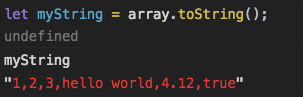
Регулярные выражения в python
Содержание:
- Введение в генераторы
- Именованные группы¶
- Feedback¶
- Regular Expression Modifiers: Option Flags
- Regular Expression Modifiers: Option Flags
- Нумерованные группы¶
- This is the tenth and final regular maintenance release of Python 3.8
- Согласуемые символы
- Строительные блоки регулярных выражений
- Основы синтаксиса
- re.match функция
- Строки
- Функция python re.sub ()
- Методы
- Выводы
Введение в генераторы
Генератор — функция, которая генерирует последовательность результатов вместо одного значения
Вместо того, чтобы возвращать значение, мы создаём серию значений (с использованием оператора yield). Вызов функции генератора создает объект-генератор. Однако функция не запускается.
Функция генератор выполняется только при вызове .
yield возвращает значение, но приостанавливает выполнение функции. Функция генератор возобновляется при следующем вызове . При завершении итератора возбуждается исключение .
Небольшие выводы:
- Функция генератор — более удобный способ написания итератора
- Вам не нужно беспокоиться о реализации протокола итератора (, и т. д.), т.к. при создании функции с магия Python уже добавляет в объект функции нужные методы.
Помимо функции генератора возможно также использовать генераторное выражение, которое также возвращает .
Синтаксис генераторного выражения также прост
Именованные группы¶
Когда выражение сложное, не очень удобно определять номер группы.
Плюс, при дополнении выражения, может получиться так, что порядок
групп изменился, и придется изменить и код, который ссылается на группы.
Именованные группы позволяют задавать группе имя.
Синтаксис именованной группы :
In 19]: line = "FastEthernet0/1 10.0.12.1 YES manual up up" In 20]: match = re.search(r'(?P<intf>\S+)\s+(?P<address>+)\s+', line)
Теперь к этим группам можно обращаться по имени:
In 21]: match.group('intf')
Out21]: 'FastEthernet0/1'
In 22]: match.group('address')
Out22]: '10.0.12.1'
Также очень полезно то, что с помощью метода groupdict(), можно получить
словарь, где ключи — имена групп, а значения — подстроки, которые им
соответствуют:
In 23]: match.groupdict()
Out23]: {'address' '10.0.12.1', 'intf' 'FastEthernet0/1'}
И в таком случае можно добавить группы в регулярное выражение и
полагаться на их имя, а не на порядок:
In 24]: match = re.search(r'(?P<intf>\S+)\s+(?P<address>+)\s+\w+\s+\w+\s+(?P<status>up|down)\s+(?P<protocol>up|down)', line)
In 25]: match.groupdict()
Out25]:
{'address' '10.0.12.1',
'intf' 'FastEthernet0/1',
'protocol' 'up',
'status' 'up'}
Feedback¶
Regular expressions are a complicated topic. Did this document help you
understand them? Were there parts that were unclear, or Problems you
encountered that weren’t covered here? If so, please send suggestions for
improvements to the author.
The most complete book on regular expressions is almost certainly Jeffrey
Friedl’s Mastering Regular Expressions, published by O’Reilly. Unfortunately,
it exclusively concentrates on Perl and Java’s flavours of regular expressions,
and doesn’t contain any Python material at all, so it won’t be useful as a
reference for programming in Python. (The first edition covered Python’s
now-removed module, which won’t help you much.) Consider checking
it out from your library.
