Sql и nosql: инь и ян в мире баз данных
Содержание:
- Создание структуры таблицы БД Access командой CREATE TABLE языка SQL
- 1 Анализ предметной области
- История
- Разница между реляционной и нереляционной базой данных
- Язык управления данными (DML)¶
- Реляционная модель
- Концептуальная модель базы данных
- Таблица как важная часть реляционной БД
- Колоночные
- Контроль за реляционной базой любого размера
- O(1) vs O(n2)
- Хранилища данных временных рядов
- Реляционные отношения (связи) между таблицами базы данных
- Системы управления базами данных
- Организация информации в реляционной базе данных
- [править] Подходы к проектированию реляционных БД (РБД)
Создание структуры таблицы БД Access командой CREATE TABLE языка SQL
Инструкция SQL (SELECT) или запрос на выборку данных из таблиц БД Access рассмотрена в работе SQL — язык доступа и управления СУБД Access. В этой статье рассмотрим инструкцию SQL (CREATE TABLE) запроса на изменение.
К этому типу запросов относятся запросы на создание таблицы, на добавление или на удаление записей в таблице и запросы на ее обновление. Структуру таблицы можно создать с помощью оператора CREATE TABLE языка SQL.
Рассмотрим создание структуры таблиц базы данных БД «Деканат» на основе модели «сущность – связь» в СУБД Access с помощью запросов SQL. Для этого создадим новую базу данных sql_training_st.mdb в приложении Access 2007.
Следует отметить, что файл новой базы данных сохраним в формате Access 2002-2003. После создания новой БД, в окне приложения будет отображаться окно БД на вкладке Режим таблицы и новая пустая таблица с именем Таблица 1 в режиме таблица.
Закрываем Таблицу1, щелкнув правой кнопкой мыши на Таблица1 в окне редактирования, и в контекстном меню выбрав команду Закрыть. Далее создадим структуру таблицы Группы аналогичную структуре таблицы Группы, созданной в Конструкторе, используя команду SQL create table.
Для этого в окне БД щелкаем левой кнопкой мыши на вкладке Создание и выбираем команду «Конструктор запросов». В результате в окне редактирования откроется объект «Запрос1» и окно диалога «Добавление таблицы». Закроем окно диалога, щелкнув левой кнопкой мыши на пиктограмме «Закрыть» в правом верхнем углу этого окна.
Затем создаем структуру таблицы «Группы», для этого выберем режим SQL, выполнив команду Вид/ Режим SQL. Удаляем появившуюся в окне запроса команду SELECT и вводим с клавиатуры следующую команду:
create table Группы (КодГруппы COUNTER CONSTRAINT PrimaryKey PRIMARY KEY, Название char(6), Курс int, Семестр int);
Сохраняем запрос с именем «Создание Группы». В результате в «Области переходов» появится несвязанный объект — «Создание Группы». После сохранения запроса необходимо выполнить этот запрос, щелкая на пиктограмме «Выполнить». В результате выполнения команды «create table Группы» в «Области переходов» появится объект — «Группы: таблицы».
Закроем окно «Создание Группы» и откроем объект – «Группы: таблица» в режиме конструктора.
Созданная с помощью запроса на изменение структура таблицы «Группы» аналогична структуре таблицы «Группы студентов», созданной в режиме «Конструктор».
Затем создаем структуру таблицы «Студенты», для этого выберем режим SQL, выполнив команду Вид/ Режим SQL. Удаляем появившуюся в окне запроса команду SELECT и вводим с клавиатуры следующую команду:
create table Студенты (КодСтудента COUNTER CONSTRAINT PrimaryKey PRIMARY KEY, КодГруппы int, Фамилия char(20), Имя char(15), Отчество char(15), Пол char(1), Дата_рождения DATE, Место_рождения MEMO, FOREIGN KEY (КодГруппы) REFERENCES Группы (КодГруппы));
Для описания связей между таблицами «Группы» и «Студенты» через поле «КодГруппы» (отношение «один-ко-многим»), а также обеспечения целостности базы данных применена запись «FOREIGN KEY (КодГруппы) REFERENCES Группы (КодГруппы)».
