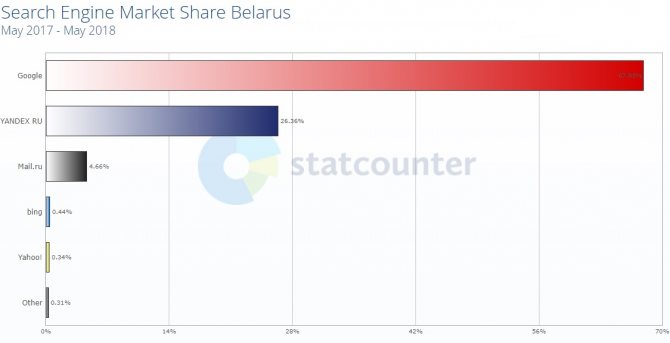
Какие бывают базы данных
Содержание:
- PostgreSQL
- Рейтинг
- Отношения между таблицами
- Общая система типов
- Шаг 2. Избавляемся от дубликатов в столбцах
- Что такое программное обеспечение баз данных?
- Типы систем [ править | править код ]
- Индексы и индексация таблиц
- Что такое SQL?
- Особенности реляционных данных
- Поле
- Основные черты [ править | править код ]
- Сравниваем три модели баз данных
- Нормализация баз данных
- MEMORY (HEAP)
- Виды баз данных
- О выборе NoSQL-баз данных
- Что такое система управления базами данных (СУБД)?
PostgreSQL
PostgreSQL является еще одним выдающимся решением с открытым исходным кодом, работающим во всех основных операционных системах, включая Linux, UNIX (AIX, BSD, HP-UX, SGI IRIX, Mac OS X, Solaris, Tru64) и Windows. PostgreSQL полностью отвечает принципам ACID (атомарность, согласованность, изолированность, устойчивость).
Достоинства
- Возможность создания пользовательских типов данных и методов запросов;
- Среда разработки баз данных выполняет хранимые процедуры более чем на десятке языков программирования: Java, Perl, Python, Ruby, Tcl, C/C ++ и собственный PL/pgSQL;
- GiST (система обобщенного поиска): объединяет различные алгоритмы сортировки и поиска: B-дерево, B+-дерево, R-дерево, деревья частичных сумм и ранжированные B+ -деревья;
- Возможность создания для большего параллелизма без изменения кода Postgres, например, CitusDB.
Недостатки
- Система MVCC требует регулярной «чистки»: проблемы в средах с высокой скоростью транзакций;
- Разработка осуществляется обширным сообществом: слишком много усилий для улучшений.
Рейтинг
Итак, рейтинг 10 наиболее популярных баз данных, согласно ресурсу DB-Engines, выглядит следующим образом:
- Oracle;
- MySQL;
- Microsoft SQL Server;
- PostgreSQL;
- MongoDB;
- DB2;
- Cassandra;
- Microsoft Access;
- Redis;
- SQLite.
Итого, 7 из 10 представителей рейтинга – реляционные базы данных, а также по одному экземпляру документоориентированной БД (MongoDB), с распределёнными значениями (Cassandra) и использующей подход «ключ-значение» (Redis). Таким образом, на сегодняшний день доминирование реляционных баз данных неоспоримо, но что будет завтра?
Для ответа на этот вопрос обратимся на этом же ресурсе к разделу тренды. Если брать отметки времени в более чем в 2 или 4 года, то наибольший рост демонстрирует подход с использованием теории графов. В то же время за последний год максимальный рост популярности продемонстрировали БД на основе временных данных. Это относительно новый подход, он также считается NoSQL, преимущество сводится к созданию структуры на основе дат или временных диапазонов. На данный момент наиболее популярным представителем Time Series БД является InfluxDB.
А какие базы данных используете вы? И какая на ваш взгляд наиболее перспективная NoSQL БД?
Отношения между таблицами
Чтобы база данных стала реляционной, одних данных мало. Между ними нужны еще и связи (те самые relations, от которых и пошло слово «реляционный»).
Для связи между таблицами служит так называемый внешний ключ (foreign key). Название довольно точно выражает его суть. Если в таблице A есть столбец для хранения первичного ключа таблицы B, то такой столбец и называется внешним ключом. Первичные и внешние ключи устанавливают связи между таблицами, превращая набор таблиц в цельную конструкцию — реляционную базу данных.
