Руководство по использованию метода split в python
Содержание:
- Использование строковых методов join и count
- Способы нарезать строки в Python
- Доступ к манипулированию строками в Python
- Сохранение строк в качестве значения для переменных
- Регулярные выражения в Python
- Мир регулярных выражений
- Таблица «Функции и методы строк»
- Escape Sequences
- Методы join(), split() и replace()
- Пример __str__ и __repr__ в Python
- Повторение строк
- Разделить строки?
- Идите с миром и форматируйте!
- Строки байтов — bytes и bytearray
- Конкатенация строк
Использование строковых методов join и count
Метод соединения строк принимает итерацию и возвращает строку, которая является конкатенацией строк итерации. Разделитель, присутствующий в промежутке между элементами, является исходной строкой, на которой вызывается метод. Используя метод join и count, соединенная строка в исходной строке также приведет к длине строки.
# Python code to demonstrate string length
# using join and count
# Returns length of string
def findLength(str):
if not str:
return 0
else:
return ((some_random_str).join(str)).count(some_random_str) + 1
print(findLength(str))
выход:
Объяснение:
В этом коде мы использовали цикл for для поиска длины строки. Во-первых, мы взяли переменную str, в которой мы дали “LatracalSolutions” в качестве строки. Во-вторых, тогда мы вызвали функцию findLength, в которой мы применили функцию if и else, в которой if содержит условия, что если строка пуста, то она должна возвращать 0; в противном случае будет работать часть else. Мы взяли некоторую случайную строку “py”, в которой основная строка будет соединяться итерацией, а значение счетчика будет увеличиваться до тех пор, пока строка не станет пустой. После этого вывод печатается.
Способы нарезать строки в Python
Если вы хотите нарезать строки в Python, это будет так же просто, как эта одна строка ниже.
res_s = s
Здесь,
- RES_S хранит возвращенную суб-строку,
- S данная строка,
- start_pos является начальным индексом, из которого нам нужно нарезать строку S,
- End_Pos является окончательным индексом, прежде чем закончится операция нарезки,
- шаг Является ли шаги Процесс нарезка от START_POS в End_Pos.
Примечание : Все вышеперечисленные три параметра являются необязательными. По умолчанию установлен на , считается равным длине строки, а установлен на 1 Отказ
Теперь давайте возьмем некоторые примеры, чтобы понять, как лучше понять строки в Python.
Доступ к манипулированию строками в Python
Хотя теперь мы знаем способ сделать строки, мы также должны понимать, как мы будем доступны и работать с строками для наших потребностей программирования. Давайте понять основы того, как вы сможете получить доступ к строковым индексе.
В Python символы строки могут быть доступны путем индексации. Расположение требуемого характера указано в квадратных скобках, где индекс 0 отмечает первый символ строки (как показано на приведенном выше изображении):
var1 = 'Hello World!'
print("var1: ", var1)
Выход вышеуказанного кода:
var1: H
Индексация позволяет отрицательными ссылками на адрес доступа к символам доступа с конца строки, например, -1 Относится к последнему характеру, – 5 относится к пятому последнему характеру и так далее.
Например:
var1 = 'Hello World'
print("var1: ", var1)
print("var1: ", var1)
Выход вышеуказанного кода:
var1: d var1: W
При доступе к индексу из диапазона вызовет IndexError Отказ Это может быть проиллюстрировано с примером, показанным ниже:
var1 = 'Hello' print(var1) # gives error
Примечание: Только целые числа могут быть переданы как индекс. Любой другой тип данных приведет к тому, что Типеррор Отказ
1. Нарезание строки Python
Чтобы получить доступ к ряду символов из строки, нарезка в строке выполняется путем использования оператора нарезки (COLON).
Str1 = "AskPython Strings Tutorial"
print(Str1)
print("\nSlicing characters from 3rd to 5th character: ")
print(String1)
Выход кода выглядит следующим образом:
Strings Tu Slicing characters from 3rd to 5th character: Py
У нас есть всесторонняя статья о нарезке строки Python, если вы заинтересованы в понимании этого подробностей.