Сохраняем запрос с именем «Создание Студенты». В результате в «Области переходов» появится несвязанный объект — «Создание Студенты». После сохранения запроса необходимо выполнить этот запрос, щелкая на пиктограмме «Выполнить». В результате выполнения команды «create table Студенты» в «Области переходов» появится объект — «Студенты: таблицы».
Обучение в интернет, . Обратная связь
1 Анализ предметной области
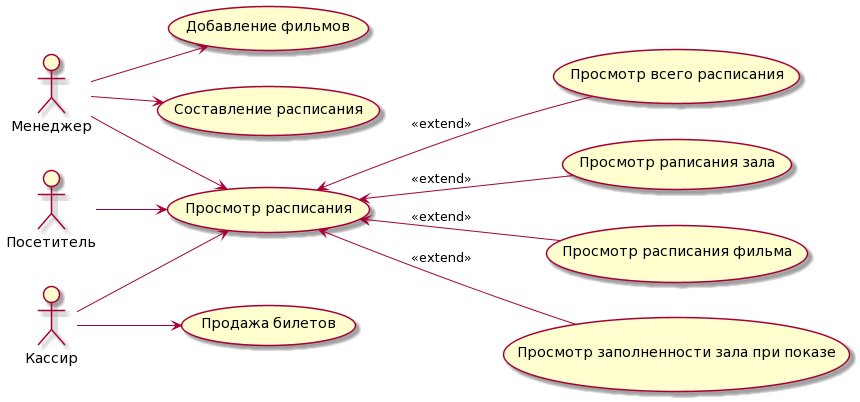
Зачастую, кинотеатр состоит из нескольких залов разной конфигурации, а посетителю предоставляется возможность выбора билета, для этого ему отображается текущее состояние зала. Выбранные места посетитель сообщает кассиру, который вводит их в систему и места помечаются как «проданные». Это «основной» сценарий использования информационной системы, однако надо учесть следующее:
- репертуар и расписание проката кинотеатра должен кто-то вносить в систему — соответствующую роль назовем «Менеджер»;
- посетитель и кассир должны иметь возможность просматривать расписание, при этом интересно расписание, начиная с некоторого момента времени (например, текущего времени). Составлять оно может по-разному:
- расписание показа всех фильмов, упорядоченное по времени;
- расписание прокатов в отдельных залах кинотеатра;
- расписание проката определенного фильма.
Из этого описания понятны основные функции системы, изображенные на рисунке с помощью нотации диаграммы прецедентов UML. На диаграмме не отображена роль администратора базы данных, так как администратор обычно взаимодействует с системой не через интерфейс, а через выполнение SQL-запросов.
Несмотря на то, что мы не будет разрабатывать интерфейс информационной системы и текстовые описания прецедентов, дальше нас будут интересовать данные, необходимые для выполнения того или иного прецедента, а для этого надо выделить и описать сущности. Иначе, невозможно определить «какие данные должен вводить менеджер при добавлении фильма». Основные сущности, данные которых потребуются во время работы, показаны на рисунке, при этом используется нотация диаграммы классов UML. Каждый прямоугольник соответствует одной сущности, внутри записаны поля и типы данных.
Каждая сущность, кроме hall_row содержит поле id, которое идентифицирует объект. У сущности hall_row поле id не нужно, так как в одном и том же зале кинотеатра (id_hall) не могут повторяться номера рядов (number).
Когда пользователь выберет зал и прокат — система должна отобразить заполненность зала, при этом надо отобразить конфигурацию зала с пометкой занятых и свободных мест. Под конфигурацией зала тут имеется ввиду, что разные залы имеют разный размер, а ряды зала могут иметь различное количество мест. Поэтому в базе данных зал (hall) составляется из рядов (hall_row), одним из параметров которых является вместимость (capacity).