Приведу пример. Допустим, мы создали еще одну простую таблицу — справочник товаров. Назовем ее GOODS.
| Товарный справочник GOODS | ||||
| ID | NAME | PRICE | UNIT | COUNTRY |
| 1 | Яблоки | 50.00 | кг | Россия |
| 2 | Груши | 60.40 | кг | Франция |
| 3 | Апельсины | 40.00 | кг | Марокко |
| 4 | Макароны | 21.00 | шт | Франция |
| 5 | Кефир | 25.30 | шт | Россия |
| 6 | Молоко | 30.50 | шт | Россия |
Ее колонки: ID — первичный ключ, NAME — название товара, PRICE — его цена, UNIT — краткое название единицы измерения, COUNTRY — название страны-производителя.
Хорошо ли построена такая таблица? Вроде бы всем упоминавшимся выше принципам она удовлетворяет: уникальные имена столбцов с однородными данными, строки с уникальным первичным ключом. Казалось бы, все на месте. Тем не менее построена она непрофессионально. Здесь мы подходим к принципам, о которых я еще не упоминал, — к понятию о нормализации таблиц. Суть в том, чтобы всюду, где только можно, избегать избыточности в хранении данных путем выделения их в отдельные таблицы.
Посмотрим на нашу таблицу GOODS. Чем она плоха? Представьте себе, что завтра придется изменить название какой-нибудь страны. Такое случается часто. Бирма когда-то меняла свое название на Мьянму, Польша — на Польскую Республику. Хочется ли вам менять огромное количество строк во всех таблицах, где эти страны упоминаются? Представьте также, что вас попросят отобрать запросом весь штучный товар. Можете ли вы быть уверены в том, что оператор всюду набил эту аббревиатуру правильно и одинаково? Скорее всего, окажется, что в таблице встречаются все мыслимые вариации: «шт», «Шт», «шт.», «штук» и «штуки».
Думаю, проблема понятна. Выходом из этой ситуации будет выделение из нее двух других таблиц: справочника стран (COUNTRIES) и справочника единиц измерений (UNITS).
| Справочник единиц измерения UNITS | ||
| ID | NAME | SHORT_NAME |
| 1 | Штуки | шт |
| 2 | Килограммы | кг |
Сам справочник товаров GOODS будет теперь выглядеть совершенно по-другому (см. таблицу).
| Товарный справочник GOODS после нормализации | ||||
| ID | NAME | PRICE | UNIT_ID | COUNTRY_ID |
| 1 | Яблоки | 50.00 | 2 | 1 |
| 2 | Груши | 60.40 | 2 | 2 |
| 3 | Апельсины | 40.00 | 2 | 3 |
| 4 | Макароны | 21.00 | 1 | 2 |
| 5 | Кефир | 25.30 | 1 | 1 |
| 6 | Молоко | 30.50 | 1 | 1 |
Что изменилось? Вместо столбцов с названиями единиц измерения и стран появились столбцы UNIT_ID и COUNTRY_ID с кодами, отсылающими нас к другим таблицам. Это и есть внешние ключи. Что означает значение 2 в столбце UNIT_ID? Оно означает, что интересующая нас информация по единице измерения находится той строке таблицы UNITS, где ID = 2. Достаточно заглянуть в этот справочник, чтобы убедиться, что называется эта единица полностью «штуки», а кратко — «шт».
Объяснение всех видов и принципов нормализации выходит далеко за рамки данной статьи. Главное — почувствовать общие принципы. Единожды научившись строить базы данных правильно, вы уже не сможете иначе. Для этого не обязательно знать теорию в полном объеме — зачастую здравого смысла и интуиции бывает достаточно.
Вернемся к нашей маленькой базе данных. Ну хорошо, нормализовали мы таблицу. Сможем теперь менять названия стран, не исправляя всю таблицу. Замечательно. Но как теперь увидеть эти названия? Ведь в справочнике товаров появились коды, и таблица сразу потеряла свою наглядность.
Вот тут-то мы и подходим к понятию уже не раз упоминавшихся запросов, которые, используя связи, извлекают из них нужную информацию и выдают нам опять же в виде так называемой отчетной таблицы.
Общая система типов
Важной особенностью работы с базой данных является то, что в «1С:Предприятии 8» реализована общая система типов языка и полей баз данных. Иными словами, разработчик одинаковым образом определяет поля базы данных и переменные встроенного языка и одинаковым образом работает с ними.. Этим система «1С:Предприятие 8» выгодно отличается от универсальных инструментальных средств
Обычно, при создании бизнес-приложений с использованием универсальных сред разработки, используются отдельно поставляемые системы управления базами данных. А это значит, что разработчику приходится постоянно заботиться о преобразованиях между типами данных, поддерживаемыми той или иной системы управления базами данных, и типами, поддерживаемыми языком программирования.
