Sql выражение where
Содержание:
- SQL Учебник
- Вставка строк в таблицу, содержащую автоинкрементируемое поле
- Обработка и выполнение SQL-запросов
- SQL References
- SQL SELECT TOP
- Пример — выбрать все поля из таблицы
- Получайте только нужные данные
- Решение для практического упражнения № 3:
- Как использовать компонент Select
- Подзапросы
- Select and Filter Data With MySQLi
- Примеры:
- HTML Теги
- Практическое упражнение №3
- Результаты запроса
SQL Учебник
SQL ГлавнаяSQL ВведениеSQL СинтаксисSQL SELECTSQL SELECT DISTINCTSQL WHERESQL AND, OR, NOTSQL ORDER BYSQL INSERT INTOSQL Значение NullSQL Инструкция UPDATESQL Инструкция DELETESQL SELECT TOPSQL MIN() и MAX()SQL COUNT(), AVG() и …SQL Оператор LIKESQL ПодстановочныйSQL Оператор INSQL Оператор BETWEENSQL ПсевдонимыSQL JOINSQL JOIN ВнутриSQL JOIN СлеваSQL JOIN СправаSQL JOIN ПолноеSQL JOIN СамSQL Оператор UNIONSQL GROUP BYSQL HAVINGSQL Оператор ExistsSQL Операторы Any, AllSQL SELECT INTOSQL INSERT INTO SELECTSQL Инструкция CASESQL Функции NULLSQL ХранимаяSQL Комментарии
Вставка строк в таблицу, содержащую автоинкрементируемое поле
Многие коммерческие продукты допускают использование автоинкрементируемых столбцов в таблицах, т.е. полей, значение которых формируется автоматически при добавлении новых записей. Такие столбцы широко используются в качестве первичных ключей таблицы, т.к. они автоматически обеспечивают уникальность. Типичным примером столбца такого типа является последовательный счетчик, который при вставке строки генерирует значение на единицу большее предыдущего значения (значения, полученного при вставке предыдущей строки).
Ниже приводится пример создания таблицы с автоинкрементируемым столбцом (code) в MS SQL Server.
|
CREATE TABLE ( IDENTITY(1,1) PRIMARY KEY , (4) NOT NULL , (1) NOT NULL , (6) NOT NULL , NOT NULL ) |
Автоинкрементируемое поле определяется посредством конструкции IDENTITY (1, 1). При этом первый параметр свойства IDENTITY (1) определяет, с какого значения начнется отсчет, а второй — какой шаг будет использоваться для приращения значения. Таким образом, в нашем примере первая вставленная запись будет иметь в столбце code значение 1, вторая — 2 и т.д.
Поскольку в поле code значение формируется автоматически, оператор
| INSERT INTO Printer_Inc VALUES (15, 3111, ‘y’, ‘laser’, 2599); |
приведет к ошибке, даже если в таблице нет строки со значением в поле code, равным 15. Поэтому для вставки строки в таблицу просто не будем указывать это поле точно так же, как и в случае использования значения по умолчанию, т.е.
|
INSERT INTO Printer_Inc (model, color, type, price) VALUES (3111, ‘y’, ‘laser’, 2599); |
В результате выполнения этого оператора в таблицу Printer_Inc будет вставлена информация о модели
3111 цветного лазерного принтера, стоимость которого равна $2599. В поле code окажется значение, которое только случайно может оказаться равным 15. В большинстве случаев этого оказывается достаточно, т.к. значение автоинкрементируемого поля, как правило, не несет никакой информации; главное, чтобы оно было уникальным.
Однако бывают случаи, когда требуется подставить вполне конкретное значение в автоинкрементируемое поле. Например, нужно перенести уже имеющиеся данные во вновь создаваемую структуру; при этом эти данные участвуют в связи «один-ко-многим» со стороны «один». Таким образом, мы не можем допустить тут произвола. С другой стороны, нам не хочется отказываться от автоинкрементируемого поля, т.к. оно упростит обработку данных при последующей эксплуатации базы данных.
Поскольку стандарт языка SQL не предполагает наличия автоинкрементируемых полей, то соответственно не существует и единого подхода. Здесь мы покажем, как это реализуется в MS SQL Server. Оператор
| SET IDENTITY_INSERT < имя таблицы > { ON | OFF }; |
отключает (значение ON) или включает (OFF) использование автоинкремента. Поэтому чтобы вставить строку со значением 15 в поле code, нужно написать
|
SET IDENTITY_INSERT Printer_Inc ON; INSERT INTO Printer_Inc(code, model, color, type, price) VALUES (15, 3111, ‘y’, ‘laser’, 2599); |
Обратите внимание, что список столбцов в этом случае является обязательным, т.е. мы не можем написать так:
|
SET IDENTITY_INSERT Printer_Inc ON; INSERT INTO Printer_Inc VALUES (15, 3111, ‘y’, ‘laser’, 2599); |
ни, тем более, так
|
SET IDENTITY_INSERT Printer_Inc ON; INSERT INTO Printer_Inc(model, color, type, price) VALUES (3111, ‘y’, ‘laser’, 2599); |
В последнем случае в пропущенный столбец code значение не может быть подставлено автоматически, т.к. автоинкрементирование отключено.