История
Реляционные системы берут свое начало в математической теории множеств. Эдгар Кодд, сотрудник исследовательской лаборатории корпорации IBM в Сан-Хосе, по существу, создал и описал концепцию реляционных баз данных в своей основополагающей работе «Реляционная модель для крупных, совместно используемых банков данных» (A Relational Model of Data for Large Shared Data Banks. Communications of the ACM, июнь 1970).
Нечеткость многих терминов, используемых в сфере обработки данных, заставила Кодда отказаться от них и придумать новые или дать более точные определения существующим. Так, он не мог использовать широко распространенный термин «запись», который в различных ситуациях может означать экземпляр записи, либо тип записей, запись в стиле Кобола (которая допускает повторяющиеся группы) или плоскую запись (которая их не допускает), логическую запись или физическую запись, хранимую запись или виртуальную запись и т.д. Вместо этого он использовал термин «кортеж длины n» или просто «кортеж», которому дал точное определение.
Кодд предложил модель, которая позволяет разработчикам разделять свои базы данных на отдельные, но взаимосвязанные таблицы, что увеличивает производительность, но при этом внешнее представление остается тем же, что и у исходной базы данных. С тех пор Кодд считается отцом-основателем отрасли реляционных баз данных. Кодд сформулировал 12 правил для реляционных баз данных, большинство которых касаются целостности и обновления данных, а также доступа к ним.
Разница между реляционной и нереляционной базой данных
Определение
Реляционная база данных — это база данных, основанная на реляционной модели данных, предложенной EF Codd в 1970 году. Нереляционная база данных, с другой стороны, представляет собой тип базы данных, которая обеспечивает механизм для хранения и извлечения данных, которые моделируются таким образом, кроме табличных отношений, используемых в реляционных базах данных.
Synonms
Реляционные базы данных также называются базами данных SQL, в то время как нереляционные базы данных также называются базами данных NoSQL.
присоединяется
Разница между реляционной и нереляционной базой данных заключается в том, что таблицы в реляционной базе данных могут быть объединены. С другой стороны, в нереляционной базе данных нет единой концепции.
Типы
Другое различие между реляционной и нереляционной базой данных состоит в том, что реляционные базы данных не могут быть классифицированы далее. Напротив, базы данных ключ-значение, документы, столбцы и графы являются типами нереляционных баз данных.
использование
Реляционные базы данных помогают выполнять сложные запросы. Кроме того, они обеспечивают гибкость и помогают анализировать данные. Нереляционные базы данных хорошо работают с большим количеством данных. Кроме того, они уменьшают задержку и улучшают пропускную способность. Следовательно, это еще одно различие между реляционной и нереляционной базой данных.
Примеры
MySQL, SQLite3 и PostgreSQL — это некоторые СУБД, использующие реляционные базы данных. Cassendra, Hbase, MongoDB и Neo4 — некоторые нереляционные базы данных.
Заключение
Основное различие между реляционной и нереляционной базой данных состоит в том, что реляционная база данных хранит данные в таблицах, в то время как нереляционная база данных хранит данные в формате ключ-значение, в документах или каким-либо другим способом без использования таблиц, таких как реляционная база данных.
Язык управления данными (DML)¶
После того как определена схема базы данных и таблиц, в них можно помещать данные и изменять их с помощью DML, который реализован частью конструкций SQL. Далее будут подробно разобраны основные из этих конструкций.