Regular Expression Modifiers: Option Flags
Regular expression literals may include an optional modifier to control various aspects of matching. The modifiers are specified as an optional flag. You can provide multiple modifiers using exclusive OR (|), as shown previously and may be represented by one of these −
| Sr.No. | Modifier & Description |
|---|---|
| 1 |
re.I Performs case-insensitive matching. |
| 2 |
re.L Interprets words according to the current locale. This interpretation affects the alphabetic group (\w and \W), as well as word boundary behavior(\b and \B). |
| 3 |
re.M Makes $ match the end of a line (not just the end of the string) and makes ^ match the start of any line (not just the start of the string). |
| 4 |
re.S Makes a period (dot) match any character, including a newline. |
| 5 |
re.U Interprets letters according to the Unicode character set. This flag affects the behavior of \w, \W, \b, \B. |
| 6 |
re.X Permits «cuter» regular expression syntax. It ignores whitespace (except inside a set [] or when escaped by a backslash) and treats unescaped # as a comment marker. |
Regular Expression Modifiers: Option Flags
Regular expression literals may include an optional modifier to control various aspects of matching. The modifiers are specified as an optional flag. You can provide multiple modifiers using exclusive OR (|), as shown previously and may be represented by one of these −
| Sr.No. | Modifier & Description |
|---|---|
| 1 |
re.I Performs case-insensitive matching. |
| 2 |
re.L Interprets words according to the current locale. This interpretation affects the alphabetic group (\w and \W), as well as word boundary behavior (\b and \B). |
| 3 |
re.M Makes $ match the end of a line (not just the end of the string) and makes ^ match the start of any line (not just the start of the string). |
| 4 |
re.S Makes a period (dot) match any character, including a newline. |
| 5 |
re.U Interprets letters according to the Unicode character set. This flag affects the behavior of \w, \W, \b, \B. |
| 6 |
re.X Permits «cuter» regular expression syntax. It ignores whitespace (except inside a set [] or when escaped by a backslash) and treats unescaped # as a comment marker. |
Нумерованные группы¶
Группа определяется помещением выражения в круглые скобки .
Внутри выражения группы нумеруются слева направо, начиная с 1.
Затем к группам можно обращаться по номерам и получать текст, который
соответствует выражению в группе.
Пример использования групп:
In 8]: line = "FastEthernet0/1 10.0.12.1 YES manual up up" In 9]: match = re.search(r'(\S+)\s+(+)\s+.*', line)
В данном примере указаны две группы:
- первая группа — любые символы, кроме пробельных
- вторая группа — любая буква или цифра (символ ) или точка
Вторую группу можно было описать так же, как и первую. Другой
вариант сделан просто для примера
Теперь можно обращаться к группам по номеру. Группа 0 — это строка,
которая соответствует всему шаблону:
In 10]: match.group() Out10]: 'FastEthernet0/1 10.0.12.1 YES manual up up' In 11]: match.group(1) Out11]: 'FastEthernet0/1' In 12]: match.group(2) Out12]: '10.0.12.1'
При необходимости можно перечислить несколько номеров групп:
In 13]: match.group(1, 2)
Out13]: ('FastEthernet0/1', '10.0.12.1')
In 14]: match.group(2, 1, 2)
Out14]: ('10.0.12.1', 'FastEthernet0/1', '10.0.12.1')
Начиная с версии Python 3.6, к группам можно обращаться таким образом:
In 15]: match Out15]: 'FastEthernet0/1 10.0.12.1 YES manual up up' In 16]: match1 Out16]: 'FastEthernet0/1' In 17]: match2 Out17]: '10.0.12.1'
Для вывода всех подстрок, которые соответствуют указанным группам,
используется метод groups:
This is the tenth and final regular maintenance release of Python 3.8
Note: The release you’re looking at is Python 3.8.10, a bugfix release for the legacy 3.8 series. Python 3.9 is now the latest feature release series of Python 3. Get the latest release of 3.9.x here.
According to the release calendar specified in PEP 569, Python 3.8.10 is the final regular maintenance release. Starting now, the 3.8 branch will only accept security fixes and releases of those will be made in source-only form until October 2024.
Compared to the 3.7 series, this last regular bugfix release is relatively dormant at 92 commits since 3.8.9. Version 3.7.8, the final regular bugfix release of Python 3.7, included 187 commits. But there’s a bunch of important updates here regardless, the biggest being Big Sur and Apple Silicon build support. This work would not have been possible without the effort of Ronald Oussoren, Ned Deily, Maxime Bélanger, and Lawrence D’Anna from Apple. Thank you!
Take a look at the change log for details.