Важно отметить, что если значение 15 окажется максимальным в столбце code,то далее нумерация продолжится со значения 16. Естественно, если включить автоинкрементирование: SET IDENTITY_INSERT Printer_Inc OFF
Наконец, рассмотрим пример вставки данных из таблицы Product в таблицу Product_Inc, сохранив значения в поле code:
|
SET IDENTITY_INSERT Printer_Inc ON; INSERT INTO Printer_Inc(code, model,color,type,price) SELECT * FROM Printer; |
По поводу автоинкрементируемых столбцов следует еще сказать следующее. Пусть последнее значение в поле code было равно 16, после чего строка с этим значением была удалена. Какое значение будет в этом столбце после вставки новой строки? Правильно, 17, т.к. последнее значение счетчика сохраняется, несмотря на удаление строки, его содержащей. Поэтому нумерация значений в результате удаления и добавления строк не будет последовательной. Это является еще одной причиной для вставки строки с заданным (пропущенным) значением в автоинкрементируемом столбце.
Обработка и выполнение SQL-запросов
Чтобы повысить производительность вашего SQL-запроса, вам сначала нужно знать, что происходит, когда вы запускаете запрос на выполнение.
Во-первых, производится грамматический разбор и строится синтаксическое дерево запроса. Запрос анализируется с целью выявления того, насколько он удовлетворяет синтаксическим и семантическим требованиям. Парсер создает внутреннее представление входящего запроса. Затем это внутреннее представление передается обработчику кода.
Затем в дело вступает оптимизатор – его задача найти оптимальное выполнение или построить оптимальный план данного запроса. План выполнения точно определяет, какой алгоритм используется для каждой операции, и как координируется выполнение операций.
Чтобы действительно найти наиболее оптимальный план выполнения, оптимизатор рассчитывает все возможные планы выполнения, определяет качество или стоимость каждого плана, берет информацию о текущем состоянии базы данных и затем выбирает наилучший план как окончательный и пригодный для выполнения. Оптимизаторы запросов могут быть неидеальными, поэтому пользователям баз данных и администраторам иногда приходится вручную проверять и настраивать планы выполнения запросов, предложенные оптимизатором, чтобы повысить производительность выполнения запроса.
Теперь вы, вероятно, задаетесь вопросом, что считается «хорошим планом запроса».
Как вы уже прочитали выше, критерий стоимости плана играет огромную роль. А именно, для оценки плана необходимы такие вещи, как количество дисковых операций ввода-вывода, стоимость процессора и общее время отклика, которое может наблюдаться для клиента базы данных, а также общее время выполнения. Именно здесь появляется понятие временной сложности. Но об этом вы узнаете чуть позже.
Затем выполняется выбранный план запроса, они оцениваются механизмом выполнения системы и после этого возвращаются результаты вашего запроса.
Таким образом эту последовательность можно записать в виде следующего списка шагов (см. картинку с английской терминологией ниже):
- SQL-выражение
- Синтаксической разбор
- Компоновка
- Оптимизация запроса
- Выполнение запроса
-
Результаты запроса
Из предыдущего раздела может быть уже понятно, что принцип обработки «что на входе, то и на выходе» (Garbage In, Garbage Out (GIGO)) естественным образом распространяется на обработку и выполнение запроса: тот, кто формулирует запрос, также держит в руках и ключи от производительности SQL-запроса. Если оптимизатор получает плохо сформулированный запрос, он может только сделать так …
Это означает, что есть некоторые вещи, которые вы можете сделать, когда пишете запрос. Как мы уже во введении, ваша ответственность за качество написания запроса складывается из двух составляющих: в написании запросов, соответствующих определенному стандарту, и понимании того, где могут возникать проблемы при исполнении вашего запроса.
Идеальной отправной точкой является анализ узких мест в ваших запросах, то есть тех мест, в которых могут возникнуть проблемы. И, в общем, есть четыре причины и ключевых слова, где новичков могут ожидать проблемы с производительностью:
- Оператор ;
- Ключевые слова или ,
- Оператор .
Конечно, такой подход слишком прост и наивен, но для новичка эти утверждения являются хорошими указателями, и можно с уверенностью сказать, что, когда вы только начинаете, эти точки – как раз те места, где происходят неправильные действия и, как это ни парадоксально, где их также трудно обнаружить.