2. Строкование Concatenation
Строки объединяются с использованием оператора «+». Иллюстрация то же самое показано ниже:
var1 = "Hi," var2 = "Good Morning!" var3 = var1 + var2 print(var3)
Выход вышеуказанного фрагмента кода, как показано ниже:
Hi,Good Morning!
3. Обновление строк в Python
Строки неизменяются, отсюда обновление или удаление символов невозможно. Это может вызвать ошибку, поскольку назначение элемента (случай обновления) или удаление элемента из строки не поддерживается.
String1 = "Hello"
# Updating character
String1 = 'p'
print("\nUpdating character at 2nd Index: ")
print(String1)
Выход вышеуказанного фрагмента кода выглядит следующим образом:
Traceback (most recent call last): File "/Desktop/trial.py", line 4, in String1 = 'p' TypeError: 'str' object does not support item assignment
Однако удаление всей строки возможна с использованием встроенного ключевого слова del.
String1 = "hello" del(String1)
Строки также могут быть обновлены, как показано ниже:
# Updating entire string
String1 = "Hello"
print(String1) # prints Hello
String1 = "Welcome"
print(String1) # prints Welcome
# concatenation and slicing to update string
var1 = 'Hello World!'
print ("Updated String :- ", var1 + 'Python')
# prints Hello Python!
4. Повторяющиеся строки
Строки могут повторяться с помощью оператора Asterisk (*) следующим образом:
var1 = "hello" print(var1*2)
Выход вышеуказанного кода состоит в том, что он печатает строку дважды.
hello hello
5. Форматирование строк в Python
Способ 1: Использование оператора форматирования
Оператор форматирования String% является уникальным для строк и ведет себя, похожее на семейство форматирования C’s PrintF ().
print("%s has Rs %d with her" % ('Aisha', 100))
Выход вышеуказанного кода:
Aisha has Rs 100 with her
Способ 2: Использование формата () Метод Метод формата () для строк содержит фигурные брекеты {} в качестве заполнителей, которые могут хранить аргументы в соответствии с положением или ключевым словом, чтобы указать заказ.
Str1 = "{} {}".format('Hi, It is', '2020')
print(Str1)
Выход вышеуказанного фрагмента кода, как показано ниже:
Hi, It is 2020
Формат () Метод в Python может использоваться для форматирования целых чисел, позволяя преобразованиям от десятичного формата в двоичные, восьмеричные и шестнадцатеричные.
num = int(input())
ar1 = "{0:b}".format(num)
print("\nBinary representation of ",num," is ", ar1)
Сохранение строк в качестве значения для переменных
В общем смысле слова, переменные являются последовательностью символов, которую вы можете использовать для хранения данных в программе. Например, их можно представить в качестве неких пустых ящиков, в которое вы помещаете различные объекты. Такими объектами может стать любой тип данных, и строки в этом смысле не исключение. Однажды создав переменную, мы сильно упрощаем себе работу со строкой на протяжении всей программы.
Для того чтобы сохранить значение строки внутри переменной, нам просто нужно присвоить строке ее имя. В следующем примере давайте объявим в качестве нашей переменной:
my_str = "Sammy likes declaring strings."
Теперь, когда у нас есть переменная , назначенная нужной нам строке, мы можем вывести ее на экран:
print(my_str)
И получим следующий вывод:
Sammy likes declaring strings.
Использование переменных вместо строк не только дает нам возможность не переписывать строки каждый раз, когда нам это нужно, но также сильно упрощает работу с ними внутри программы.
Регулярные выражения в Python
В Python для работы с регулярками есть модуль . Его нужно просто импортировать:
А вот наиболее популярные методы, которые предоставляет модуль:
Рассмотрим каждый из них подробнее.
re.match(pattern, string)
Этот метод ищет по заданному шаблону в начале строки. Например, если мы вызовем метод на строке «AV Analytics AV» с шаблоном «AV», то он завершится успешно. Но если мы будем искать «Analytics», то результат будет отрицательный:
Искомая подстрока найдена. Чтобы вывести её содержимое, применим метод (мы используем «r» перед строкой шаблона, чтобы показать, что это «сырая» строка в Python):
Теперь попробуем найти «Analytics» в данной строке. Поскольку строка начинается на «AV», метод вернет :
Также есть методы и для того, чтобы узнать начальную и конечную позицию найденной строки.