Вставка (insert)
Новые строки добавляются с помощью команды . Эта команда содержит часть VALUES, в которой прописаны данные для каждой добавляемой строки:
INSERT INTO employee (emp_id, emp_name, dep_id)
VALUES (1, 'dilbert', 1);
INSERT INTO employee (emp_id, emp_name, dep_id)
VALUES (2, 'wally', 1);
Автоинкрементные целочисленные ключи
Большинство современных баз данных содержит в себе функционал для генерации инкрементных целочисленных значений, которые обычно используются в качестве искусственных первичных ключей. Как в примере с таблицами «employee» и «department». Например, при использовании , столбец в коде выше будет автоматически создан целочисленным; при использовании MySQL для создания автоинкрементных ключей используется опция ; в PostgreSQL для этих целей служит тип данных . Когда используются генераторы автоинкрементных первичных ключей, можно опустить эти столбцы в команде :
INSERT INTO employee (emp_name, dep_id)
VALUES ('dilbert', 1);
INSERT INTO employee (emp_name, dep_id)
VALUES ('wally', 1);
Базы данных с этой функциональностью также позволяют получить сгенерированное при вставке значение. При этом используются нестандартные для SQL конструкции и / или функции. Например, в PostgreSQL это параметр :
INSERT INTO employee (emp_name, dep_id)
VALUES ('dilbert', 1) RETURNING emp_id;
| emp_id |
|---|
| 1 |
Обновление (Update)
Команда служит для изменения данных в существующих строках, использую параметр WHERE для фильтрации строк по какому-либо условию и параметр SET для установки нового значения в нужный столбец:
UPDATE employee SET dep_id=7 WHERE emp_name='dilbert'
Когда команда выполняется по условию, как в примере выше, в результате может быть изменено любое количество строк. В том числе и ни одна. Обычно присутствует некоторый счётчик строк, который позволяет получить информацию о том, сколько строк было отфильтровано и, как следствие, изменено.
Реляционная модель
У реляционной модели есть несколько ограничений. Одним из главных является ограниченность в возможностях представления сущностей реального мира, которые имеют гораздо более сложный вид, чем тот, в котором их можно представить с помощью кортежей и отношений. Еще более слабой эта модель является в том, что касается различения разных видов отношений между сущностями. Представлять сложные данные и манипулировать ими в традиционных реляционных базах данных не возможно: набор операций, которые можно выполнять в реляционных моделях, не подходит для многих реальных приложений, в состав которых входят объекты с нечисловыми атрибутами.
Ограничения традиционной реляционной модели при моделировании нескольких сущностей реального мира привели к изучению семантических моделей данных и так называемых расширенных реляционных моделей данных. За право считаться следующим поколением реляционной модели сейчас соревнуются две модели: объектно-ориентированная и объектно-реляционная. Базы данных, разрабатываемые на основе первой, называются объектно-ориентированными системами управления базами данных (ООСУБД; Object-Oriented Database Management Systems — OODBMS), а базы данных,разрабатываемые на основе второй, соответственно — объектно-реляционными системами управления базами данных.
Концептуальная модель базы данных
Под концептуальной моделью понимают отражение предметной области для разрабатываемой базы данных. Если не вдаваться в теорию, то речь идёт о некой диаграмме с общепринятыми обозначениями:
— вещи обозначаются прямоугольниками;
— атрибуты объекта овалами;
— связи в таблицах ромбами;
— мощность и направление связей стрелками (одинарными, двойными).
Делая поставку, поставщик подтверждает её документами. Аналогично и с покупателем. Таким образом, и поставку, и покупку можно рассматривать в качестве самостоятельных объектов.
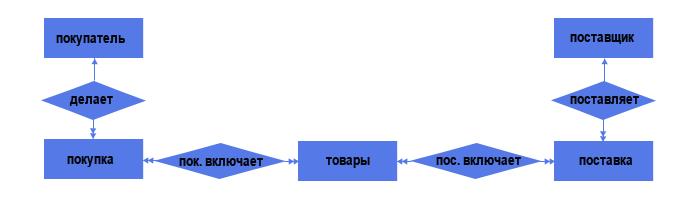
Итого 5 объектов и 4 связи. Из них:
— 2 связи типа «один ко многим» (один поставщик может делать несколько поставок; один покупатель может делать несколько покупок);
— 2 связи типа «многие ко многим» (каждая поставка может включать несколько товаров, причём одинаковый товар может быть в нескольких поставках; аналогичная ситуация по линии «Покупка — Товар»).