Этим система «1С:Предприятие 8» выгодно отличается от универсальных инструментальных средств. Обычно, при создании бизнес-приложений с использованием универсальных сред разработки, используются отдельно поставляемые системы управления базами данных. А это значит, что разработчику приходится постоянно заботиться о преобразованиях между типами данных, поддерживаемыми той или иной системы управления базами данных, и типами, поддерживаемыми языком программирования.
Шаг 2. Избавляемся от дубликатов в столбцах
Как было оговорено выше, столбцы “username” и “following_username” содержат дубликаты данных. Они возникли в результате того, что я хотел отобразить отношения между твиттами и пользователями. Давайте улучшим нашу структуру БД, разделив существующую таблицу на две: в одной будем хранить информацию, а в другой — отношения между записями.
Поскольку @Brett_Englebert подписан на @RealSkipBayless, то в таблице “following” отобразим это следующим образом: имя @Brett_Englebert поместим в колонку “from_user”, а @RealSkipBayless в “to_user.” Давайте посмотрим, как будет выглядеть таблица “following” после разделения Таблицы 1:
Таблица 2. following
| from_user | to_user |
|---|---|
| _DreamLead | Scootmedia |
| _DreamLead | MetiersInternet |
| GunnarSvalander | klout |
| GunnarSvalander | zillow |
| GEsoftware | DayJobDoc |
| GEsoftware | byosko |
| adrianburch | CindyCrawford |
| adrianburch | Arjantim |
| AndyRyder | MichaelDell |
| AndyRyder | Yahoo |
| Brett_Englebert | RealSkipBayless |
| Brett_Englebert | stephenasmith |
| NimbusData | dellock6 |
| NimbusData | rohitkilam |
| SSWUGorg | drsql |
| SSWUGorg | steam_games |
Таблица 3. users
| full_name | username | text | created_at |
|---|---|---|---|
| Boris Hadjur | _DreamLead | What do you think about #emailing #campaigns #traffic in #USA? Is it a good market nowadays? do you have #databases? | Tue, 12 Feb 2013 08:43:09 +0000 |
| Gunnar Svalander | GunnarSvalander | Bill Gates Talks Databases, Free Software on Reddit http://t.co/ShX4hZlA #billgates #databases | Tue, 12 Feb 2013 07:31:06 +0000 |
| GE Software | GEsoftware | RT @KirkDBorne: Readings in #Databases: excellent reading list, many categories: http://t.co/S6RBUNxq via @rxin Fascinating. | Tue, 12 Feb 2013 07:30:24 +0000 |
| Adrian Burch | adrianburch | RT @tisakovich: @NimbusData at the @Barclays Big Data conference in San Francisco today, talking #virtualization, #databases, and #flash memory. | Tue, 12 Feb 2013 06:58:22 +0000 |
| Andy Ryder | AndyRyder5 | http://t.co/D3KOJIvF article about Madden 2013 using AI to prodict the super bowl #databases #bus311 | Tue, 12 Feb 2013 05:29:41 +0000 |
| Andy Ryder | AndyRyder5 | http://t.co/rBhBXjma an article about privacy settings and facebook #databases #bus311 | Tue, 12 Feb 2013 05:24:17 +0000 |
| Brett Englebert | Brett_Englebert | #BUS311 University of Minnesota’s NCFPD is creating #databases to prevent “food fraud.” http://t.co/0LsAbKqJ | Tue, 12 Feb 2013 01:49:19 +0000 |
| Brett Englebert | Brett_Englebert | #BUS311 companies might be protecting their production #databases, but what about their backup files? http://t.co/okJjV3Bm | Tue, 12 Feb 2013 01:31:52 +0000 |
| Nimbus Data Systems | NimbusData | @NimbusData CEO @tisakovich @BarclaysOnline Big Data conference in San Francisco today, talking #virtualization, #databases,& #flash memory | Mon, 11 Feb 2013 23:15:05 +0000 |
| SSWUG.ORG | SSWUGorg | Don’t forget to sign up for our FREE expo this Friday: #Databases, #BI, and #Sharepoint: What You Need to Know! http://t.co/Ijrqrz29 | Mon, 11 Feb 2013 22:15:37 +0000 |
Уже лучше. Теперь в таблице “users” (Таблица 3) у нас хранится только информация о твиттах, а в таблице following (Таблица 2) — зависимость пользователей.
