И.И. | SQL | Футбол |
| Сергеев С.С. | SQL | Волейбол |
| Сергеев С.С. | SQL | Теннис |
Однако, если мы заглянем в исходную таблицу, то мы четко увидим, что «Иванов И.И.» посещает курс по SQL и имеет хобби «Хоккей», но в нашей выборке этого хобби нет.
Чтобы нормализовать эту таблицу, мы должны точно так же, как и в предыдущем примере, разбить ее на две.
Связь студентов и курсов.
| Студент | Курс |
| Иванов И.И. | SQL |
| Иванов И.И. | Java |
| Сергеев С.С. | SQL |
| John Smith | Python |
| John Smith | Java |
Связь студентов и хобби.
| Студент | Хобби |
| Иванов И.И. | Футбол |
| Иванов И.И. | Хоккей |
| Сергеев С.С. | Волейбол |
| Сергеев С.С. | Теннис |
| John Smith | Футбол |
| John Smith | Теннис |
Однако в реальности такую ситуацию и такую таблицу вряд ли можно встретить, так как следуя здравому смыслу такие абсолютно не связанные друг с другом данные никто не будет хранить в одной таблице. Поэтому этот пример чисто теоретический и приводится для демонстрации принципов четвертой нормальной формы.
И если говорить о реальных данных, то нормализация до четвертой нормальной формы, как и до всех последующих, в современном мире практически не встречается. Если четвертую нормальную форму еще как-то можно представить и даже встретить данные, нормализованные до этой формы, то встретить данные, нормализованные до 5 или 6 нормальной формы, практически невозможно.
Вы можете спросить, а почему не нормализуют данные до 5 или 6 нормальной формы? Ведь каждая нормальная форма устраняет определенные аномалии, и если сделать полностью нормализованную базу данных, то по сути она будет идеальная, не содержащая ни одной аномалии, это же хорошо.
Да, совершенно верно, база данных не будет содержать аномалий, но давайте вспомним, какие преимущества нам дает нормализация.
Обычно во всех источниках приводится два основных глобальных преимущества:
- Устранение аномалий
- Повышение производительности
Если с устранением аномалий все ясно, т.е. в полностью нормализованной базе данных их не будет и это хорошо, то с повышением производительности не все так однозначно.
Да, нормализация повышает производительность, но только где-то до 3 нормальной формы. Начиная с 4 нормальной формы, производительность увеличиваться не будет, более того, с каждой новой формой производительность будет значительно снижаться, не говоря уже о том, что с нормализованной базой данных до 5 или 6 нормальной формы будет крайне сложно и неудобно работать и сопровождать ее, ведь с каждой новой формой мы значительно увеличиваем количество таблиц в базе данных.
Поэтому процесс нормализации не является строго обязательным, т.е. не нужно нормализовать базу данных, только для того чтобы она была нормализована.
В процессе проектирования базы данных необходимо следовать здравому смыслу и найти баланс между отсутствием аномалий и приемлемой производительностью.
Полностью нормализованная база данных – это плохая база данных.
После того как мы привели таблицы базы данных к четвертой нормальной форме, мы можем переходить к приведению таблиц до пятой нормальной формы (5NF). Описание, требования и пример приведения таблиц до пятой нормальной формы мы рассмотрим в следующем материале.
На сегодня это все, надеюсь, материал был Вам полезен, пока!
Нравится43Не нравится
Заключение
Продолжать заниматься нормализацией можно и дальше: существуют 4NF, 5NF и DKNF (Domain Key Normal Form). Использование четырех уровней нормализации, рассмотренных в этой статье, является вполне достаточным в большинстве случаев проектирования баз данных. Таблицы могут быть нормализованы и до более высоких типов, но на практике это бывает не всегда возможно. Недостатком при стремлении к более высоким уровням нормализации является то, что таблицы могут быть разложены на более меньшие, чтобы отразить все возможные зависимости.
В результате получается, что даже для простого поиска по базе данных, требуется делать множество операций объединения таблиц. Это является слишком «дорогостоящей» процедурой и приводит к снижению производительности. Тем не менее, использовать четыре уровня нормализации баз данных, описанные в этой статье, не только желательно, но и необходимо в большинстве случаев.
Источник статьи — Источник статьи — http://www.developer.com/db/understanding-database-normalization.html