Но давайте вспомним, что связи типа «многие ко многим» недопустимы в реляционных моделях данных, поэтому такие связи надо менять на связи типа «один ко многим». Делаем это, добавляя промежуточный объект:
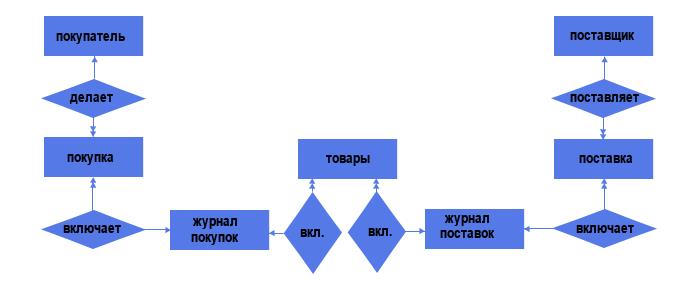
Видим, что в структуре появились ещё 2 объекта — «Журнал поставок» и «Журнал покупок» со связями типа «один ко многим» (каждый журнал может включать несколько поставок/покупок, но каждая поставка/покупка включает лишь один журнал).
Таблица как важная часть реляционной БД
Всем известно, что реляционная база данных состоит из таблиц. При этом каждая таблица включает в себя столбцы (поля либо атрибуты) и строки (записи либо кортежи).
Таблицы в таких БД обладают следующими свойствами:
— столбцы размещаются в определённом порядке, формируемом при создании таблицы. Таблица может не иметь ни одной строки, однако хотя бы один столбец должен быть обязательно;
— в таблице не может быть 2-х одинаковых строк. Если вспомнить математику, то такие таблицы называют отношениями (relation). Именно поэтому данные БД и считаются реляционными;
— каждый столбец в пределах таблицы имеет уникальное имя, а все значения в одном столбце должны быть одного типа (дата, текст, число и т. п.);
— на пересечении строки и столбца может быть только атомарное значение (значение, не состоящее из группы значений). Таблицы, которые удовлетворяют этим условиям, считаются нормализованными.
Колоночные
Атомарная единица таких БД — колонка таблицы. Данные сохраняются столбец за столбцом, что делает колоночные запросы очень эффективными, и, поскольку данные в каждой колонке однородны, это позволяет лучше сжимать данные.
Использование
В тех случаях, когда удобно делать запросы к подмножеству столбцов (оно не обязательно должно быть одинаковым каждый раз!). Колоночные БД обрабатывают такие запросы очень быстро, так как читают только конкретные колонки (в то время как строчные БД должны читать строки полностью).
В науке о данных часто бывает, что каждая колонка представляет определенную характеристику. Как специалист по данным я часто тренирую свои модели на подмножествах характеристик и проверяю отношения между ними и оценками (корреляция, дисперсия, значимость). То же подходит и для логов— в них зачастую множество полей, но при каждом запросе используются только некоторые. Например:
Cassandra.
Строчная и колоночная базы данных
Контроль за реляционной базой любого размера
Для работы с базой данных используется специальный софт — системы управления базами данных — СУБД. Он облегчает работу с крупными базами и ускоряет процесс их настройки. Для СУБД был создан специальный язык структурированных запросов. Эти запросы содержат координаты расположения информации — названия строк и столбцов, их типы. Чем компактнее будет сформулирован запрос, тем быстрее отыщется информация.
Чтобы лучше представить себе БД реляционного типа, сравните её с чем-нибудь уже знакомым. Таблицы в excel — наглядный аналог таблицы в реляционной базе. Даже небольшой навык работы в этой программе позволит лучше представить принцип работы БД. Здесь ячейки заполняются вручную, зато визуально видна их структура.
O(1) vs O(n2)
В настоящее время многие разработчики не заботятся о временной сложности алгоритмов … и они правы!
Но когда вы имеете дело с большим количеством данных (я не говорю о тысячах) или если вы боретесь за миллисекунды, становится критически важным понять эту концепцию. И как вы понимаете, базы данных должны иметь дело с обеими ситуациями! Я не заставлю вас потратить больше времени, чем необходимо чтобы ухватить суть. Это поможет нам позже понять концепцию оптимизации на основе затрат (cost based optimization).