Согласуемые символы
Когда вам нужно найти символ в строке, в большей части случаев вы можете просто использовать этот символ или строку. Так что, когда нам нужно проверить наличие слова «dog», то мы будем использовать буквы в dog. Конечно, существуют определенные символы, которые заняты регулярными выражениями. Они так же известны как метасимволы. Внизу изложен полный список метасимволов, которые поддерживают регулярные выражения Python:
Python
. ˆ $ * + ? { } | ( )
| 1 | . ˆ $ * + ? { } | ( ) |
Давайте взглянем как они работают. Основная связка метасимволов, с которой вы будете сталкиваться, это квадратные скобки: . Они используются для создания «класса символов», который является набором символов, которые вы можете сопоставить. Вы можете отсортировать символы индивидуально, например, так: . Это сопоставит любой внесенный в скобки символ. Вы также можете использовать тире для выражения ряда символов, соответственно: . В этом примере мы сопоставим одну из букв в ряде между a и g. Фактически для выполнения поиска нам нужно добавить начальный искомый символ и конечный. Чтобы упростить это, мы можем использовать звездочку. Вместо сопоставления *, данный символ указывает регулярному выражению, что предыдущий символ может быть сопоставлен 0 или более раз. Давайте посмотрим на пример, чтобы лучше понять о чем речь:
Python
‘a*f
| 1 | ‘ab-f*f |
Этот шаблон регулярного выражения показывает, что мы ищем букву а, ноль или несколько букв из нашего класса, и поиск должен закончиться на f. Давайте используем это выражение в Python:
Python
import re
text = ‘abcdfghijk’
parser = re.search(‘a*f’)
print(parser.group()) # ‘abcdf’
|
1 2 3 4 5 |
importre text=’abcdfghijk’ parser=re.search(‘a*f’) print(parser.group())# ‘abcdf’ |
В общем, это выражение просмотрит всю переданную ей строку, в данном случае это abcdfghijk.Выражение найдет нашу букву «а» в начале поиска. Затем, в связи с тем, что она имеет класс символа со звездочкой в конце, выражение прочитает остальную часть строки, что бы посмотреть, сопоставима ли она. Если нет, то выражение будет пропускать по одному символу, пытаясь найти совпадения. Вся магия начинается, когда мы вызываем поисковую функцию модуля re. Если мы не найдем совпадение, тогда мы получим None. В противном случае, мы получим объект Match. Чтобы увидеть, как выглядит совпадение, вам нужно вызывать метод group. Существует еще один повторяемый метасимвол, аналогичный *. Этот символ +, который будет сопоставлять один или более раз. Разница с *, который сопоставляет от нуля до более раз незначительна, на первый взгляд.
Символу + необходимо как минимум одно вхождение искомого символа. Последние два повторяемых метасимвола работают несколько иначе. Рассмотрим знак вопроса «?», применение которого выгладит так: “co-?op”. Он будет сопоставлять и “coop” и “co-op”. Последний повторяемый метасимвол это {a,b}, где а и b являются десятичными целыми числами. Это значит, что должно быть не менее «а» повторений, но и не более «b». Вы можете попробовать что-то на подобии этого:
Python
xb{1,4}z
| 1 | xb{1,4}z |
Это очень примитивный пример, но в нем говорится, что мы сопоставим следующие комбинации: xbz, xbbz, xbbbz и xbbbbz, но не xz, так как он не содержит «b».
Следующий метасимвол это ^. Этот символ позволяет нам сопоставить символы которые не находятся в списке нашего класса. Другими словами, он будет дополнять наш класс. Это сработает только в том случае, если мы разместим ^ внутри нашего класса. Если этот символ находится вне класса, тогда мы попытаемся найти совпадения с данным символом. Наглядным примером будет следующий: . Так, выражения будет искать совпадения с любой буквой, кроме «а». Символ ^ также используется как анкор, который обычно используется для совпадений в начале строки.
Существует соответствующий якорь для конце строки – «$». Мы потратим много времени на введение в различные концепты применения регулярных выражений. В следующих параграфах мы углубимся в более подробные примеры кодов.