Эти методы иногда очень полезны для работы со строками.
re.search(pattern, string)
Метод похож на , но ищет не только в начале строки. В отличие от предыдущего, вернёт объект, если мы попытаемся найти «Analytics»:
Метод ищет по всей строке, но возвращает только первое найденное совпадение.
re.findall(pattern, string)
Возвращает список всех найденных совпадений. У метода нет ограничений на поиск в начале или конце строки. Если мы будем искать «AV» в нашей строке, он вернет все вхождения «AV». Для поиска рекомендуется использовать именно , так как он может работать и как , и как .
re.split(pattern, string, )
Этот метод разделяет строку по заданному шаблону.
В примере мы разделили слово «Analytics» по букве «y». Метод принимает также аргумент со значением по умолчанию, равным 0. В данном случае он разделит строку столько раз, сколько возможно, но если указать этот аргумент, то разделение будет произведено не более указанного количества раз. Давайте посмотрим на примеры:
Мы установили параметр равным 1, и в результате строка была разделена на две части вместо трех.
re.compile(pattern, repl, string)
Мы можем собрать регулярное выражение в отдельный объект, который может быть использован для поиска. Это также избавляет от переписывания одного и того же выражения.
До сих пор мы рассматривали поиск определенной последовательности символов. Но что, если у нас нет определенного шаблона, и нам надо вернуть набор символов из строки, отвечающий определенным правилам? Такая задача часто стоит при извлечении информации из строк. Это можно сделать, написав выражение с использованием специальных символов. Вот наиболее часто используемые из них:
| Оператор | Описание |
|---|---|
| . | Один любой символ, кроме новой строки \n. |
| ? | 0 или 1 вхождение шаблона слева |
| + | 1 и более вхождений шаблона слева |
| * | 0 и более вхождений шаблона слева |
| \w | Любая цифра или буква (\W — все, кроме буквы или цифры) |
| \d | Любая цифра (\D — все, кроме цифры) |
| \s | Любой пробельный символ (\S — любой непробельный символ) |
| \b | Граница слова |
| Один из символов в скобках ( — любой символ, кроме тех, что в скобках) | |
| \ | Экранирование специальных символов (\. означает точку или \+ — знак «плюс») |
| ^ и $ | Начало и конец строки соответственно |
| {n,m} | От n до m вхождений ({,m} — от 0 до m) |
| a|b | Соответствует a или b |
| () | Группирует выражение и возвращает найденный текст |
| \t, \n, \r | Символ табуляции, новой строки и возврата каретки соответственно |
Больше информации по специальным символам можно найти в документации для регулярных выражений в Python 3.
Ну хватит теории. Рассмотрим примеры использования Python RegEx.
Мир регулярных выражений
Иногда непросто очистить текст с помощью определенных символов или фраз. Вместо этого нам необходимо использовать некоторые шаблоны. И здесь нам на помощь приходят регулярные выражения и соответствующий модуль Python.
Мы не будем обсуждать всю мощь регулярных выражений, а сосредоточимся на их применении — например, на разделении и замене данных. Да, эти задачи были описаны выше, но вот более мощная альтернатива.
