Обзор программы словоеб: установка, первичная настройка и основные функции 20.11.2015
Содержание:
Парсинг поисковых фраз в Словоебе
Познакомившись с интерфейсом этой замечательной программы и проставив все нужные настройки, пора переходить к процессу парсинга поисковых запросов из сервиса статистики Яндекса. Далее я расписал пошаговый план сбора будущих ключевых слов в Словоебе. Для примера использовал данные Вордстата по запросу «инфобизнес».
Создаем новый проект (или открываем готовый). В самом начале парсинга нужно сделать свой проект, в котором будут находиться нужные нам поисковые фразы по заданным словам. Обычно каждый проект у меня называется по одной теме.
Указываем стоп-слова. Если мы знаем, какие слова мы не хотели бы видеть в спарсенных поисковых запросах, то их необходимо прописать. Например, для коммерческого сайта этими словами будут «бесплатно», «халява», «скачать» и т.д. Таким образом мы облегчаем процесс сбора будущих ключевиков.
Выбираем регион продвижения. Для того, чтобы получить реальные параметры спарсенных поисковых запросов, необходимо задать нужный регион (аналогичный в сервисе Вордстат). Например, если Ваш блог продвигается по всей России, то в программе необходимо назначить такую же географическую область. Обычно я использую регион «Москва» или «Россия». В данном примере взят второй вариант. Выбрав регион, нажимаем левую кнопку парсинга Вордстата (кнопка №5) и получаем таблицу данных с поисковыми запросами и базовыми частотностями:
Фильтруем полученные запросы. Когда процесс сбора всех поисковых запросов закончился, мы должны пробежаться по ним и удалить те фразы, которые не подходят для нашей тематики. Поверьте, в каждой теме таких слов бывает достаточно. Но их обязательно нужно удалить, потому что они никак не дадут нам ключевые слова для продвижения нашего блога. Чтобы удалить их, сначала надо их выделить в таблице (с помощью чек-боксов):
Затем подводим мышку к нашей таблице с поисковыми фразами, нажимаем ее правую кнопку и в выпадающем меню выбираем соответствующую команду удаления:
Таким образом на выходе мы получаем уже тематические слова по нашим заданным фразам со своими базовыми частотностями. Теперь можно получить и другие параметры поисковых фраз, благодаря которым мы сможем выбрать самые качественные будущие ключевые слова.
Собираем точные частотности. На этом этапе парсинга нашей задачей является получение уточняющих параметров запросов от пользователей поисковых систем — они будут нужны при отборе качественных ключевых слов. Для этого нажимаем кнопку по сбору частотностей (на картинке интерфейса — элемент под номером 7) и выбираем из появившегося меню строку «Собрать частотности !» (картинка справа).
Удаляем слова-пустышки. После того, как в таблице данных наши спарсенные поисковые фразы получат свое значение точной частотности, необходимо удалить из нее так называемые слова-пустышки (точная частотность которых крайне мала и обычно имеет значение от 0 до 2). Удалить можно таким же способом, который показан выше по тексту.
В итоге мы получаем таблицу с данными частотностей для каждого полученного из поиска запроса. Теперь можно сделать ряд дополнительных действий (узнать конкуренцию по версии Словоеба, определить самую релевантную страницу по каждому ключевику) или экспортировать полученные поисковые фразы для дальнейшей обработки.
Таким образом, мы прошли весь процесс парсинга левой колонки Вордстата. Если нам необходимо для расширения тематики узнать дополнительные слова, можно воспользоваться парсингом правой колонки (процесс сбора запросов там такой же, какой мы сейчас рассмотрели).
Как правильно пользоваться Словоеб
Если вы не против, то я буду показывать процесс работы опять-таки с помощью скриншотов из КейКоллектора. Конечно же вы не против. И давайте тогда рассмотрим например, как собрать ключевые слова для настройки Яндекс-Директа.