Основатель теории реляционных баз данных, Эдгар Кодд, назвал бы этот процесс (удаления повторений из столбцов таблиц) приведением БД к первой нормальной форме.
Что такое программное обеспечение баз данных?
Программное обеспечение базы данных используется для создания, редактирования и обслуживания файлов и записей базы данных, что упрощает создание файлов и записей, ввод данных, редактирование, обновление и создание отчетов. Программное обеспечение также обеспечивает хранение данных, резервное копирование и отчетность, управление множественным доступом и безопасность. Сильная безопасность базы данных особенно важна сегодня, поскольку кража данных становится все более частой. Программное обеспечение баз данных иногда также называют «системой управления базами данных» (СУБД).
Программное обеспечение баз данных упрощает управление данными, позволяя пользователям хранить данные в структурированной форме, а затем получать к ним доступ. Обычно он имеет графический интерфейс, помогающий создавать данные и управлять ими, а в некоторых случаях пользователи могут создавать свои собственные базы данных с помощью программного обеспечения для баз данных.
Типы систем [ править | править код ]
Описание схемы данных в случае использования NoSQL-решений может осуществляться через использование различных структур данных: хеш-таблиц, деревьев и других.
В зависимости от модели данных и подходов к распределённости и репликации в NoSQL-движении выделяются четыре основных типа систем: «ключ — значение» (англ. key-value store ), документоориентированные ( document store ), «семейство столбцов» ( column-family store ), графовые.
Ключ — значение
Модель «ключ — значение» является простейшим вариантом, использующим ключ для доступа к значению. Такие системы используются для хранения изображений, создания специализированных файловых систем, в качестве кэшей для объектов, а также в системах, спроектированных с прицелом на масштабируемость. Примеры таких хранилищ — Berkeley DB, MemcacheDB , Redis, Riak, Amazon DynamoDB .
Семейство столбцов
Другой тип систем — «семейство столбцов», прародитель этого типа — система Google BigTable. В таких системах данные хранятся в виде разреженной матрицы, строки и столбцы которой используются как ключи. Типичным применением этого типа СУБД является веб-индексирование, а также задачи, связанные с большими данными, с пониженными требованиями к согласованности. Примерами СУБД данного типа являются: Apache HBase, Apache Cassandra, ScyllaDB , Apache Accumulo , Hypertable .
Системы типа «семейство столбцов» и документно-ориентированные системы имеют близкие сценарии использования: системы управления содержимым, блоги, регистрация событий. Использование временных меток позволяет использовать этот вид систем для организации счётчиков, а также регистрации и обработки различных данных, связанных со временем .
В отличие от столбцового хранения (англ. column-oriented DBMS ), применяемого в некоторых реляционных СУБД, хранящих данные по столбцам в сжатом виде, в связи с чем эффективные для OLAP-сценариев, модель «семейство столбцов» хранит данные построчно, и обеспечивает высокую производительность, прежде всего, в оперативных сценариях, тогда как для запросов, требующих обхода большого объёма данных с агрегацией результатов, как правило, неэффективна .
Документоориентированная СУБД
Документоориентированные СУБД служат для хранения иерархических структур данных. Находят своё применение в системах управления содержимым, издательском деле, документальном поиске. Примеры СУБД данного типа — CouchDB, Couchbase, MongoDB, eXist, Berkeley DB XML .
Графовая СУБД
Графовые СУБД применяются для задач, в которых данные имеют большое количество связей, например, социальные сети, выявление мошенничества. Примеры: Neo4j, OrientDB, AllegroGraph , Blazegraph , InfiniteGraph, FlockDB, Titan .
Так как рёбра графа материализованы (англ. materialized ), то есть, являются хранимыми, обход графа не требует дополнительных вычислений (как соединение в SQL), но для нахождения начальной вершины обхода требуется наличие индексов. Графовые СУБД как правило поддерживают AC >GraphQL .
Индексы и индексация таблиц
Представьте себе, что ваш приятель загадал число между 1 и 1000 и просит вас угадать его за минимальное число попыток, сообщая лишь о том, в большую или меньшую сторону вы ошиблись. Как вы поступите? Очевидно, предложите при первой попытке версию 500 (то есть начнете с середины). Если он ответит: «меньше», — предложите 250. Если «больше» — 750. Так, разбивая интервалы пополам, вы уложитесь в 10 попыток (ведь 210 > 103). Если бы приятель загадал число в пределах миллиарда, то количество попыток уложилось бы в 30 (230 > 109).