Концепция
Временная сложность алгоритма используется, чтобы увидеть сколько времени займет выполнение алгоритма для данного объема данных. Чтобы описать эту сложность, используют математические обозначения больших О. Эта нотация используется с функцией, которая описывает, сколько операций нужно алгоритму для заданного количества входных данных.
Например, когда я говорю «этот алгоритм имеет сложность O (some_function() )», это означает, что для обработки определенного объема данных алгоритму требуется some_function(a_certain_amount_of_data) операций.
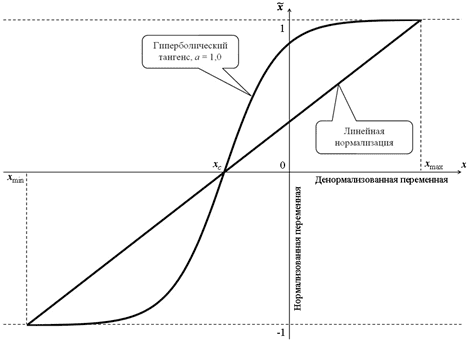
При этом важно не количество данных**, а то, ** как увеличивается количество операций при увеличении объема данных. Сложность по времени не дает точное количество операций, но хороший способ для оценки времени выполнения
На этом графике вы можете увидеть зависимость числа операций от объема входных данных для различных типов временных сложностей алгоритмов. Я использовал логарифмическую шкалу, чтобы отобразить их. Другими словами, количество данных быстро увеличивается с 1 до 1 млрд. Мы можем увидеть, что:
- O(1) или постоянная сложность остаются постоянными (иначе это не будет называться постоянной сложностью).
- O(log(n)) остается низкой даже с миллиардами данных.
- Наихудшая сложность — O(n2), где количество операций быстро растет.
- Две другие сложности так же быстро увеличиваются.
Примеры
При небольшом количестве данных разница между O(1) и O(n2) незначительна. Например, предположим, что у вас есть алгоритм, который должен обрабатывать 2000 элементов.
- Алгоритм O (1) обойдется вам в 1 операцию
- Алгоритм O (log (n)) обойдется вам в 7 операций
- Алгоритм O (n) обойдется вам в 2 000 операций
- Алгоритм O (n * log (n)) обойдется вам в 14 000 операций
- Алгоритм O (n2) обойдется вам в 4 000 000 операций
Как я уже сказал, по-прежнему важно знать эту концепцию при работе с огромным количеством данных. Если на этот раз алгоритм должен обработать 1 000 000 элементов (что не так уж много для базы данных):
- Алгоритм O (1) обойдется вам в 1 операцию
- Алгоритм O (log (n)) обойдется вам в 14 операций
- Алгоритм O (n) обойдется вам в 1 000 000 операций
- Алгоритм O (n * log (n)) обойдется вам в 14 000 000 операций
- Алгоритм O (n2) обойдется вам в 1 000 000 000 000 операций
Я не делал расчетов, но я бы сказал, что с помощью алгоритма O (n2) у вас есть время выпить кофе (даже два!). Если вы добавите еще 0 к объему данных, у вас будет время, чтобы вздремнуть.
Идем глубже
Для справки:
- Поиск в хорошей хеш-таблице находит элемент за O (1).
- Поиск в хорошо сбалансированном дереве дает результат за O (log (n)).
- Поиск в массиве дает результат за O (n).
- Лучшие алгоритмы сортировки имеют сложность O (n * log (n)).
- Плохой алгоритм сортировки имеет сложность O (n2).
Примечание: в следующих частях мы увидим эти алгоритмы и структуры данных.
Есть несколько типов временной сложности алгоритма:
- сценарий среднего случая
- лучший вариант развития событий
- и худший сценарий
Временная сложность часто является наихудшим сценарием.
Я говорил только о временной сложности алгоритма, но сложность также применима для:
- потребления памяти алгоритмом
- потребления дискового ввода / вывода алгоритмом
Конечно, есть сложности хуже, чем n2, например:
- n4: это ужасно! Некоторые из упомянутых алгоритмов имеют такую сложность.