Разделение по шаблону:
import re
test_punctuation = " This &is example? {of} string. with.? punctuation!!!! "
re.split('\W+', test_punctuation)
Out:
Замена по шаблону:
import re
test_with_numbers = "This is 1 string with 10 words for 9 digits 2 example"
re.sub('\d', '*', test_with_numbers)
Out: 'This is * string with ** words for * digits * example'
Таблица «Функции и методы строк»
| Функция или метод | Назначение |
|---|---|
| S = ‘str’; S = «str»; S = »’str»’; S = «»»str»»» | Литералы строк |
| S = «s\np\ta\nbbb» | Экранированные последовательности |
| S = r»C:\temp\new» | Неформатированные строки (подавляют экранирование) |
| S = b»byte» | Строка байтов |
| S1 + S2 | Конкатенация (сложение строк) |
| S1 * 3 | Повторение строки |
| S | Обращение по индексу |
| S | Извлечение среза |
| len(S) | Длина строки |
| S.find(str, ,) | Поиск подстроки в строке. Возвращает номер первого вхождения или -1 |
| S.rfind(str, ,) | Поиск подстроки в строке. Возвращает номер последнего вхождения или -1 |
| S.index(str, ,) | Поиск подстроки в строке. Возвращает номер первого вхождения или вызывает ValueError |
| S.rindex(str, ,) | Поиск подстроки в строке. Возвращает номер последнего вхождения или вызывает ValueError |
| S.replace(шаблон, замена) | Замена шаблона на замену. maxcount ограничивает количество замен |
| S.split(символ) | Разбиение строки по разделителю |
| S.isdigit() | Состоит ли строка из цифр |
| S.isalpha() | Состоит ли строка из букв |
| S.isalnum() | Состоит ли строка из цифр или букв |
| S.islower() | Состоит ли строка из символов в нижнем регистре |
| S.isupper() | Состоит ли строка из символов в верхнем регистре |
| S.isspace() | Состоит ли строка из неотображаемых символов (пробел, символ перевода страницы (‘\f’), «новая строка» (‘\n’), «перевод каретки» (‘\r’), «горизонтальная табуляция» (‘\t’) и «вертикальная табуляция» (‘\v’)) |
| S.istitle() | Начинаются ли слова в строке с заглавной буквы |
| S.upper() | Преобразование строки к верхнему регистру |
| S.lower() | Преобразование строки к нижнему регистру |
| S.startswith(str) | Начинается ли строка S с шаблона str |
| S.endswith(str) | Заканчивается ли строка S шаблоном str |
| S.join(список) | Сборка строки из списка с разделителем S |
| ord(символ) | Символ в его код ASCII |
| chr(число) | Код ASCII в символ |
| S.capitalize() | Переводит первый символ строки в верхний регистр, а все остальные в нижний |
| S.center(width, ) | Возвращает отцентрованную строку, по краям которой стоит символ fill (пробел по умолчанию) |
| S.count(str, ,) | Возвращает количество непересекающихся вхождений подстроки в диапазоне (0 и длина строки по умолчанию) |
| S.expandtabs() | Возвращает копию строки, в которой все символы табуляции заменяются одним или несколькими пробелами, в зависимости от текущего столбца. Если TabSize не указан, размер табуляции полагается равным 8 пробелам |
| S.lstrip() | Удаление пробельных символов в начале строки |
| S.rstrip() | Удаление пробельных символов в конце строки |
| S.strip() | Удаление пробельных символов в начале и в конце строки |
| S.partition(шаблон) | Возвращает кортеж, содержащий часть перед первым шаблоном, сам шаблон, и часть после шаблона. Если шаблон не найден, возвращается кортеж, содержащий саму строку, а затем две пустых строки |
| S.rpartition(sep) | Возвращает кортеж, содержащий часть перед последним шаблоном, сам шаблон, и часть после шаблона. Если шаблон не найден, возвращается кортеж, содержащий две пустых строки, а затем саму строку |
| S.swapcase() | Переводит символы нижнего регистра в верхний, а верхнего – в нижний |
| S.title() | Первую букву каждого слова переводит в верхний регистр, а все остальные в нижний |
| S.zfill(width) | Делает длину строки не меньшей width, по необходимости заполняя первые символы нулями |
| S.ljust(width, fillchar=» «) | Делает длину строки не меньшей width, по необходимости заполняя последние символы символом fillchar |
| S.rjust(width, fillchar=» «) | Делает длину строки не меньшей width, по необходимости заполняя первые символы символом fillchar |