Тем не менее, вы также должны понимать, что производительность – это то, что понимается в определенном контексте: просто так сказать, что эти причины и ключевые слова плохи, не есть способ понимания производительности SQL запроса. То есть наличие предложения или в вашем запросе не обязательно означает, что это плохой запрос …
Прочитайте наш на следующий раздел, чтобы познакомиться подробнее с анти-шаблонами и альтернативными подходами к написанию запросов. Эти советы и трюки послужат для вас неким ориентиром. Нужно ли вам переписать свой запрос и как это сделать, если его действительно нужно переписать, зависит от количества данных, базы данных и количества раз, которое вам потребуется выполнять запрос. А здесь решающее значение имеет уже только цель вашего запроса и наличие некоторых предварительных знаний о структуре базе данных, к которой вы хотите обратиться!
SQL References
SQL Keywords
ADD
ADD CONSTRAINT
ALTER
ALTER COLUMN
ALTER TABLE
ALL
AND
ANY
AS
ASC
BACKUP DATABASE
BETWEEN
CASE
CHECK
COLUMN
CONSTRAINT
CREATE
CREATE DATABASE
CREATE INDEX
CREATE OR REPLACE VIEW
CREATE TABLE
CREATE PROCEDURE
CREATE UNIQUE INDEX
CREATE VIEW
DATABASE
DEFAULT
DELETE
DESC
DISTINCT
DROP
DROP COLUMN
DROP CONSTRAINT
DROP DATABASE
DROP DEFAULT
DROP INDEX
DROP TABLE
DROP VIEW
EXEC
EXISTS
FOREIGN KEY
FROM
FULL OUTER JOIN
GROUP BY
HAVING
IN
INDEX
INNER JOIN
INSERT INTO
INSERT INTO SELECT
IS NULL
IS NOT NULL
JOIN
LEFT JOIN
LIKE
LIMIT
NOT
NOT NULL
OR
ORDER BY
OUTER JOIN
PRIMARY KEY
PROCEDURE
RIGHT JOIN
ROWNUM
SELECT
SELECT DISTINCT
SELECT INTO
SELECT TOP
SET
TABLE
TOP
TRUNCATE TABLE
UNION
UNION ALL
UNIQUE
UPDATE
VALUES
VIEW
WHERE
MySQL Functions
String Functions
ASCII
CHAR_LENGTH
CHARACTER_LENGTH
CONCAT
CONCAT_WS
FIELD
FIND_IN_SET
FORMAT
INSERT
INSTR
LCASE
LEFT
LENGTH
LOCATE
LOWER
LPAD
LTRIM
MID
POSITION
REPEAT
REPLACE
REVERSE
RIGHT
RPAD
RTRIM
SPACE
STRCMP
SUBSTR
SUBSTRING
SUBSTRING_INDEX
TRIM
UCASE
UPPER
Numeric Functions
ABS
ACOS
ASIN
ATAN
ATAN2
AVG
CEIL
CEILING
COS
COT
COUNT
DEGREES
DIV
EXP
FLOOR
GREATEST
LEAST
LN
LOG
LOG10
LOG2
MAX
MIN
MOD
PI
POW
POWER
RADIANS
RAND
ROUND
SIGN
SIN
SQRT
SUM
TAN
TRUNCATE
Date Functions
ADDDATE
ADDTIME
CURDATE
CURRENT_DATE
CURRENT_TIME
CURRENT_TIMESTAMP
CURTIME
DATE
DATEDIFF
DATE_ADD
DATE_FORMAT
DATE_SUB
DAY
DAYNAME
DAYOFMONTH
DAYOFWEEK
DAYOFYEAR
EXTRACT
FROM_DAYS
HOUR
LAST_DAY
LOCALTIME
LOCALTIMESTAMP
MAKEDATE
MAKETIME
MICROSECOND
MINUTE
MONTH
MONTHNAME
NOW
PERIOD_ADD
PERIOD_DIFF
QUARTER
SECOND
SEC_TO_TIME
STR_TO_DATE
SUBDATE
SUBTIME
SYSDATE
TIME
TIME_FORMAT
TIME_TO_SEC
TIMEDIFF
TIMESTAMP
TO_DAYS
WEEK
WEEKDAY
WEEKOFYEAR
YEAR
YEARWEEK
Advanced Functions
BIN
BINARY
CASE
CAST
COALESCE
CONNECTION_ID
CONV
CONVERT
CURRENT_USER
DATABASE
IF
IFNULL
ISNULL
LAST_INSERT_ID
NULLIF
SESSION_USER
SYSTEM_USER
USER
VERSION
SQL Server Functions
String Functions
ASCII
CHAR
CHARINDEX
CONCAT
Concat with +
CONCAT_WS
DATALENGTH
DIFFERENCE
FORMAT
LEFT
LEN
LOWER
LTRIM
NCHAR
PATINDEX
QUOTENAME
REPLACE
REPLICATE
REVERSE
RIGHT
RTRIM
SOUNDEX
SPACE
STR
STUFF
SUBSTRING
TRANSLATE
TRIM
UNICODE
UPPER
Numeric Functions
ABS
ACOS
ASIN
ATAN
ATN2
AVG
CEILING
COUNT
COS
COT
DEGREES
EXP
FLOOR
LOG
LOG10
MAX
MIN
PI
POWER
RADIANS
RAND