- 3n: это еще хуже! Один из алгоритмов, которые мы увидим в середине этой статьи, имеет эту сложность (и он действительно используется во многих базах данных).
- факториал n: вы никогда не получите свои результаты даже с небольшим количеством данных.
- nn: если вы столкнетесь с этой сложностью, вы должны спросить себя, действительно ли это ваша сфера деятельности …
Хранилища данных временных рядов
Данными временных рядов называются наборы значений, которые упорядочены по времени. Соответственно хранилища данных временных рядов оптимизированы для хранения данных именно такого типа. Хранилища данных временных рядов должны поддерживать очень большое число операций записи, так как обычно в них в режиме реального времени собирается большой объем данных из большого количества источников. Эти хранилища также хорошо подходят для хранения данных телеметрии. Например, для сбора данных от датчиков Интернета вещей или счетчиков в приложениях или системах. Обновления в таких базах данных выполняются редко, а удаление чаще всего является массовой операцией.
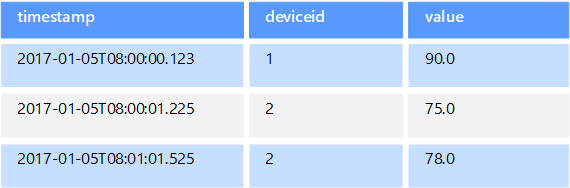
Размер отдельных записей в базе данных временных рядов обычно невелик, но их очень много, а значит общий размер данных быстро увеличивается. Хранилища данных временных рядов также обрабатывают данные, полученные вне очереди или несвоевременно, автоматически индексируют точки данных и оптимизируют запросы, полученные в течение определенного промежутка времени. Эта последняя возможность позволяет быстро выполнять запросы к миллионам точек данных и нескольким потокам данных, что, в свою очередь, обеспечивает поддержку визуализации временных рядов (стандартный способ потребления данных временных рядов).
Дополнительные сведения см. в статье Решения для временных рядов.
Соответствующие службы Azure:
- Аналитика временных рядов Azure
- OpenTSDB с HBase в HDInsight
Реляционные отношения (связи) между таблицами базы данных
Между двумя или более таблицами
базы данных могут существовать отношения
подчиненности. Отношения подчиненности
определяют, что для каждой записи главной
таблицы {master, называемой еще
родительской} может существовать одна
или несколько записей в подчиненной
таблице {detail, называемой
еще дочерней}.
Существует три разновидности
связей между таблицами базы данных:
-«один-ко-многим»,
-«один-к-одному»,
-«многие-ко-многим».
Отношение «один-ко-многим»
имеет место, когда одной записи
родительской таблицы может
соответствовать несколько записей в
дочерней таблице.
Связь «один-ко-многим»
является самой распространенной для
реляционных баз данных.
В широко распространенной
нотации структуры баз данных IDEF1X
отношение «один-ко-многим» изображается путем
соединения таблиц линией, которая на
стороне дочерней таблицы оканчивается
кружком или иным символом. Поля, входящие в
первичный ключ для данной ТБД, всегда
расположены вверху и отчеркнуты от прочих
полей линией.
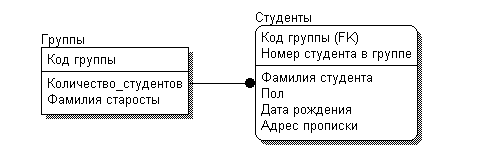
Отношение «один-к-одному»
имеет место, когда одной записи в
родительской таблице соответствует одна
запись в дочерней таблице.
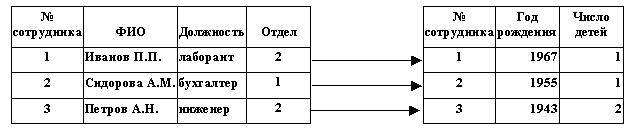
Данное отношение используют,
если не хотят, чтобы таблица БД «не распухала»
от второстепенной информации.
Отношение «многие-ко-многим»
имеет место, когда:
а) записи в родительской таблице
может соответствовать больше одной записи
в дочерней таблице;
б) записи в дочерней таблице
может соответствовать больше одной записи
в родительской таблице.