Угадывая число, вы проводили поиск примерно так, как ведут его системы баз данных, использующие индексы. Понятное дело, их работа гораздо сложнее, но главная идея именно в этом — за небольшое число попыток найти нужное значение из миллиардов возможных. Поля, по которым вам часто придется делать в базе поиск, фильтрацию или связывание таблиц между собой, есть смысл проиндексировать, то есть создать специальный связанный с таблицей объект, содержащий информацию, необходимую для вышеописанного быстрого поиска.
Как это делается практически? Поясню на примерах. Допустим, вас часто просят отобрать информацию о товарах российского производства. Чтобы по колонке COUNTRY_ID таблицы GOODS фильтрация производилась быстрее, создадим по ней индекс с именем IDX_GOODS_COUNTRY:
Если в будущем вы передумаете использовать созданный индекс, то без труда его сможете удалить:
Что такое SQL?
SQL — это самый распространенный язык запросов к базам данных. Расшифровывается аббревиатура так: Structured Query Language — «язык структурированных запросов».
Он создавался затем, чтобы привести работу с различными типами баз данных (а их сейчас известно множество) к единому стандарту, сделать работу по управлению данными независимой ни от аппаратной, ни от программной части компьютера.
Последнее удалось не в полной мере, так как в SQL различных систем на какой-то стадии появились расхождения, поскольку разработка SQL-управляемых систем часто опережает формирование стандартов. Но в целом идею такой стандартизации можно считать реализованной.
Собственно, именно поэтому базы данных профессионально сделанных сайтов, как правило, реляционны и SQL-управляемы.
Особенности реляционных данных
Главная особенность — все объекты хранятся в виде набора 2-мерных таблиц. Каждая таблица включает в себя набор столбцов, где указываются следующие параметры:- название;- тип данных (число, строка и т. д.).
Вторая важная особенность заключается в том, что число столбцов фиксировано. Это значит, что структура БД известна заранее, при этом количество рядов либо строк данных практически не ограничено. Грубо говоря, строки в реляционных БД — есть объекты, хранимые в базе.
По большему счёту, БД — это абстрактное понятие, а в случае с реляционной структурой таблица — есть не более чем удобный способ хранения информации. Причём набор таблиц превращается в базу данных тогда, когда он связан логически. А чтобы этим всем управлять, используют СУБД. Классический пример СУБД — система управления MySQL. Иными словами, СУБД MySQL — есть программное воплощение математических идей.
Поле
Поле представляет собой элемент пользовательского интерфейса, предназначенный для ввода данных. Многие программные приложения включают текстовые поля, которые позволяют вводить информацию с помощью клавиатуры или сенсорного экрана. Веб-сайты часто включают поля формы, которые посетитель может использовать для ввода и отправки информации.
В программах термины «поле» и «текстовое поле» могут использоваться взаимозаменяемо. Например, процессор может предоставить несколько параметров форматирования, таких как размер шрифта, межстрочный интервал и поля страницы. Каждый параметр включает текстовое поле, в котором пользователь может вручную ввести пользовательские настройки. Многие приложения также включают в себя окно поиска, которое позволяет искать содержимое одного или нескольких документов.
При посещении веб-сайта этот инструмент может предоставить форму, которая позволяет вводить данные, такие как платежный адрес или регистрационная информация. Каждое однострочное текстовое поле в веб-форме называется «окном ввода» и определяется <input type = «text»> в HTML. Поля с более чем одной строкой называются «текстовыми областями», создаются с помощью тега <textarea>. Также существуют типы полей базы данных, которые включают два для ввода имени пользователя и пароля. Большинство полей пароля определяются как <input type = «password»>, который скрывает символы по мере ввода.
Базы данных также включают поля. Каждая строка или «запись» в таблице может содержать несколько элементов. Столбцы таблицы определяют, какие окна доступны в каждой строке. Поэтому конкретная комбинация столбцов и строк (например, Row: 101, Column: Name) определяет конкретное поле. Отдельные части можно искать и изменять с помощью стандартных SQL-запросов.

Основные черты [ править | править код ]
Традиционные СУБД ориентируются на требования AC >atomicity ), согласованность (англ. consistency ), изолированность (англ. isolation ), надёжность (англ. durability ), тогда как в NoSQL вместо AC > :
- базовая доступность (англ. basic availability ) — каждый запрос гарантированно завершается (успешно или безуспешно).
- гибкое состояние (англ. soft state ) — состояние системы может изменяться со временем, даже без ввода новых данных, для достижения согласования данных.