ROUND
SIGN
SIN
SQRT
SQUARE
SUM
TAN
Date Functions
CURRENT_TIMESTAMP
DATEADD
DATEDIFF
DATEFROMPARTS
DATENAME
DATEPART
DAY
GETDATE
GETUTCDATE
ISDATE
MONTH
SYSDATETIME
YEAR
Advanced Functions
CAST
COALESCE
CONVERT
CURRENT_USER
IIF
ISNULL
ISNUMERIC
NULLIF
SESSION_USER
SESSIONPROPERTY
SYSTEM_USER
USER_NAME
MS Access Functions
String Functions
Asc
Chr
Concat with &
CurDir
Format
InStr
InstrRev
LCase
Left
Len
LTrim
Mid
Replace
Right
RTrim
Space
Split
Str
StrComp
StrConv
StrReverse
Trim
UCase
Numeric Functions
Abs
Atn
Avg
Cos
Count
Exp
Fix
Format
Int
Max
Min
Randomize
Rnd
Round
Sgn
Sqr
Sum
Val
Date Functions
Date
DateAdd
DateDiff
DatePart
DateSerial
DateValue
Day
Format
Hour
Minute
Month
MonthName
Now
Second
Time
TimeSerial
TimeValue
Weekday
WeekdayName
Year
Other Functions
CurrentUser
Environ
IsDate
IsNull
IsNumeric
SQL Quick Ref
SQL SELECT TOP
Инструкция SELECT TOP используется для указания количества возвращаемых записей.
Инструкция SELECT TOP полезно для больших таблиц с тысячами записей. Возврат большого количества записей может повлиять на производительность.
Примечание: Не все базы данных поддерживают SELECT TOP.
MySQL поддерживает предложение LIMIT для выбора ограниченного числа записей, в то время как Oracle использует ROWNUM.
Синтаксис SQL Server / MS Access:
SELECT TOP number|percent column_name(s)
FROM table_nameWHERE condition;
Синтаксис MySQL:
SELECT column_name(s)
FROM table_nameWHERE condition
LIMIT number;
Синтаксис Oracle:
SELECT column_name(s)
FROM table_name
WHERE ROWNUM <= number;
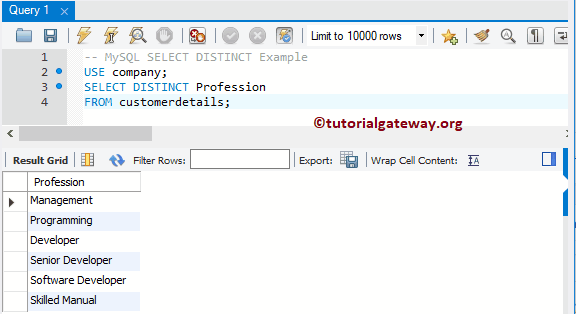
Пример — выбрать все поля из таблицы
Давайте рассмотрим пример, который показывает, как использовать SQL запрос SELECT для выбора всех полей в таблице.
В этом примере у нас есть таблица customers со следующими данными:
| customer_id | first_name | last_name | favorite_website |
|---|---|---|---|
| 4000 | Justin | Bieber | google.com |
| 5000 | Selena | Gomez | bing.com |
| 6000 | Mila | Kunis | yahoo.com |
| 7000 | Tom | Cruise | oracle.com |
| 8000 | Johnny | Depp | NULL |
| 9000 | Russell | Crowe | google.com |
Теперь давайте продемонстрируем, как работает оператор SELECT, выбрав все столбцы из таблицы customers. Введите следующий запрос SELECT.
PgSQL
SELECT *
FROM customers
WHERE favorite_website = ‘google.com’
ORDER BY last_name ASC;
|
1 |
SELECT* FROMcustomers WHEREfavorite_website=’google.com’ ORDERBYlast_nameASC; |
Будет выбрано 2 записи. Вот результаты, которые вы должны получить.
| customer_id | first_name | last_name | favorite_website |
|---|---|---|---|
| 4000 | Justin | Bieber | google.com |
| 9000 | Russell | Crowe | google.com |
В этом примере мы использовали *, чтобы показать, что мы хотим просмотреть все поля из таблицы customers, где favorite_website — ‘google.com’. Набор результатов сортируется по last_name в порядке возрастания.
Получайте только нужные данные
Идеология «чем больше данных, тем лучше» ‑ это не то, что вам нужно для написания SQL-запросов: вы рискуете не только затуманить свои идеи, получая данных на много больше, чем вам нужно, но также производительность вашего запроса может пострадать от того, что он будет выбираться слишком много данных.