Парсинг базового ключа
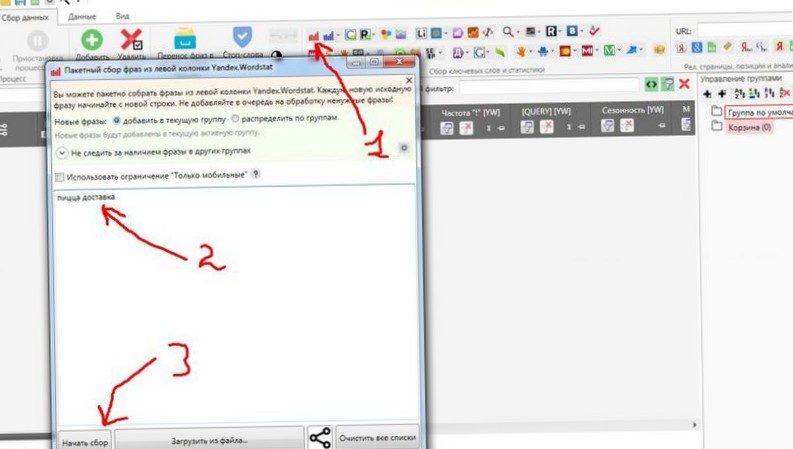
Первым делом нам надо распарсить наш базовый ключ. Допустим, мы настраиваем рекламу для доставки пиццы на дом. Нашим базовым ключом в этом случае будет «доставка пицца» или просто «пицца». Но ввести просто «пицца» — значит обречь себя на долгую ручную чистку списка ключей от всяких «рецептов пиццы в домашних условиях».
Поэтому давайте возьмем «доставка пицца». Создайте новый проект, и перед началом работы обязательно укажите регион, в котором вы собираетесь рекламироваться.

Если это вся Россия, то ничего не меняйте.
Теперь мы нажимаем на кнопочку парсинга Вордстат и вводим наш базовый ключ.
Программа начинает работать, а мы можем пока перекурить и оправиться.
Через некоторое время все процессы остановятся — значит парсинг завершен. И мы увидим список ключевых слов, которые нам подобрал Словоеб.
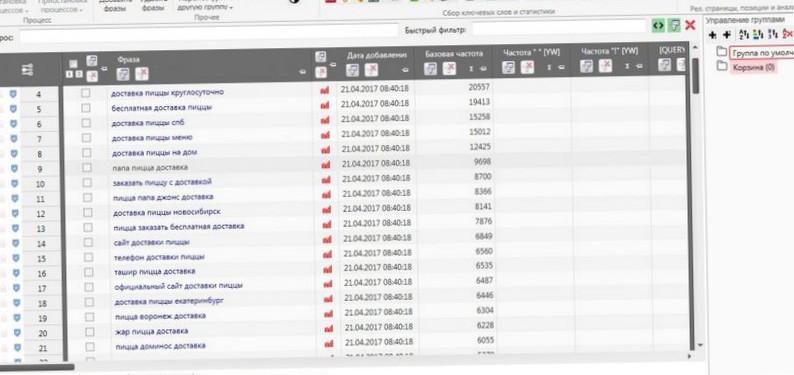
Но при этом он нам показывает только «базовую частотность». То есть мы видим не точное количество запросов в месяц того или иного ключа, а общее количество запросов основного ключа + хвост.
Например, в списке, выданном Словоебом есть основной ключ «Телефон доставки пиццы». И значение — 6560 запросов в месяц. Это значит 1000 запросов «телефон доставки пиццы» + еще 1000 запросов «телефон пицца доставка» + еще и еще.
А нам нужны точные значения, иначе мы никогда не сможем прогнозировать — какое количество трафика в месяц мы получим, и сколько мы с этого сможем заработать.
Поэтому переходим ко второй части парсинга — к Директу.
Узнаем точное количество запросов
Для того, чтобы узнать точное количество запросов к каждому ключу, мы нажимаем на синий значок Яндекс-Директа.