- согласованность в конечном счёте (англ. eventual consistency ) — данные могут быть некоторое время рассогласованы, но приходят к согласованию через некоторое время.
Термин «BASE» был предложен Эриком Брюером, автором теоремы CAP, согласно которой в распределённых вычислениях можно обеспечить только два из трёх свойств: согласованность данных, доступность или устойчивость к разделению .
Разумеется, системы на основе BASE не могут использоваться в любых приложениях: для функционирования биржевых и банковских систем использование транзакций является необходимостью. В то же время, свойства AC > . Таким образом, проектировщики NoSQL-систем жертвуют согласованностью данных ради достижения двух других свойств из теоремы CAP . Некоторые СУБД, например, Riak, позволяют настраивать требуемые характеристики доступности-согласованности даже для отдельных запросов путём задания количества узлов, необходимых для подтверждения успеха транзакции.
Решения NoSQL отличаются не только проектированием с учётом масштабирования. Другими характерными чертами NoSQL-решений являются :
- Применение различных типов хранилищ .
- Возможность разработки базы данных без задания схемы .
- Линейная масштабируемость (добавление процессоров увеличивает производительность) .
- Инновационность: «не только SQL» открывает много возможностей для хранения и обработки данных .
Сравниваем три модели баз данных
Первая, иерархическая модель данных, имеет древовидную структуру («родитель-потомок»), и поддерживает только отношения типа «один к одному» или «один ко многим». Эта модель позволяет быстро получать данные, но не отличается гибкостью. Иногда роль элемента (родителя или потомка) неясна и не подходит для иерархической модели.
Вторая, сетевая модель данных, имеет более гибкую структуру, чем иерархическая модель данных, и поддерживает отношения «многие ко многим». Но быстро становится слишком сложной и неудобной для управления.
Третья модель — реляционная — более гибкая, чем иерархическая и проще для управления, чем сетевая. Реляционная модель сегодня используется чаще всего.
Объект в реляционной модели баз данных определяется как позиция информации, хранимой в базе данных. Объект может быть осязаемым или неосязаемым. Примером осязаемого объекта может быть сотрудник организации, а примером неосязаемой сущности — учётная запись покупателя. Объекты определяются атрибутами — информационным отображением свойств объекта. Эти атрибуты также известны как столбцы, а группа столбцов — как ряд. Ряд также можно определить как экземпляр объекта.
Объекты связываются отношениями, основные типы которых можно определить следующим образом:
«Один к одному»
В этом виде отношений один объект связан с другим. Например, Менеджер -> Отдел.
У каждого менеджера может быть только один отдел, и наоборот.
«Один ко многим»
В моделях данных отношение одного объекта с несколькими. Например, Сотрудник -> Отдел.
Каждый сотрудник может быть только в одном отделе, но в самом отделе может быть больше одного сотрудника.
«Многие ко многим»
В заданный момент времени объект может быть связан с любым другим. Например, Сотрудник -> Проект.
Сотрудник может участвовать в нескольких проектах, и каждый проект может объединять несколько сотрудников.
В реляционной модели объекты и их отношения представлены двухмерным массивом или таблицей.
Каждая таблица представляет объект.
Каждая таблица состоит из рядов и столбцов.
Отношения между объектами представлены столбцами.
Каждый столбец представляет атрибут объекта.
Значения столбцов выбираются из области или набора всех возможных значений.
Столбцы, которые используются для связи объектов, называются ключевыми. Есть два типа ключей — первичные и внешние.
Первичные служат для однозначного определения объекта. Внешний ключ — это первичный ключ одного объекта, существующий как атрибут в другой таблице.
Преимущества реляционной модели данных:
- Простота использования.
- Гибкость.
- Независимость данных.
- Безопасность.
- Простота практического применения.
- Слияние данных.
- Целостность данных.
Недостатки:
- Избыточность данных.
- Низкая производительность.
Нормализация баз данных
Всю информацию, содержащуюся в базе, можно разместить в одной таблице, но такая структура данных является неэффективной, поскольку в этой таблице будет достаточно много повторяющихся данных. Такая организация данных приведет к следующим проблемам:
- наличие повторяющихся данных приведет к неоправданному увеличению размера файла базы данных. Кроме нерационального использования дискового пространства, это также вызовет заметное замедление работы приложения;
- ввод пользователем большого количества повторяющейся информации неизбежно приведет к возникновению ошибок;
- изменение одного из часто используемых параметров потребует значительных усилий по корректировке каждой записи, содержащей эти данные.