Строительные блоки регулярных выражений
В этом разделе мы рассмотрим элементы, которые составляют Regex и как построен регулярные вещества. REGEX содержит группы, и каждая группа содержит различные спецификаторы, такие как классы символов, повторители, идентификаторы и т. Д. Спецификаторы – это строки, которые соответствуют определенным типам рисунка и имеют свой собственный формат для описания желаемого рисунка. Давайте посмотрим на общие спецификаторы:
Идентификаторы
Идентификатор соответствует подмножеству символов E.g., строчные буквы, числовые цифры, пробел и т. Д. Regex предоставляет список удобных идентификаторов для соответствия различных подмножествах. Некоторые часто используемые идентификаторы:
- цифры (числовые символы) в строке
- что-нибудь, кроме цифра
- Белое пространство (например, пространство, вкладка и т. Д. ,.)
- что-нибудь, кроме пространства
- Письма/алфавиты и цифры
- что-нибудь, кроме письмо
- Любой персонаж, который может отделить слова (например, пространство, дефис, толстой кишки и т. Д. ,.)
- любой символ, кроме новой линии. Следовательно, это называется оператором подстановки. Таким образом, «. *» Будет соответствовать любому персонажу, любому Nuber Times.
Примечание: в приведенном выше примере Regex и все остальные в этом разделе мы опускаем ведущую от строковой буквы Regex для ради читабельности. Любой буквальный приведенный здесь должен быть объявлен сырой строковой буквальной буквами при использовании в коде Python.
Повторители
Репретеритор используется для уточнения одного или нескольких вхождений группы. Ниже приведены некоторые часто используемые ретрансляторы.
`*` Символ
Оператор Звездочки указывает на 0 или более повторений предыдущего элемента, как можно больше. «ab *» будет соответствовать «A», «ab», «ABB» или «A», а затем любое количество B.
`+` Символ
Оператор Plus указывает на 1 или более повторений предыдущего элемента, как можно больше. «AB +» будет соответствовать «A», «ab», «ABB» или «A», а затем 1 вхождение «B»; Это не будет соответствовать «a».
`?` Символ
Этот символ указывает предыдущий элемент с большинством, то есть, он может или не может присутствовать в строке, подходящей. Например, «ab +» будет соответствовать «A» и «AB».
`{N}` кудрявые скобки
Кредиковые брекеты указывают предыдущий элемент, который должен соответствовать ровно N раз. B {4} будет сопоставлять ровно четырех символов «B», но не более/менее 4.
Символы *, + ,? и {} называются ретрансляторами, поскольку они указывают количество раз, когда предыдущий элемент повторяется.
Разные спецификаторы
`[] Квадратные скобки
Квадратные брекеты соответствуют любому одному символу, заключенному внутри него. Например, будет соответствовать любому из строчных гласных гласных, когда будет соответствовать любому символу из A-Z (чувствителен к регистру). Это также называется классом персонажа.
`|` “
Вертикальная полоса используется для разделения альтернатив. Фото | Фото спички либо «фото» или «фото».
`^` Символ
Символ CARET указывает положение для матча, в начале строки, кроме при использовании внутри квадратных скобок. Например, «^ i» будет сочетать строку, начиная с «I», но не сопоставлю строк, которые не имеют «я» в начале. Это, по сути, то же самое, что и функциональность, предоставленные Функция против функция.
При использовании в качестве первого символа внутри класса символов он инвертирует соответствующий набор символов для класса символов. Например, «» будет соответствовать любому символу, отличным от A, E, I, O или U.
Символ `$`
Символ доллара указывает положение для матча, в конце строки.
`()” Скобки
Скобка используется для группировки разных символов Re, действовать как один блок. ( \ D +) будет сопоставить шаблоны, содержащие A-Z, а затем любая цифра. Весь матч рассматривается как группа и может быть извлечена из строки. Больше на это позже.