| S.format(*args, **kwargs) | Форматирование строки |
Escape Sequences
Экранированный символ теряет своё изначальное значение
и воспринимается интерпретатором как обычный символ либо наоборот приобретает дополнительный смысл как мы уже видели на
примере \n
Сравните
>>> «This is n it is a normal symbol»
‘This is n it is a normal symbol’
>>> s = «This is n it is a normal symbol»
>>> print(s)
This is n it is a normal symbol
И
>>> «This is \n it is an escaped symbol»
‘This is \n it is an escaped symbol’
>>> s = «This is \n it is an escaped symbol»
>>> print(s)
This is
it is an escaped symbol
Вместо n теперь перенос строки
Экранирование можно применить для использования одинаковых кавычек внутри и снаружи строки
>>> «Двойная кавычка \» внутри двойных»
‘Двойная кавычка » внутри двойных’
>>> ‘Одинарная кавычка \’ внутри одинарных’
‘Одинарная кавычка ‘ внутри одинарных’
Если экранирование не подразумевается, то \ будет всё равно будет воспринят интерпретатором как попытка экранирования и не появится как обычный символ
>>> ‘Двойную кавычку \» можно не экранировать внутри одинарных а \’ одинарную нужно’
‘Двойную кавычку » можно не экранировать внутри одинарных а \’ одинарную нужно’
>>> s = ‘Двойную кавычку \» можно не экранировать внутри одинарных а \’ одинарную нужно’
>>> print(s)
Двойную кавычку » можно не экранировать внутри одинарных а ‘ одинарную нужно
Чтобы всё-таки увидеть \ нужно написать \\ то есть проэкранировать символ экранирования
>>> s = ‘\\’
>>> print(s)
| Escape Sequence | Значение | Примечания |
|---|---|---|
| \newline | Backslash and newline ignored | |
| \\ | Backslash (\) | |
| \’ | Single quote (‘) | |
| \» | Double quote («) | |
| \a | ASCII Bell (BEL) | |
| \b | ASCII Backspace (BS) | |
| \f | ASCII Formfeed (FF) | |
| \n | ASCII Linefeed (LF) | |
| \r | ASCII Carriage Return (CR) | |
| \t | ASCII Horizontal Tab (TAB) | |
| \v | ASCII Vertical Tab (VT) | |
| \ooo | Character with octal value ooo |
(1,3) |
| \xhh | Character with hex value hh | (2,3) |
| Escape Sequence | Значение | Примечания |
|---|---|---|
| \N{name} | Character named name in the Unicode database | (4) |
| \uxxxx | Character with 16-bit hex value xxxx | (5) |
| \Uxxxxxxxx | Character with 32-bit hex value xxxxxxxx | (6) |
Примечания:
As in Standard C, up to three octal digits are accepted.
Unlike in Standard C, exactly two hex digits are required.
In a bytes literal, hexadecimal and octal escapes denote the byte with the given value. In a string literal, these escapes denote a Unicode character with the given value.
Changed in version 3.3: Support for name aliases 1 has been added.
Exactly four hex digits are required.
Any Unicode character can be encoded this way. Exactly eight hex digits are required.
Методы join(), split() и replace()
Методы str.join(), str.split() и str.replace() предлагают несколько дополнительных способов управления строками в Python.
Метод str.join() – один из методов конкатенации (слияния) двух строк в Python. Метод str.join(string) собирает строку string с разделителем str.
Чтобы понять, как это работает, создайте сроку:
Теперь попробуйте применить метод str.join(), где str – пробел:
Попробуйте вывести такую строку:
Чтобы вывести символы оригинальной строки в обратном порядке, введите:
Метод str.join() также может объединять список строк в одну новую строку.
Чтобы добавить пробелы и запятые после заданных строк, нужно просто переписать выражение и внеси запятую в качестве разделителя:
Метод str.split() позволяет делить строки:
Метод str.split() позволяет удалять части строк. К примеру, попробуйте удалить букву s:
Метод str.replace() может обновлять строку и заменять устаревшую версию строки новой.
Для примера попробуйте заменить слово is в строке “This is a dummy string.” cловом was.
В круглых скобках сначала указывается слово, которое нужно заменить, а затем слово, которое нужно использовать вместо первого. В результате получится:
This was a dummy string.