Обратите внимание на галочку «Целью запуска является сбор частотностей для колонок Вордстата». То есть в основном эта функция как раз и используется для того, чтобы узнать точные показатели запросов. Конечно, он вам может показать еще стоимость клика по тому или иному запросу в Директе, но я никогда этим не пользуюсь
Слишком большая нагрузка на программу, и слишком неточные получаются результаты
Конечно, он вам может показать еще стоимость клика по тому или иному запросу в Директе, но я никогда этим не пользуюсь. Слишком большая нагрузка на программу, и слишком неточные получаются результаты.
Если вам нужны данные по точной словоформе, то можно еще поставить галочку в поле «!». После этого нажимаем «Получить данные» и опять отправляемся пить кофе.
Вот что теперь мы имеем:
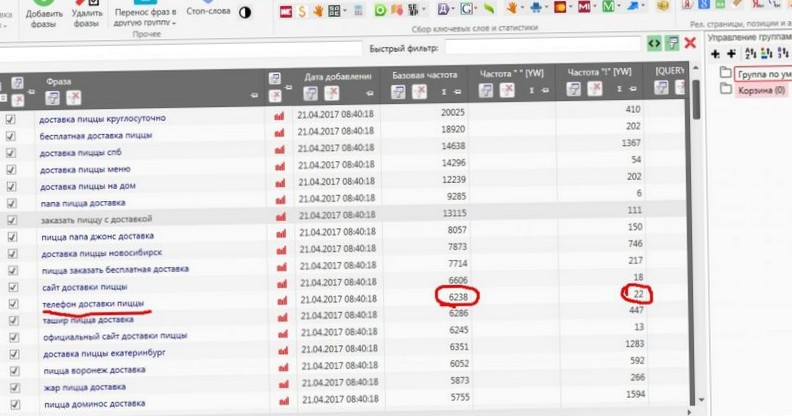
Как вы видите, наш такой перспективный ключ «телефон доставки пиццы» запрашивают на самом деле не шесть тысяч раз в месяц, а всего 22 раза в месяц. А мы-то уже губы раскатали.
Теперь, когда у нас есть объективные результаты, мы можем переходить к следующим этапам настройки. Это будет фильтр слов. То есть нам надо удалять те ключевые запросы, которые нам явно не подходят. Делать это можно прямо в интерфейсе Словоеба, или можете сначла выгрузить результаты в эксель и работать там. Давайте рассмотрим второй вариант.
Экспорт результатов
Для того, чтобы выгрузить полученные данные, нажмите на значок «эксель» в левом верхнем углу интерфейса, и укажите, куда надо сохранить файл.

Когда вы откроете файл, то увидите примерно вот такую картину:

Теперь вы можете спокойно удалять ненужные ключевые запросы, оставляя только те, по которым к вам точно придут клиенты. После этого вам еще надо будет создать рекламные объявления для каждого запроса. Об этом мы уже говорим подробнее в статье «Как самому настроить контекстную рекламу».
Где скачать и как установить
Скачать последнюю версию программы можно на официальном сайте разработчика seom.info. Не бойтесь, никаких вирусов и троянов там нет. Также можете почитать блог автора, он там частенько делиться полезными фишками и опытом в продвижении. Короче разберетесь.
Скачиваем архив, распаковываем его на свой ПК. Программа не требует установки, единственное для ее работы необходимо установить .NET Framework 4.0, если он у вас еще не установлен. Ссылка также есть на сайте производителя.
Для любителей продукции Apple новости печальные. Для работы Словоеба придется заморочиться и установить VirtualBox на свой Мак или другие приложения для запуска среды Window. Пока, к сожалению, аналогов программы под Мак OS нет. И это, печалька.
Словоеб: настройка
Наиболее распространенное назначение Словоёба – это упрощенный поиск ключевых слов. Вместо того чтобы вручную искать «ключи» в Яндекс.Wordstat, сделаем это автоматически.
Для начала нужно скачать последнюю версию программы Словоёб по этой ссылочке — seom.info/new/SlovoEB . Это блог от создателей Словоёба и его расширенной версии — Key Collector.
Распаковываем архив, запускаем файл Slovoeb.exe. Появляется окошко, в котором выбираем функцию «Создать новый проект».