Вот почему обычно рекомендуется заботиться об инструкции , операторах и .
Первое, что вы уже можете проверить, когда вы написали свой запрос, является ли оператор максимально возможно компактным. При этом ваша цель – удалить ненужные столбцы из оператора . Таким образом вы будете запрашивать только те данные, которые служат цели вашего запроса.
Помните, что коррелированный подзапрос – это подзапрос, который использует значения из внешнего запроса
И обратите внимание, что, хотя и может здесь использоваться в качестве «константы», это выглядит очень запутанно для понимания вашего запроса другими разработчиками!. Рассмотрим следующий пример, чтобы понять, что мы подразумеваем под использованием константы:
Рассмотрим следующий пример, чтобы понять, что мы подразумеваем под использованием константы:
SELECT driverslicensenr, name
FROM Drivers
WHERE EXISTS (SELECT '1' FROM Fines
WHERE fines.driverslicensenr = drivers.driverslicensenr);
Совет: полезно знать, что наличие коррелированного подзапроса не является хорошей идеей. Вы всегда можете отказаться от него, например, переписав запрос через :
SELECT driverslicensenr, name FROM drivers INNER JOIN fines ON fines.driverslicensenr = drivers.driverslicensenr;
Оператор используется для возврата только различных значений. – это условие, которого, при возможности, лучше всего избегать. Как вы можете видеть и на других примерах, время выполнения увеличивается только в том случае, если вы добавили это предложение в свой запрос. Поэтому всегда стоит подумать над тем, действительно ли вам нужна операция , чтобы получить нужный вам результат.
Когда вы используете оператор в запросе, индекс не используется, если шаблон начинается с или . Эти шаблоны запрещают использование индексов базы данных (если он имеются). Ну и конечно, с другой стороны, этот тип запроса потенциально оставляет открытой возможность для извлечения слишком большого количества записей, которые не обязательно могут удовлетворять цели вашего запроса.
Отметим еще раз – знания структуры хранимых данных могут помочь вам сформулировать шаблон, который будет правильно фильтровать все данные, чтобы выбрать из базы только те строки, которые действительно важны для вашего запроса.
Решение для практического упражнения № 3:
Следующий Oracle оператор SELECT выберет записи из таблиц suppliers и orders (с помощью SQL INNER JOIN):
Oracle PL/SQL
SELECT suppliers.supplier_id,
suppliers.supplier_name,
orders.order_date
FROM suppliers
INNER JOIN orders
ON suppliers.supplier_id = orders.supplier_id
ORDER BY supplier_id DESC;
|
1 |
SELECTsuppliers.supplier_id, suppliers.supplier_name, orders.order_date FROMsuppliers INNERJOINorders ONsuppliers.supplier_id=orders.supplier_id ORDERBYsupplier_idDESC; |
В результате выборки получим:
| supplier_id | supplier_name | order_date |
|---|---|---|
| 5 | Amba | 12.01.2016 |
| 3 | Madlen | 12.02.2015 |
| 1 | Mari | 05.05.2014 |
Как использовать компонент Select
Компонент Select можно использовать на странице 2 способами.
Первый способ подразумевает непосредственную вставку HTML кода селекта на страницу:
<div class="select" id="select-1">
<div class="select__backdrop" data-select="backdrop"></div>
<button type="button" class="select__trigger" data-select="trigger">
Выберите из списка
</button>
<div class="select__dropdown">
<ul class="select__items">
<li class="select__item" data-select="item">Volkswagen</li>
<li class="select__item select__item_selected" data-select="item">Ford</li>
<li class="select__item" data-select="item">Toyota</li>
<li class="select__item" data-select="item">Nissan</li>
</ul>
</div>
</div>
В содержимое элемента необходимо поместить дефолтное значение. Это будет текущее значение. В — варианты (элементы с атрибутами ).
Если изначально какая-то опция должна быть активна, то к ней необходимо добавить класс . А также поместить её значение в кнопку.
После этого необходимо активировать эту структуру с помощью JavaScript как компонент Select.
Выполняется это посредством создания нового экземпляра объекта CustomSelect и передачей ему в качестве аргумента селектора:
const select1 = new CustomSelect('#select-1');
Второй способ предполагает использование Select без необходимости непосредственной вставки HTML структуры на страницу. Здесь достаточно лишь поместить контейнер (пустой элемент) в HTML документ.
<div id="select-1"></div>
Варианты и дефолтный текст (начальное значение) селекту необходимо передать при создании объекта в виде аргумента.
const select1 = new CustomSelect('#select-1', {
// текст (значение) по умолчанию
defaultValue: 'Ford',
// опции
data: ,
});
Если начальное значение не нужно устанавливать, то следует задать некоторый текст, не соответствующий ни одному из значений выбора или его вовсе не использовать (в этом случае будет выведен текст, прописанный в коде JavaScript).