Пример __str__ и __repr__ в Python
Обе эти функции используются при отладке, давайте посмотрим, что произойдет, если мы не определим эти функции для объекта.
class Person:
name = ""
age = 0
def __init__(self, personName, personAge):
self.name = personName
self.age = personAge
p = Person('Pankaj', 34)
print(p.__str__())
print(p.__repr__())
Вывод:
<__main__.Person object at 0x10ff22470> <__main__.Person object at 0x10ff22470>
Как видите, реализация по умолчанию бесполезна. Давайте продолжим и реализуем оба этих метода:
class Person:
name = ""
age = 0
def __init__(self, personName, personAge):
self.name = personName
self.age = personAge
def __repr__(self):
return {'name':self.name, 'age':self.age}
def __str__(self):
return 'Person(name='+self.name+', age='+str(self.age)+ ')'
Обратите внимание, что мы возвращаем dict для функции __repr__. Посмотрим, что произойдет, если мы воспользуемся этими методами
p = Person('Pankaj', 34)
# __str__() example
print(p)
print(p.__str__())
s = str(p)
print(s)
# __repr__() example
print(p.__repr__())
print(type(p.__repr__()))
print(repr(p))
Вывод:
Person(name=Pankaj, age=34)
Person(name=Pankaj, age=34)
Person(name=Pankaj, age=34)
{'name': 'Pankaj', 'age': 34}
<class 'dict'>
File "/Users/pankaj/Documents/PycharmProjects/BasicPython/basic_examples/str_repr_functions.py", line 29, in <module>
print(repr(p))
TypeError: __repr__ returned non-string (type dict)
Обратите внимание, что функция repr() выдает ошибку TypeError, поскольку наша реализация __repr__ возвращает dict, а не строку. Изменим реализацию функции __repr__ следующим образом:
Изменим реализацию функции __repr__ следующим образом:
def __repr__(self):
return '{name:'+self.name+', age:'+str(self.age)+ '}'
Теперь он возвращает String, и новый вывод для вызовов представления объекта будет:
{name:Pankaj, age:34}
<class 'str'>
{name:Pankaj, age:34}
Ранее мы упоминали, что если мы не реализуем функцию __str__, то вызывается функция __repr__. Просто прокомментируйте реализацию функции __str__ из класса Person, и print (p) напечатает {name: Pankaj, age: 34}.
Повторение строк
Однажды у вас могут возникнуть обстоятельства, при которых вы захотите использовать Python для автоматизации некоторых задач. И одной из таких задач может стать многократное повторение строки в тексте. Для того чтобы это осуществить, потребуется воспользоваться оператором , который, как и оператор , отличается от . При использовании с одной строкой и одним числом становится оператором повторения, а не умножения. Он лишь повторяет заданный текст указанное число раз.
Давайте выведем на экран 9 раз с помощью оператора .
print("Sammy" * 9)
SammySammySammySammySammySammySammySammySammy
Таким образом, с помощью оператора повторения мы можем сколь угодно клонировать нужный нам текст.
Разделить строки?
Есть несколько способов получить часть строки. Первый — это , обратный метод для . В отличие от ’а, он применяется к целевой строке, а разделитель передаётся аргументом.
Второй — срезы (slices).
Срез s позволяет получить подстроку с символа x до символа y. Можно не указывать любое из значений, чтобы двигаться с начала или до конца строки. Отрицательные значения используются для отсчёта с конца (-1 — последний символ, -2 — предпоследний и т.п.).
При помощи необязательного третьего параметра s можно выбрать из подстроки каждый N-ый символ. Например, получить только чётные или только нечётные символы:
Идите с миром и форматируйте!