Перед тем, как приступить к работе, нужно внести некоторые корректировки в настройках. Открываем в Словоёбе Настройки, выбираем вкладку «Парсинг» — «Yandex.Direct». Здесь вводим свой логин и пароль в Яндекс (т.е. нужно там для начала зарегистрироваться).

Обратите внимание на красный текст: нужно завести новый ящик на яндексе специально для парсинга, потому что его в любой момент могут забанить. В данном случае, как показано в примере на картинке, мой логин – slovoeb2014, пароль – slovo0108
Без ввода этих данных программа работать не будет.
Еще один важный момент в настройках, это параметр «Задержка между запросами» (см. скриншот).
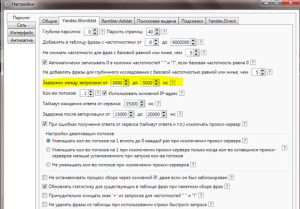
По умолчанию после установки в этой графе в закладке Yandex.Wordstat стоит значение от 5000 до 15000 мс. Это много, программа будет медленно собирать данные с Wordstat. Лучше поставить значение 3000—5000 мс. Может произойти так, что появится ошибка в программе Словоёб: «аккаунт вычеркнут из списка». Возможно, Яндекс заподозрил вас в автоматическом сборе информации. Если это случится, попробуйте увеличить интервал между запросами. У меня с приведенными значениями пока проблем не возникало.
В остальные настройки вы можете вносить свои корректировки в зависимости от потребностей проекта. Например, глубина парсинга – это количество страниц с запросами, которые выдает Яндекс.Wordstat для той, или иной фразы. Можете уменьшить его значение, чтобы сократить количество пустых запросов.
Цели и задачи новой программы Slovoeb
Создатель софта и ее предназначение
Словоеб (по английски slovoeb) — уникальный seo-инструмент для эффективного сбора и анализа поисковых фраз, не требующий материальных вложений со стороны веб-мастера (бесплатен). Он является младшим братом профессиональной программы по сбору семантического ядра Key Collector, с идентичным интерфейсом и базовым набором парсинга. Парсинг — это процесс сбора поисковых запросов из различных источников (статистика поисковых систем, анализ конкурентов, данные по веб аналитике и т.д.). Словоеб использует для своего парсинга статистику Яндекса — WordStat и данные системы LiveInternet.
Программу slovoeb придумал известный индивидуальный предприниматель и специалист Александр Люстик, автор блога seom.info. Он хотел найти эффективный способ обработки и анализа поисковых запросов. Ориентация конечно была сделана в первую очередь для платной Key Collector, но все базовые функции для хорошего сбора семантики прекрасно реализованы и в бесплатном аналоге.
Люстик, автор блога seom.info. Он хотел найти эффективный способ обработки и анализа поисковых запросов. Ориентация конечно была сделана в первую очередь для платной Key Collector, но все базовые функции для хорошего сбора семантики прекрасно реализованы и в бесплатном аналоге.
Как бесплатно скачать программу Словоеб
Последнюю версию Словоеба от 21 октября 2013 года можно скачать здесь. Для ее работы обязательным условием является наличие дополнительного расширения — Microsoft .NET Framework 4.0 Full.
Итак, что же умеет делать Словоеб, чем он будет полезен блоггеру для продвижения его блога в поисковых системах.
Основные инструменты программы slovoeb
- Парсинг сервиса Вордстат поисковика Яндекс. Словоеб умеет собирать все поисковые фразы, которые предоставляет статистика WordStat на каждый запрос своего посетителя. Сбор идет как из основной левой колонки сервиса, так и с правой. Никаких ограничений не существует — пользователь программы видит то же самое, что и любой веб-мастер, использующий статистику Яндекса вручную.
- Статистика сервиса Ливинтернет. Slovoeb предоставляет своему пользователю подробную раскладку по популярности поисковых запросов, которые он может использовать для сбора семантического ядра.