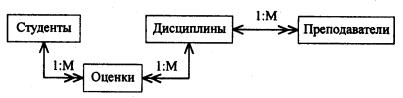
Например, каждой студент
изучает несколько дисциплин. Каждая
дисциплина изучается несколькими
студентами.

Многие СУБД (в частности Access) не поддерживают связи «многие-ко-многим»
на уровне индексов и ссылочной целостности.
Считается, что всякую связь «многие-ко-многим»
можно заменить на одну или более связей «один-ко-многим».
Например,

Системы управления базами данных
Базы данных – это логически смоделированные хранилища различной информации (данных) всех видов. Каждая база данных SQL основана модели, которая предоставляет структуру для хранящихся в ней данных. Системы управления базами данных – это приложения (или библиотеки), которые управляют базами данных различных форм, размеров и видов.
Примечание: Чтобы узнать больше о СУБД, читайте статью SQL, NoSQL и другие модели баз данных.
Реляционные системы управления базами данных
Реляционные СУБД для работы с данными используют реляционную модель. Эта модель хранит любую информацию в таблицах в виде связанных записей с атрибутами.
Этот тип СУБД требует наличия структур-таблиц. Столбцы (атрибуты) такой таблицы содержат различные типы данных. Каждая запись БД воспринимается как строка в таблице, атрибуты которой представлены в виде столбцов.
Организация информации в реляционной базе данных
Информация в реляционной базе данных организуется по следующему принципу: пары таблиц объединяются между собой при помощи совпадающих ключей (одинаковых столбцов), которые называются информационными связями. Выделяют информационные связи трех типов:
- «один к одному». Связи данного типа предполагают наличие в двух связанных таблицах только одного одинакового атрибута;
- «один ко многим». Это означает, что при данном типе связи один атрибут первой таблицы совпадает с несколькими атрибутами во второй;
- «многие ко многим». В данном случае связи между двумя таблицами устанавливаются через несколько соответствующих друг другу атрибутов.
Чтобы информация в таблицах не дублировалась и не возникало затруднений ее обновления из-за необходимости редактирования каждой записи, реляционные базы данных, базу данных требуется нормализовать. Под нормализацией понимается организация данных в БД — создание таблиц и построение связей между ними.
Чаще всего при работе с БД выполняются три основных правила нормализации, что относит базу данных к:
- первой нормальной форме. В таких БД исключаются повторяющиеся группы в отдельных таблицах, для каждого набора связанных данных создаются отдельные таблицы, каждый набор связанных данных идентифицируется при помощи первичного ключа;
- второй нормальной форме. БД, соответствующая второму правилу нормализации, имеет отдельные таблицы, связанные при помощи внешнего ключа и содержащие наборы значений, которые применяются к нескольким записям;
- третьей нормальной форме. Третье правило нормализации исключает из БД не связанные с ключами поля.
Благодаря такой организации сокращается объем избыточных данных в БД, уменьшаются затраты на ее ведение, устраняется противоречивость хранимой в базе информации и обеспечивается ее безопасность.
Узнать более подробно об организации информации в реляционных базах данных все желающие смогут в рамках профессиональной подготовки по курсу «Инструментальные средства бизнес-аналитики», которую проводит ВШБИ НИУ ВШЭ. Записаться на обучение по данному курсу можно на нашем сайте.
[править] Подходы к проектированию реляционных БД (РБД)
Первый подход (предложен Э. Коддом) основан на понятии «универсального отношения», то есть таблицы, состоящей из всех атрибутов предметной области (ПО). В дальнейшем такая таблица разбивается путем декомпозиции на несколько взаимосвязанных нормализованных таблиц. В результате на этапе концептуального проектирования создается реляционная схема БД.
Второй подход (объектный подход) основан на создании концептуальной модели данных, состоящей из описания объектов ПО и связей между ними. Затем эта модель преобразуется в реляционную модель. Процесс преобразования автоматически гарантирует получение нормализованной реляционной схемы БД.