После создания селекта программно управлять им можно посредством следующих методов:
- – для отображения выпадающего списка с вариантами;
- – для скрытия выпадающего списка;
- – для переключения состояния выпадающего списка;
- — для удаления обработчиков событий и элементов из DOM, связанных с этим селектом;
- – для получения выбранного варианта и его установки.
Если необходимо выполнить некоторые действия при изменении значения Select, то воспользуйтесь одним из следующих двух способов:
1 способ (используя событие ):
document.querySelector('#select-1').addEventListener('select.change', (e) => {
console.log(`Выбранное значение: ${ e.target.querySelector('.select__item_selected').textContent }`);
});
2 способ (через метод ):
const select1 = new CustomSelect('#select-1', {
defaultValue: 'Ford',
data: ,
onSelected(item) {
console.log(`Выбранное значение: ${item.textContent}`);
},
});
Подзапросы
На выходе подзапрос должен возвращать одно единственное значение (для страховки можно принудительно указывать LIMIT 1). Допускается использование подзапросов, которые на выходе выдают ряд значений, для оператора IN.
Операторы EXISTS, ANY(ANY и SOME абсолютно идентичны и являются взаимозаменяемыми),ALL умеют работать с множеством значений.
-
Пример. Использования подзапроса с оператором INSERT. В таблицу df_lcr_list передаются два значения(datestart и dateend), login_id ищется подзапросом по заранее известному имени пользователя, в таблицу вставляется текущее время.
INSERT INTO df_lcr_list (datestart,dateend,login_id, date_event) SELECT '20120405','20120405',id, now() FROM users WHERE login='username';
-
Пример. Использования подзапроса(subquery) с оператором UPDATE. Subquery выводит множество значений.
UPDATE accounts SET balance=0 WHERE uid IN (SELECT id FROM users WHERE email LIKE 'ltaixp1%');
Select and Filter Data With MySQLi
The following example selects the id, firstname and lastname columns from the MyGuests
table where the lastname is «Doe», and displays it on the page:
Example (MySQLi Object-oriented)
<?php$servername = «localhost»;$username = «username»;$password = «password»;$dbname = «myDB»;// Create connection$conn = new mysqli($servername, $username, $password, $dbname);// Check connectionif ($conn->connect_error) { die(«Connection failed: » . $conn->connect_error);
} $sql = «SELECT id, firstname, lastname FROM MyGuests WHERE
lastname=’Doe'»;$result = $conn->query($sql);if ($result->num_rows > 0) { // output data of each row while($row = $result->fetch_assoc()) { echo «id: » . $row. » — Name: » . $row. » » . $row. «<br>»;
}} else { echo «0 results»;}
$conn->close();
?>
Code lines to explain from the example above:
First, we set up the SQL query that selects the id, firstname and lastname columns from the MyGuests
table where the lastname is «Doe». The next line of code runs the query and puts the resulting data into a
variable called $result.
Then, the checks if there are more than zero
rows returned.
If there are more than zero rows returned, the
function puts all the results into an associative array that we can loop
through. The loop loops through the result set and outputs the data from
the id, firstname and lastname columns.
The following example shows the same as the example above, in the MySQLi procedural way:
Example (MySQLi Procedural)
<?php$servername = «localhost»;$username = «username»;$password = «password»;$dbname = «myDB»;// Create connection
$conn = mysqli_connect($servername, $username, $password, $dbname);
// Check connection
if (!$conn) {
die(«Connection failed: » . mysqli_connect_error());}$sql = «SELECT id, firstname, lastname FROM MyGuests
WHERE lastname=’Doe'»;$result = mysqli_query($conn, $sql);if (mysqli_num_rows($result) > 0) { // output data of each row
while($row = mysqli_fetch_assoc($result)) { echo «id: » . $row. » — Name: » . $row. » » . $row. «<br>»;
}} else { echo «0 results»;}mysqli_close($conn);
?>
You can also put the result in an HTML table:
Example (MySQLi Object-oriented)
<?php$servername = «localhost»;$username = «username»;$password = «password»;$dbname = «myDB»;// Create connection$conn = new mysqli($servername, $username, $password, $dbname);// Check connectionif ($conn->connect_error) { die(«Connection failed: » . $conn->connect_error);
} $sql = «SELECT id, firstname, lastname FROM MyGuests WHERE
lastname=’Doe'»;$result = $conn->query($sql);if ($result->num_rows > 0) { echo «<table><tr><th>ID</th><th>Name</th></tr>»;
// output data of each row while($row = $result->fetch_assoc()) { echo «<tr><td>».$row.»</td><td>».$row.» «.$row.»</td></tr>»;
} echo «</table>»;} else { echo «0 results»;}
$conn->close();
?>
Примеры:
В следующих примерах используется база данных AdventureWorksPDW2012.