- Определение конкурентности запроса. Словоеб может показать пользователю число сайтов в сети Интернет (которые находятся в индексе поисковой системы Яндекс и Гугл) по заданному запросу. На основе этих данных можно приблизительно оценить конкуренцию (но только приблизительно!).
- Определение целевой страницы в Яндексе и Гугле. Софт определяет для каждого запроса самую релевантную страницу, которая находится на блоге или сайте веб-мастера. Критично для выполнения правильной внутренней перелинковки веб-ресурса.
Настройка и использование программы Словоеб
Интерфейс программы
Я уже отметил ранее, что Slovoeb весьма схож с его предшественником — программой Key Collector. В свою очередь разработчики снабдили Словоеб достаточно интуитивным и понятным интерфейсом. Именно благодаря этому в этой программе основные элементы меню и инструментов просты и понятны каждому блогеру.
Посмотрите интерфейс программы Словоеб:
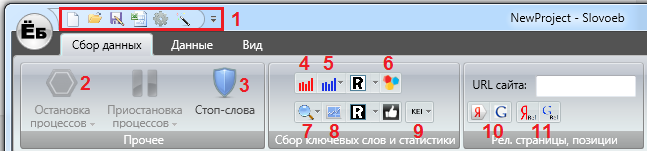
1 Элементы меню. С их помощью вы можете пользоваться своими созданными проектами в программе, а также осуществлять экспорт данных, которые собрали, в таблицу Exel для дальнейшего анализа. Здесь также расположены настройки программы.
2 Кнопка торможения запущенных процессов. Необходима для прекращения работы всех действующих процессов парсинга или конкретного отбора определенных данных. Применяется при разных обстоятельствах. Обычно, например, когда необходимо быстро остановить работу софта. К примеру, вы допустили ошибку при указании определенных первичных параметров для парсинга поисковых запросов.
3 Включение стоп-слов. Эта кнопка помогает пользователю программы Словоеб прописать перечень определенных ключевых слов, которые он не хочет видеть в результатах после парсинга запросов. Тем самым прога экономит ваше время при подборе ключевиков с помощью исключения из процесса парсинга ненужных вам запросов.
4 Парсинг слов из левой колонки сервиса WordStat. При помощи данной кнопки активизируется отбор запросов из левой колонки сервиса Яндекса. В конечном счёте, в результатах таблицы отражаются поисковые запросы с их базовой частотой.
5 Парсинг слов из правой колонки сервиса WordStat. Похожий сбор, как и из левой колонки данного сервиса статистики Яндекс.
6 Отбор подсказок из поиска. Эта кнопка отлично помогает получить подсказки для определённого поискового запроса от наиболее популярных поисковиков (Google, Yahoo , Rambler, Яндекс, Mail, и т.д.).
7 Подбор частоты поисковых фраз. При помощи данного элемента меню есть возможность собрать информацию по разным типам частоты ключевых фраз. При нажатии на данную кнопку появляется выпадающее меню, в котором можно выбрать наиболее подходящий вариант получения данных по искомым поисковым фразам для своего ресурса:
Кстати, немаловажная фишка в этой программе, которая позволяет подобрать наиболее подходящие и результативные ключевые запросы для раскрутки своей статьи.
8 Сезонность ключевых фраз. Данная кнопка необходима для получения данных об изменениях в частотности исследуемых поисковых запросов относительно сезонов года согласно статистике Яндекс Вордстат.
9 Вычисление конкуренции. Slovoeb даёт возможность услышать ответ на вот такой вопрос: «Какое количество веб-ресурсов, находящихся в индексе, имеют релевантный ответ на определённый поисковый запрос»:
Однако расчёт ведётся только на основании данных с поисковиков Яндекс и Google. При помощи выпадающего меню есть возможность отобрать различные варианты для выявления конкурентных запросов — система Яндекс, Google или все вместе.
10 Сбор статистики о позициях блога. Позволяет определять позиции страниц блога по заданным страницам в поисковиках Яндекс и Google.