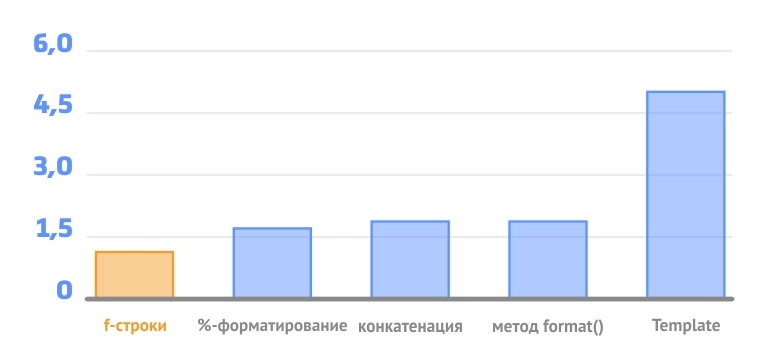
Разумеется, вы можете использовать старые методы форматирования строк, но с f-строками у вас есть более лаконичный, читаемый и удобный способ, который одновременно и быстрее, и менее вероятно приведет к ошибке. Упростить свою жизнь используя f-строки — отлична причина пользоваться Python 3.6, если вы еще не перешли к этой версии. (Если вы все еще пользуетесь Python 2.7, не беспокойтесь, 2020 год не за горами!)
Согласно дзену Python, когда вам нужно выбрать способ решения задачи, всегда “есть один — и желательно только один очевидный способ сделать это”. Кстати, f-строки не являются единственным способом форматирования строк. Однако, их использование вполне может стать единственным адекватным способом.
Строки байтов — bytes и bytearray
Определение которое мы дале в самом начале можно считать верным только для строк типа str. Но в Python имеется еще два дугих типа строк: bytes – неизменяемое строковое представление двоичных данных и bytearray – тоже что и bytes, только допускает непосредственное изменение.
Основное отличие типа str от bytes и bytearray заключается в том, что str всегда пытается превратить последовательность байтов в текст указанной кодировки. По умолчанию этой кодировкой является utf-8, но это очень большая кодировка и другие кодировки, например ASCII, Latin-1 и другие являются ее подмножествами
Одни символы кодируются одним байтом, другие двумя, а некоторые тремя и функция при декодировании последовательности байтов принимает это во внимание. А вот функциям и до этого нет дела, для них абсолютно все данные состоят только из последовательности одиночных байтов.
Такое поведение bytes и bytearray очень удобно, если вы работаете с изображениями, аудиофайлами или сетевым трафиком. В этом случае, вам следует знать, что ничего магического в этих типах нет, они поддерживоют все теже строковые методы, операции индексирования, а так же операторы и функции для работы с последовательностями. Единственное, что следует держать в уме, так это то, что вы имеете дело с последовательностью байтов, т.е. последовательностью чисел из интервала в шестнадцатеричном представлении, и что байтовые строки отличаются от обычных символом (реже) предваряющим все литералы обычных строк.
Например, что бы создать строку типа bytes или bytearray достаточно передать соответствующим функциям последовательности целых чисел:
Учитывая то, что для кодирования некоторых символов (например ASCII) достаточно всего одного байта, данные типы пытаются представить последовательности в виде символов если это возможно. Например, строка будет выведена как :
А это значит, что байтовые данные могут вполне обоснованно интерпретированться как ASCII символы и наоборот. Т.е. строки байтов могут быть созданы и так:
Но, следует помнить что это все-таки байты, в чем легко убедиться, если мы обратимся к какому-нибудь символу по его индексу в строке:
Так как строковые методы не изменяют сам объект, а создают новый, то при работе с очень длинными строками (а в мире двоичных данных это далеко не редкость) это может привести к большому расходу памяти. Собственно, по этой причине и существует тип bytearray, который позволяет менять байты прямо внутри строки:
Конкатенация строк
Конкатенация – это важный момент, это означает соединение или добавление двух объектов вместе. В нашем случае, нам нужно узнать, как добавить две строки вместе. Как вы можете догадаться, в Python эта операция очень простая:
Python
# -*- coding: utf-8 -*-
string_one = «Собака съела »
string_two = «мою книгу!»
string_three = string_one + string_two
print(string_three) # Собака съела мою книгу!
|
1 2 3 4 5 6 7 |
# -*- coding: utf-8 -*- string_one=»Собака съела « string_two=»мою книгу!» string_three=string_one+string_two print(string_three)# Собака съела мою книгу! |
Оператор + конкатенирует две строки в одну