Б. Использование SELECT с заголовками столбцов и вычислениями
В следующем примере возвращаются все строки из таблицы DimEmployee и вычисляется заработная плата до вычетов для каждого сотрудника на основе их BaseRate и с учетом 40-часовой рабочей недели.
Д. Использование GROUP BY с несколькими группами
В следующем примере вычисляются значения средней цены и суммы продаж через Интернет за каждый день, сгруппированные по дате заказа и ключу продвижения.
Е. Использование GROUP BY и WHERE
В следующем примере после извлечения строк, содержащих даты заказов позднее 1 августа 2002 г., происходит их разделение на группы.
Ж. Использование GROUP BY с выражением
В следующем примере производится группировка с помощью выражения. Группировку можно производить только с помощью выражения, не содержащего агрегатных функций.
HTML Теги
<!—…—><!DOCTYPE><a><abbr><acronym><address><applet><area><article><aside><audio><b><base><basefont><bdi><bdo><big><blockquote><body><br><button><canvas><caption><center><cite><code><col><colgroup><data><datalist><dd><del><details><dfn><dialog><dir><div><dl><dt><em><embed><fieldset><figcaption><figure><font><footer><form><frame><frameset><h1> — <h6><head><header><hr><html><i><iframe><img><input><ins><kbd><label><legend><li><link><main><map><mark><meta><meter><nav><noframes><noscript><object><ol><optgroup><option><output><p><param><picture><pre><progress><q><rp><rt><ruby><s><samp><script><section><select><small><source><span><strike><strong><style><sub><summary><sup><svg><table><tbody><td><template><textarea><tfoot><th><thead><time><title><tr><track><tt><u><ul><var><video>
Практическое упражнение №3
На основании таблиц suppliers и orders ниже, выберите поля supplier_id и supplier_name из таблицы suppliers, и выберите поле order_date из таблицы orders, где значение поля supplier_id в таблице suppliers соответствует значению поля supplier_id в таблице orders. Сортировать результаты по supplier_id в порядке убывания.
Oracle PL/SQL
—создаем таблицу suppliers
CREATE TABLE suppliers
( supplier_id int NOT NULL,
supplier_name char(50) NOT NULL,
city char(50),
state char(25),
CONSTRAINT suppliers_pk PRIMARY KEY (supplier_id)
);
—вставляем записи в таблицу suppliers
insert into suppliers values (1,’Mari’,’Houston’,’Texas’);
insert into suppliers values (2,’Frida’,’ Melbourne’, ‘Florida’);
insert into suppliers values (3,’Madlen’,’Phoenix’,’Arizona’);
insert into suppliers values (4,’Valentina’,’San Diego’,’California’);
insert into suppliers values (5,’Amba’,’Jacksonville’,’Florida’);
|
1 |
—создаем таблицу suppliers CREATETABLEsuppliers supplier_namechar(50)NOTNULL, citychar(50), statechar(25), CONSTRAINTsuppliers_pkPRIMARYKEY(supplier_id) insertintosuppliersvalues(1,’Mari’,’Houston’,’Texas’); insertintosuppliersvalues(2,’Frida’,’ Melbourne’,’Florida’); insertintosuppliersvalues(3,’Madlen’,’Phoenix’,’Arizona’); insertintosuppliersvalues(4,’Valentina’,’San Diego’,’California’); insertintosuppliersvalues(5,’Amba’,’Jacksonville’,’Florida’); |
Содержимое таблицы suppliers:
| supplier_id | supplier_name | city | state |
|---|---|---|---|
| 1 | Mari | Houston | Texas |
| 2 | Frida | Philadelphia | Pennsylvania |
| 3 | Madlen | Phoenix | Arizona |
| 4 | Valentina | SanDiego | California |
| 5 | Amba | Jacksonville | Florida |
Oracle PL/SQL
—создаем таблицу orders
CREATE TABLE orders
( order_id int NOT NULL,
supplier_id int NOT NULL,
order_date date NOT NULL,
quantity int,
CONSTRAINT orders_pk PRIMARY KEY (order_id)
);
—вставляем записи в таблицу orders
insert into orders values (1,1,’05.05.2014′,100);
insert into orders values (2,3,’12.02.2015′,300);
insert into orders values (3,5,’12.01.2016′,500);