Основы синтаксиса
экранировать
Шаблоны, соответствующие одному символу
| Шаблон | Описание | Пример | Применяем к тексту |
|---|---|---|---|
| Один любой символ, кроме новой строки . |
молоко, малако, Им0л0коИхлеб |
||
| Любая цифра | СУ35, СУ111, АЛСУ14 | ||
| Любой символ, кроме цифры | 926)123, 1926-1234 | ||
| Любой пробельный символ (пробел, табуляция, конец строки и т.п.) |
бор ода, бор ода, борода |
||
| Любой непробельный символ | X123, я123, !123456, 1 + 123456 | ||
| Любая буква (то, что может быть частью слова), а также цифры и | Год, f_3, qwert | ||
| Любая не-буква, не-цифра и не подчёркивание | сом!, сом? | ||
| Один из символов в скобках, а также любой символ из диапазона |
12, 1F, 4B | ||
| Любой символ, кроме перечисленных | <1>, <a>, <>> | ||
| Буква “ё” не включается в общий диапазон букв! Вообще говоря, в включается всё, что в юникоде помечено как «цифра», а в — как буква. Ещё много всего! |
|||
| если нужен минус, его нужно указать последним или первым | |||
| внутри скобок нужно экранировать только и | |||
| Начало или конец слова (слева пусто или не-буква, справа буква и наоборот). В отличие от предыдущих соответствует позиции, а не символу |
вал, перевал, Перевалка | ||
| Не граница слова: либо и слева, и справа буквы, либо и слева, и справа НЕ буквы |
перевал, вал, Перевалка | ||
| перевал, вал, Перевалка |
Квантификаторы (указание количества повторений)
| Шаблон | Описание | Пример | Применяем к тексту |
|---|---|---|---|
| Ровно n повторений | 1, 12, 123, 1234, 12345 | ||
| От m до n повторений включительно | 1, 12, 123, 1234, 12345 | ||
| Не менее m повторений | 1, 12, 123, 1234, 12345 | ||
| Не более n повторений | 1, 12, 123 | ||
| Ноль или одно вхождение, синоним | вал, валы, валов | ||
| Ноль или более, синоним | СУ, СУ1, СУ12, … | ||
| Одно или более, синоним | a), a)), a))), ba)]) | ||
| По умолчанию квантификаторы жадные — захватывают максимально возможное число символов. Добавление делает их ленивыми, они захватывают минимально возможное число символов |
(a + b) * (c + d) * (e + f)(a + b) * (c + d) * (e + f) |
Жадность в регулярках и границы найденного шаблона
Как указано выше, по умолчанию квантификаторы жадные. Этот подход решает очень важную проблему — проблему границы шаблона. Скажем, шаблон захватывает максимально возможное количество цифр. Поэтому можно быть уверенным, что перед найденным шаблоном идёт не цифра, и после идёт не цифра. Однако если в шаблоне есть не жадные части (например, явный текст), то подстрока может быть найдена неудачно. Например, если мы хотим найти «слова», начинающиеся на , после которой идут цифры, при помощи регулярки , то мы найдём и неправильные шаблоны:
re.match функция
re.match пытается сопоставить шаблон из исходного положения строки, если не согласующий стартовая позиция является успешным, матч () не возвращает ничего.
Синтаксис функции:
re.match(pattern, string, flags=0)
Параметры функции:
| параметры | описание |
|---|---|
| шаблон | Матч регулярное выражение |
| строка | Строка для соответствия. |
| флаги | Флаг, регулярное выражение соответствия используется для управления, например: соответствует ли чувствительны к регистру, многострочный, и так далее. |
Успешный метод матча re.match возвращает объект соответствия, в противном случае None.
Мы можем использовать эту группу (NUM) или группы () функцию, чтобы получить объекты, соответствующие выражения совпадают.
| Соответствующие методы объекта | описание |
|---|---|
| группа (Num = 0) | Весь соответствующий строковое выражение, группа () может ввести более одного номера группы, в этом случае он будет возвращать значение, соответствующее этим группам кортежей. |
| группы () | Он возвращает кортеж из всех групп строки, от 1 до количества, содержащегося в группе. |
Пример 1:
#!/usr/bin/python
# -*- coding: UTF-8 -*-
import re
print(re.match('www', 'www.w3big.com').span()) # 在起始位置匹配
print(re.match('com', 'www.w3big.com')) # 不在起始位置匹配
Запуск в приведенном выше примере выход:
(0, 3) None
Пример 2:
#!/usr/bin/python3
import re
line = "Cats are smarter than dogs"
matchObj = re.match( r'(.*) are (.*?) .*', line, re.M|re.I)
if matchObj:
print ("matchObj.group() : ", matchObj.group())
print ("matchObj.group(1) : ", matchObj.group(1))
print ("matchObj.group(2) : ", matchObj.group(2))
else:
print ("No match!!")