11 Выявление наиболее релевантных статей. Slovoeb в состоянии указать для любого ключевого запроса самую релевантную статью на вашем блоге, которая максимально ему соответствует.
Для того, чтобы это осуществить вебмастеру достаточно просто указать доменное имя сайта или блога и воспользовавшись этой опцией узнать адрес наиболее релевантной статьи (по мнению поисковых систем Яндекс и Google). Эта фишка здорово может помочь в определении целевой страницы на своём блоге, которую необходимо оптимизировать под данный поисковый запрос.
Выбор региона сбора данных WordStat. С помощью этого элемента программы пользователь сможет прописать в настройках регион продвижения своего веб-ресурса. При этом в результатах парсинга будут отражаться только ключевые запросы и их характеристика, актуальные для региона, который вам интересен:

Установка Slovoeb в Linux
Для запуска Словоеб Ubuntu, нам нужна 32-битная система Windows, так что если в вас 64 бит нужно экспортировать специальную переменную, чтобы создать префикс 32 бит. Заодно и создадим новый префикс:
$ export WINEARCH=win32
Теперь переходим к установке всех необходимых компонентов. Их довольно таки много.
Установим шрифты:
Установим компоненты среды выполнения Microsoft Visual Runtime:
Установим Flash плеер и ie8, браузер обязательно нужен чтобы выполнить запуск словоеб linux:
Начнем установку Microsoft Net Framework, нам нужна версия 4.0, но для ее установки необходимо будет установить и все предыдущие. Сначала выполните:
После завершения установки утилита откроет браузер и папку, скачайте установочный файл и скопируйте в открытую папку, затем еще раз выполните:
Теперь устанавливаем четвертую версию:
Дальше нам нужно установить пакет windowscodecs:
Но библиотека в 64-битной системе установится не полностью. Поэтому скачиваем библиотеку здесь и скидываем ее в папку ~/Slovoeb/drive_c/windows/system32/:
Теперь остался последний штрих. Скачиваем библиотеку msctf.dll для Windows XP и тоже скопируйте ее в ~/Slovoeb/drive_c/windows/system32/:
Дальше запускаем winecfg, переходим на вкладку библиотеки и нажимаем кнопку Добавить. Далее пишем *msctf и выбираем сторонняя (Windows).
Нажимаем Ok и выполняем команду, чтобы зарегистрировать библиотеку в системе:
Наконец загружаем самую последнюю версию Словоеб с официального сайта. Распаковываем в папку с загрузками:
И осталось запустить:
Все работает. Можете протестировать проверку позиций или сбор подсказок. Slovoeb Ubuntu отлично работает, точно так же как в в Windows. Если остались вопросы, пишите комментарии.
Обновление. Slovoeb прекрасно устанавливается и работает в 2019 по этой инструкции с wine 3.0. А вот KeyCollector запускается, но пока проект открыть невозможно. Видимо поддержка Microsoft NET 4.0 содержит еще много недоработок.
Дополнительные функции Словоёба
Кроме основных функций по сбору семантического ядра, есть также дополнительные: сбор данных сезонности, вычисление KEI, анализ релевантных страниц, сбор позиций сайта в ПС.
Сезонность указывает на то, зависит ли количество запросов от времени года, месяца.
Показатель KEI , может указать, по каким запросам из всего вашего списка лучше продвигаться. Это соотношение числа запросов по определенному «ключу» и количества продвигаемых по нему страниц конкурентов. Т.е. значение KEI покажет какие ключевые слова более удачны для продвижения, по каким из них и траффик хороший, и конкуренция невысокая.
Анализ релевантных страниц и сбор позиций в ПС – полезные опции для готового сайта. Первая поможет определить какие страницы больше подходят для заданного ключевого слова. Вторая – позицию сайта по определенному запросу.
Геозависимость . Перед началом сбора запросов, вам нужно указать регион, если ваш ресурс зависит от географии. Соответственно, программа будет показывать частотность и прочие значения по тому региону, который вы зададите. Если вас интересуют все пользователи интернетом, то оставьте эту графу без изменений.