|
1 |
—создаем таблицу orders CREATETABLEorders supplier_idintNOTNULL, order_datedateNOTNULL, quantityint, CONSTRAINTorders_pkPRIMARYKEY(order_id) insertintoordersvalues(1,1,’05.05.2014′,100); insertintoordersvalues(2,3,’12.02.2015′,300); insertintoordersvalues(3,5,’12.01.2016′,500); |
Содержимое таблицы orders:
| order_id | supplier_id | order_date | quantity |
|---|---|---|---|
| 1 | 1 | 05.05.2014 | 100 |
| 2 | 3 | 12.02.2015 | 300 |
| 3 | 5 | 12.01.2016 | 500 |
Результаты запроса
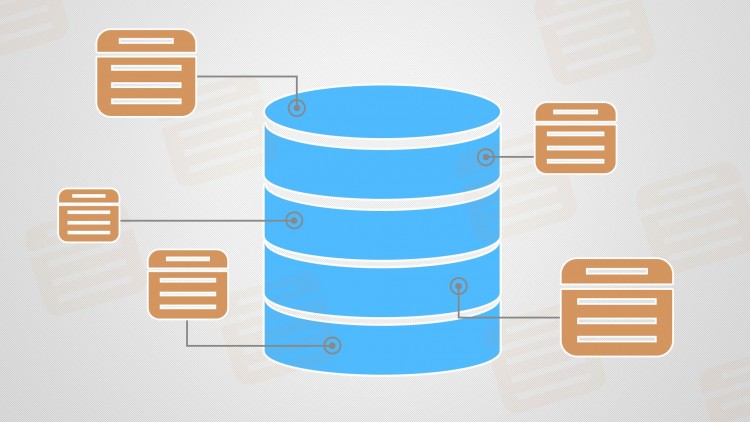
Результатом SQL-запроса на выборку всегда является таблица, содержащая данные и ничем не отличающаяся от таблиц базы данных. Если пользователь набирает инструкцию SQL в интерактивном режиме, СУБД выводит результаты запроса (которые некоторые производители именуют результирующим набором (result set)) на экран в табличной форме. Если программа посылает запрос СУБД с помощью программного SQL, то СУБД возвращает таблицу результатов запроса программе. В любом случае результаты запроса всегда имеют такой же формат, как и обычные таблицы, содержащиеся в базе данных, как показано на рис. 2. Обычно результаты запроса представляют собой таблицу с несколькими строками и столбцами. Например, запрос, приведенный ниже, возвращает таблицу из трех столбцов (поскольку запрашиваются три элемента данных) и десяти строк (по количеству служащих).
Вывести список имен, офисов и дат приема на работу всех служащих.
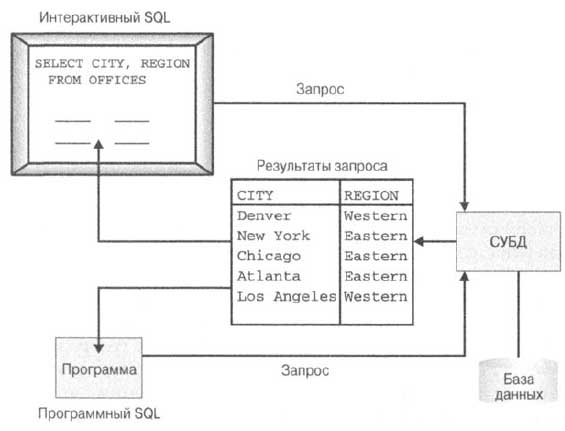
Рис. 2. Табличная структура результатов SQL-запроса
В отличие от запроса, показанного выше, следующий запрос возвращает только одну строку, так как есть всего один служащий, имеющий указанный идентификатор. Хотя результаты этого запроса, содержащие всего одну строку, имеют не такой «табличный» вид, как результаты, содержащие несколько строк, SQL все равно считает их таблицей, состоящей из трех столбцов и одной строки.
Имя, плановый и фактический объемы продаж служащего с идентификатором 107.
В некоторых случаях результатом запроса может быть единственное значение, как в следующем примере.
Среднее значение фактических объемов продаж по всем служащим компании.
Эти результаты запроса также являются таблицей, которая состоит из одного столбца и одной строки.
И наконец, запрос может вернуть результаты, содержащие нуль строк, как в следующем примере.
Список имен и дат приема на работу всех служащих, фактический объем продаж которых превышает $500 000.
Даже в таком случае результаты запроса считаются таблицей. Пустая таблица, приведенная выше, содержит два столбца и нуль строк.
Обратите внимание на то, что поддержка отсутствующих данных в SQL распространяется и на результаты запроса. Если один из элементов данных в таблице имеет значение , то оно попадет в результаты запроса при извлечении этого элемента
Например, в таблице значение содержится в столбцах и . Приведенный далее запрос возвращает эти значения во втором и третьем столбцах таблицы результатов запроса. Заметим, что не все SQL- продукты выводят значения таким образом — Oracle и DB2, например, встретив значение , не выводят ничего.
Список служащих с их плановыми объемами продаж и менеджерами.
To, что SQL-запрос всегда возвращает таблицу данных, очень важно. Это означает, что результаты запроса можно сохранить в базе данных в виде таблицы
Это означает также, что результаты двух подобных запросов можно объединить в одну таблицу. И наконец, это говорит о том, что результаты запроса сами могут стать предметом дальнейших запросов. Таким образом, табличная структура реляционной базы данных тесно связана с реляционными запросами SQL. Таблицам можно посылать запросы, а запросы возвращают таблицы.