Результаты приведенных выше примерах, являются следующими:
matchObj.group() : Cats are smarter than dogs matchObj.group(1) : Cats matchObj.group(2) : smarter
Строки
Строки в Python обособляются кавычками двойными «»» или одинарными «’». Внутри двойных ковычек могут присутствовать одинарные или наоборот. К примеру строка «Он сказал ‘привет’!» будет выведена на экран как «Он сказал ‘привет’!». Если нужно использовать строку из несколько строчек, то эту строку надо начинать и заканчивать тремя двойными кавычками «»»»». Вы можете подставить в шаблон строки элементы из кортежа или словаря. Знак процента «%» между строкой и кортежем, заменяет в строке символы «%s» на элемент кортежа. Словари позволяют вставлять в строку элемент под заданным индексом. Для этого надо использовать в строке конструкцию «%(индекс)s». В этом случае вместо «%(индекс)s» будет подставлено значение словаря под заданным индексом.
Функция python re.sub ()
Функция Re.sub () заменяет одну или много совпадений со строкой в данном тексте. Поиск и замена происходят слева направо.
В этом руководстве мы узнаем, как использовать функцию re.sub () с помощью примеров программ.
Синтаксис – Re.Sub ()
Синтаксис функции re.sub ()
re.sub(pattern, repl, string, count=0, flags=0)
где
| шаблон | Шаблон, который должен быть найден в строке. |
| рентген | Значение, которое должно быть заменено в строку вместо сопоставленного шаблона. |
| нить | Строка, в которой должна быть сделана замена. |
| считать | Максимальное количество вхождений шаблонов, которые должны быть заменены. |
| флаги | Дополнительные флаги, такие как Re.ignorecase и т. Д. |
Возвращаемое значение
Функция возвращает объект списка.
Пример 1: re.sub () – заменить сопоставления шаблона с заменой строки
В этом примере мы возьмем строку и замените шаблоны, которые содержат непрерывное возникновение чисел со строкой Отказ Мы сделаем замену, используя функцию re.sub ().
Python Program
import re
pattern = '+'
string = 'Account Number - 12345, Amount - 586.32'
repl = 'NN'
print('Original string')
print(string)
result = re.sub(pattern, repl, string)
print('After replacement')
print(result)
Выход
Original string Account Number - 12345, Amount - 586.32 After replacement Account Number - NN, Amount - NN.NN
Пример 2: re.sub () – ограничить максимальное количество замены
Мы можем ограничить максимальное количество замены функции re.sub (), указав счет дополнительный аргумент.
В этом примере мы возьмем один и тот же шаблон, строку и замену, как в предыдущем примере. Но мы ограничим максимальное количество замены на 2.
Python Program
import re
pattern = '+'
string = 'Account Number - 12345, Amount - 586.32'
repl = 'NN'
print('Original string')
print(string)
result = re.sub(pattern, repl, string, count=2)
print('After replacement')
print(result)
Выход
Account Number - 12345, Amount - 586.32 After replacement Account Number - NN, Amount - NN.32
Только два сопоставления с рисунком заменяется на замену строки. Остальные совпадения не заменяются.
Пример 3: re.sub () – Дополнительные флаги
В этом примере мы пройдем дополнительные флаги аргумента Для функции re.sub (). Этот флаг сообщает FUNCH RE 2SSUB (), чтобы игнорировать случай, когда сопоставляя шаблон в строке.
Python Program
import re
pattern = '+'
string = 'Account Number - 12345, Amount - 586.32'
repl = 'AA'
print('Original string')
print(string)
result = re.sub(pattern, repl, string, flags=re.IGNORECASE)
print('After replacement')
print(result)
Выход
Original string Account Number - 12345, Amount - 586.32 After replacement AA AA - 12345, AA - 586.32
Резюме
В этом учете примеров Python мы узнали, как использовать функцию Re.sub () для замены или замены всех совпадений для данного шаблона в строке с помощью строки замены с помощью примерных программ.