Процесс уменьшения избыточности информации в базе данных посредством разделения ее на несколько связанных друг с другом таблиц и называется нормализацией данных. Существует шесть уровней нормализации базы данных, которые получили название нормальных форм.
- Первая нормальная форма
- запрещает повторяющиеся столбцы (содержащие одинаковую по смыслу информацию);
- запрещает множественные столбцы (содержащие значения типа списка);
- требует определить первичный ключ для таблицы, то есть тот столбец или комбинацию столбцов, которые однозначно определяют каждую строку.
Вторая нормальная форма
Вторая нормальная форма требует, чтобы неключевые столбцы таблиц зависили от первичного ключа в целом, но не от его части. Если таблица находится в первой нормальной форме и первичный ключ у нее состоит из одного столбца, то она находится и во второй нормальной форме.
Третья нормальная форма
Чтобы таблица находилась в третьей нормальной форме, необходимо, чтобы неключевые столбцы в ней зависели только от первичного ключа. Самая распространённая ситуация в данном контексте — это расчётные столбцы, значения которых можно получить путём каких-либо манипуляций с другими столбцами таблицы. Для приведения таблицы в третью нормальную форму такие столбцы из таблиц необходимо удалять.
Нормальная форма Бойса-Кодда
Нормальная форма Бойса-Кодда требует, чтобы в таблице был только один потенциальный первичный ключ. Чаще всего у таблиц, находящихся в третьей нормальной форме, так и бывает, но не всегда. Если обнаружился второй столбец (комбинация столбцов), позволяющий однозначно идентифицировать строку, то для приведения к нормальной форме Бойса-Кодда такие данные надо вынести в отдельную таблицу.
Четвёртая нормальная форма
Для приведения таблицы, находящейся в нормальной форме Бойса-Кодда, к четвёртой нормальной форме необходимо устранить имеющиеся в ней многозначные зависимости. То есть обеспечить, чтобы вставка или удаление любой строки таблицы не требовала бы модификации других строк этой же таблицы.
Пятая нормальная форма
Формальное определение пятой нормальной формы таково: это форма, в которой устранены зависимости соединения. В большинстве случаев практической пользы от нормализации таблиц до пятой нормальной формы не наблюдается.Нормализация базы данных позволяет устранить избыточность, дублирование данных. Как следствие, значительно сокращается вероятность появления противоречивых данных, облегчается администрирование базы и обновление информации в ней, сокращается объём дискового пространства. Зачастую, чтобы извлечь информацию из нормализованной базы данных, приходится конструировать очень сложные запросы, которые увеличивают нагрузку на системные ресурсы из-за большого количества соединений таблиц. Поэтому, чтобы увеличить скорость выборки данных и упростить программирование запросов, нередко приходится идти на выборочную денормализацию базы.
MEMORY (HEAP)
Тип таблиц MEMORY хранится в оперативной памяти, поэтому все запросы к такой таблице выполняются очень быстро. Недостатком является полная потеря данных в случае сбоя работы сервера, поэтому в таблице данного типа хранят только временную информацию, которую можно легко восстановить заново.
При создании таблицы типа MEMORY она ассоциируется с одним-единственным файлом, имеющим расширение frm, в котором определяется структура таблицы.
При остановке или перезапуске сервера данный файл остается в текущей азе данных, но содержимое таблицы, которое хранится в оперативной памяти, теряется.
Ограничения MEMORY таблиц:
- Индексы используются только в операциях сравнения совместимо с операторами = и <=>, с другими операторами, такими как > или < индексирование столбцов не имеет смысла
- Возможно использование только неуникальных индексов.
- Можно использовать записи фиксированной длины, поэтому в них не допустимы столбцы типов TEXT и BLOD.
- В версиях, предшествующих MySQL 4.0.2, не поддерживается индексирование столбцов, содержащих NULL-значения.
Виды баз данных
- Фактографическая – содержит краткую информацию об объектах некоторой системы в строго фиксированном формате;
- Документальная – содержит документы самого разного типа: текстовые, графические, звуковые, мультимедийные;
- Распределённая – база данных, разные части которой хранятся на различных компьютерах, объединённых в сеть;
- Централизованная – база данных, хранящихся на одном компьютере;
- Реляционная – база данных с табличной организацией данных;
- Неструктурированная (NoSQL) — база данных, в которой делается попытка решить проблемы масштабируемости и доступности за счёт атомарности (англ. atomicity) и согласованности данных, но не имеющих четкой (реляционной) структуры.