Хочу предупредить также о том, что иногда могут случаться сбои программы. Это может произойти после обновления алгоритмов работы Яндекса. О том, как обновить Словоёб , подумают его разработчики. А вам нужно будет только скачать его новую версию по той же ссылке, которая указана в начале статьи.
На этом все. Мной были приведены основные принципы функционирования данного сервиса, и, надеюсь, вам будет проще разобраться с тем, как работать с программой Словоёб. Она вам послужит хорошим помощником при составлении семантического ядра и анализа ключевых слов.
Парсинг поисковых фраз в Словоебе
Познакомившись с интерфейсом этой замечательной программы и проставив все нужные настройки, пора переходить к процессу парсинга поисковых запросов из сервиса статистики Яндекса. Далее я расписал пошаговый план сбора будущих ключевых слов в Словоебе. Для примера использовал данные Вордстата по запросу «инфобизнес».
Создаем новый проект (или открываем готовый). В самом начале парсинга нужно сделать свой проект, в котором будут находиться нужные нам поисковые фразы по заданным словам. Обычно каждый проект у меня называется по одной теме.
Указываем стоп-слова. Если мы знаем, какие слова мы не хотели бы видеть в спарсенных поисковых запросах, то их необходимо прописать. Например, для коммерческого сайта этими словами будут «бесплатно», «халява», «скачать» и т.д. Таким образом мы облегчаем процесс сбора будущих ключевиков.
Выбираем регион продвижения. Для того, чтобы получить реальные параметры спарсенных поисковых запросов, необходимо задать нужный регион (аналогичный в сервисе Вордстат). Например, если Ваш блог продвигается по всей России, то в программе необходимо назначить такую же географическую область. Обычно я использую регион «Москва» или «Россия». В данном примере взят второй вариант. Выбрав регион, нажимаем левую кнопку парсинга Вордстата (кнопка №5) и получаем таблицу данных с поисковыми запросами и базовыми частотностями:
Фильтруем полученные запросы. Когда процесс сбора всех поисковых запросов закончился, мы должны пробежаться по ним и удалить те фразы, которые не подходят для нашей тематики. Поверьте, в каждой теме таких слов бывает достаточно. Но их обязательно нужно удалить, потому что они никак не дадут нам ключевые слова для продвижения нашего блога. Чтобы удалить их, сначала надо их выделить в таблице (с помощью чек-боксов):
Затем подводим мышку к нашей таблице с поисковыми фразами, нажимаем ее правую кнопку и в выпадающем меню выбираем соответствующую команду удаления:
Таким образом на выходе мы получаем уже тематические слова по нашим заданным фразам со своими базовыми частотностями. Теперь можно получить и другие параметры поисковых фраз, благодаря которым мы сможем выбрать самые качественные будущие ключевые слова.
Собираем точные частотности. На этом этапе парсинга нашей задачей является получение уточняющих параметров запросов от пользователей поисковых систем — они будут нужны при отборе качественных ключевых слов. Для этого нажимаем кнопку по сбору частотностей (на картинке интерфейса — элемент под номером 7) и выбираем из появившегося меню строку «Собрать частотности !» (картинка справа).
Удаляем слова-пустышки. После того, как в таблице данных наши спарсенные поисковые фразы получат свое значение точной частотности, необходимо удалить из нее так называемые слова-пустышки (точная частотность которых крайне мала и обычно имеет значение от 0 до 2). Удалить можно таким же способом, который показан выше по тексту.
В итоге мы получаем таблицу с данными частотностей для каждого полученного из поиска запроса. Теперь можно сделать ряд дополнительных действий (узнать конкуренцию по версии Словоеба, определить самую релевантную страницу по каждому ключевику) или экспортировать полученные поисковые фразы для дальнейшей обработки.
Таким образом, мы прошли весь процесс парсинга левой колонки Вордстата. Если нам необходимо для расширения тематики узнать дополнительные слова, можно воспользоваться парсингом правой колонки (процесс сбора запросов там такой же, какой мы сейчас рассмотрели).