Методы
Есть несколько доступных методов использования регулярных выражений. Здесь мы собираемся обсудить некоторые из наиболее часто используемых методов, а также привести несколько примеров того, как они используются. Эти методы включают:
- re.match();
- исследовать();
- re.findall();
- re.split();
- re.sub();
- re.compile().
re.match(шаблон, строка, флаги = 0)
Это выражение используется для сопоставления символа или набора символов в начале строки
Также важно отметить, что это выражение будет соответствовать только в начале строки, если данная строка состоит из нескольких строк.. Выражение ниже вернет None, потому что Python не появляется в начале строки.
Выражение ниже вернет None, потому что Python не появляется в начале строки.
# match.py import re result = re.match(r'Python', 'It\'s easy to learn Python. Python also has elegant syntax') print(result)
$ python match.py None
re.search(шаблон, строка)
Этот модуль будет проверять совпадение в любом месте заданной строки и возвращать результаты, если они найдены, и None, если они не найдены.
В следующем коде мы просто пытаемся определить, появляется ли слово «щенок» в строке «Дейзи нашла щенка».
# search.py
import re
if re.search("puppy", "Daisy found a puppy."):
print("Puppy found")
else:
print("No puppy")
Здесь мы сначала импортируем модуль re и используем его для поиска вхождения подстроки «щенок» в строке «Дейзи нашла щенка». Если он существует в строке, возвращается объект re.MatchObject, который считается «правдивым» при оценке в операторе if.
$ python search.py Puppy found
re.compile(шаблон, флаги = 0)
Этот метод используется для компиляции шаблона регулярного выражения в объект регулярного выражения, который можно использовать для сопоставления с помощью его методов match() и search(), которые мы обсуждали выше. Это также может сэкономить время, поскольку выполнение синтаксического анализа или обработки строк регулярных выражений может быть дорогостоящим в вычислительном отношении.
# compile.py
import re
pattern = re.compile('Python')
result = pattern.findall('Pythonistas are programmers that use Python, which is an easy-to-learn and powerful language.')
print(result)
find = pattern.findall('Python is easy to learn')
print(find)
$ python compile.py
Обратите внимание, что возвращается только соответствующая строка, в отличие от всего слова в случае «Pythonistas». Это более полезно при использовании строки регулярного выражения, в которой есть специальные символы соответствия.
re.sub(шаблон, repl, строка)
Как следует из названия, это выражение используется для поиска и замены новой строки в случае появления шаблона.
# sub.py import re result = re.sub(r'python', 'ruby', 'python is a very easy language') print(result)
$ python sub.py ruby is a very easy language
re.findall(шаблон, строка)
Как вы видели до этого раздела, этот метод находит и извлекает список всех вхождений в данной строке. Он сочетает в себе функции и свойства re.search() и re.match(). В следующем примере из строки будут извлечены все вхождения «Python».
# findall.py import re result = re.findall(r'Python', 'Python is an easy to learn, powerful programming language. Python also has elegant syntax') print(result)
$ python findall.py
Опять же, использование такой строки точного соответствия действительно полезно только для определения того, встречается ли строка регулярного выражения в данной строке или сколько раз.
re.split(шаблон, строка, maxsplit = 0, flags = 0)
Это выражение разделит строку в том месте, где в строке встречается указанный шаблон. Он также вернет текст всех групп в шаблоне, если в шаблоне используется расширенная функция, такая как захват круглых скобок.
# split.py
import re
result = re.split(r"y", "Daisy found a puppy")
if result:
print(result)
else:
print("No puppy")
Как вы можете видеть выше, образец символа «y» встречается три раза, и выражение разделено во всех случаях, где оно встречается.
$ python split.py
Выводы
Плюсы:
- Генераторы — невероятно полезный инструмент для решения многообразных проблем
- Сила исходит от способности настраивать пайплайны
- Можно создавать компоненты, которые можно переиспользовать в разных пайплайнах
- Небольшие компоненты, которые просто обрабатывают поток данных
- Намного проще, чем это может быть сделано с помощью ООП шаблонов
- Можно расширить идею пайплайнов во многих направлениях (сеть, потоки, корутины)
Минусы
Использование этого стиля программирования у непосвященных может привести к взрыву головы
Обработка ошибок сложна, потому что у нас много компонентов, связанных вместе
Необходимо уделять особое внимание отладке, надежности и другим вопросам.