Одно из основных свойств БД – независимость данных от программы, использующих эти данные. Работа с базой данных требует решения различных задач, основные из них следующие:
- создание базы;
- запись данных в базу;
- корректировка данных;
- выборка данных из базы по запросам пользователя.
Задачи этого списка называются стандартными.
Следующее понятие, связанное с базой данных: программа для работы с базой данных – это программа, которая обеспечивает решение требуемого комплекса задач. Любая подобная программа должна уметь решать все задачи стандартного набора.
База данных в разных системах имеет различную структуру.
В ПВЭМ обычно используются реляционные БД – в таких базах файл является по структуре таблицей. В ней столбцы называются полями, строки – записями.
В БД содержатся банные некоторого множества объктов. Каждая запись содержит данные одного объекта. Каждая такая БД определяется именем файла, списком полей, шириной полей. Например, БД Школа (Ученик, Класс, Адрес).
Примером БД может служить расписание движения поездов или автобусов. Здесь каждая строчка – запись отражает данные строго одного объекта. База включает поля: номер рейса, маршрута следования, время отправления и т.д.
Классическим примером БД является и телефонный справочник. Запрос к базе данных – это предписание, указывающее, какие данные пользователь желает получить из базы.
Некоторые запросы могут представлять собой серьёзную задачу, для решения которой потребляется составлять сложную программу. Например, запрос к базе – автобусному расписанию: определить разницу в среднем интервале отправления автобусов из Ростова в Таганрог и из Ростова в Шахты.
Объекты для работы с базами данных
Для создания приложения, позволяющего просматривать и редактировать базы данных, нам потребуется три звена:
- набор данных
- источник данных
- визуальные элементы управления
В нашем случае эта триада реализуется в виде:
- Table
- DataSource
- DBGrid
Table подключается непосредственно к таблице в базе данных. Для этого нужно установить псевдоним базы в свойстве DataBaseName и имя таблицы в свойстве TableName, а затем активизировать связь: свойство .
Однако, поскольку Table является невизуальным компонентом, хотя связь с базой и установлена, пользователь не в состоянии увидеть какие – либо данные. Поэтому необходимо добавить визуальные компоненты, отображающие эти данные. В нашем случае это сетка DBGrid. Сетка сама по себе «не знает», какие данные ей нужно отображать, её нужно подключить к Table, что и делается через компонент – посредник .
А зачем нужен компонент – посредник? Почему бы сразу не подключаться к Table?
Допустим, несколько визуальных компонентов – таблица, поля ввода и т.п. подключены к таблице. А нам нужно быстро переключить их все на другую подобную таблицу. С DataSource это сделать несложно — достаточно просто поменять свойство t, а вот без пришлось бы менять указатели у каждого компонента.
Приложения баз данных – нить, связывающая БД и пользователя:
БД => набор данных –=> источник данных => визуальные компоненты => пользователь
Набор данных:
- Table(таблица, навигационный доступ)
- Query(запрос, реляционный доступ)
Визуальные компоненты:
- Сетки DBGrid, DBCtrlGrid
- Навигатор DBNavigator
- Всяческие аналоги Lable, Editи т.д.
- Компоненты подстановки
О выборе NoSQL-баз данных
- Хранение больших объёмов неструктурированной информации. База данных NoSQL не накладывает ограничений на типы хранимых данных. Более того, при необходимости в процессе работы можно добавлять новые типы данных.
- Использование облачных вычислений и хранилищ. Облачные хранилища — отличное решение, но они требуют, чтобы данные можно было легко распределить между несколькими серверами для обеспечения масштабирования. Использование, для тестирования и разработки, локального оборудования, а затем перенос системы в облако, где она и работает — это именно то, для чего созданы NoSQL базы данных.
- Быстрая разработка. Если вы разрабатываете систему, используя agile-методы, применение реляционной БД способно замедлить работу. NoSQL базы данных не нуждаются в том же объёме подготовительных действий, которые обычно нужны для реляционных баз.
Что такое система управления базами данных (СУБД)?
База данных обычно требует комплексного программного обеспечения базы данных, известного как система управления базами данных (СУБД). СУБД служит интерфейсом между базой данных и ее конечными пользователями или программами, позволяя пользователям извлекать, обновлять и управлять организацией и оптимизацией информации. СУБД также облегчает надзор и контроль над базами данных, позволяя выполнять различные административные операции, такие как мониторинг производительности, настройка, резервное копирование и восстановление.
Некоторые примеры популярных программ для баз данных или СУБД включают MySQL, Microsoft Access, Microsoft SQL Server, FileMaker Pro, Oracle Database и dBASE.