Postgresql: the world’s most advanced open source relational database
Содержание:
- 42.2.11
- Оператор SELECT
- Additional Modules (contrib)
- Indexing & Constraints
- Performance
- Кому надо переходить на Postgres
- 2019
- Технические характеристики
- Импорт дампа базы данных PostgreSQL в pgAdmin 4
- 42.2.10
- 2017
- SQL
- Путь поиска
- Custom Functions, Stored Procedures, & Triggers
- Выявляем и оптимизируем ресурсоемкие запросы 1С:Предприятия
- Индексы в PostgreSQL
42.2.11
Notable changes
As mentioned above this version is broken and should not be used.
- Reverted PR 1641. The driver will now wait for EOF when sending cancel signals.
- returns only procedures (not functions) for PostgreSQL 11+ PR 1723
- Convert silent rollbacks into exception if application sends or command PR 1729
- feat: connection option to configure if silent rollback should raise an exception PR 1729
- feat: Expose in CopyManager PR 1702
- feat: add way to distinguish base and partitioned tables in PgDatabaseMetaData.getTables PR 1708
- refactor: introduce tuple abstraction (rebased) PR 1701
- refactor: make PSQLState enum consts for integrity constraint violations PR 1699
- test: add makefile to create ssl certs PR 1706
Fixed
- fix: Always use as decimal separator in PGInterval PR 1705
- fix: allow DatabaseMetaData.getColumns to describe an unset scale PR 1716
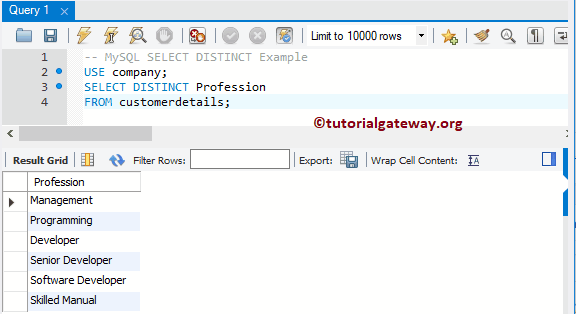
Оператор SELECT
Как упоминалось в начале статьи, SQL-запросы почти всегда начинаются с оператора SELECT. SELECT в запросах указывает, какие столбцы из таблицы должны нужно вернуть в наборе результатов. Запросы также почти всегда включают оператор FROM, который используется для указания таблицы, к которой нужно обратиться.
В общем SQL-запросы следуют такому синтаксису:
Например, чтобы извлечь столбец name из таблицы dinners, нужен такой запрос:
Вы также можете запрашивать несколько столбцов из одной таблицы, отделив их заголовки запятыми.
Вместо того чтобы называть конкретный столбец или набор столбцов, вы можете использовать оператор SELECT со звездочкой (*) – она служит заполнителем, представляющим все столбцы в таблице. Следующая команда отобразит все столбцы таблицы tourneys:
WHERE используется в запросах для фильтрации записей, которые удовлетворяют указанному условию. Все строки, которые не удовлетворяют этому условию, исключаются из результата. Оператор WHERE обычно использует следующий синтаксис:
Оператор сравнения в выражении WHERE определяет способ сравнения указанного столбца со значением. Вот некоторые распространенные операторы сравнения SQL:
| Оператор | Действие |
| = | Равно |
| != | Не равно |
| < | Меньше, чем |
| > | Больше, чем |
| <= | Меньше или равно |
| >= | Больше или равно |
| BETWEEN | проверяет, находится ли значение в заданном диапазоне |
| IN | проверяет, содержится ли значение строки в наборе указанных значений |
| EXISTS | проверяет, существуют ли строки при заданных условиях |
| LIKE | проверяет, соответствует ли значение указанной строке |
| IS NULL | Проверяет значения NULL |
| IS NOT NULL | Проверяет все значения, кроме NULL |
Например, если вы хотите узнать размер обуви Ирмы, вы можете использовать следующий запрос:
SQL позволяет использовать подстановочных знаков, и это особенно удобно при работе с выражениями WHERE. Знак процента (%) представляют ноль или более неизвестных символов, а подчеркивания (_) представляют один неизвестный символ. Они полезны, если вы пытаетесь найти конкретную запись в таблице, но не знаете точно, что это за запись. Чтобы проиллюстрировать это, предположим, что вы забыли любимое блюдо нескольких своих подруг, но вы уверены, что это блюдо начинается на t. Вы можете найти его название с помощью запроса:
Исходя из вышеприведенного вывода, это tofu.
Иногда приходится работать с базами данных, в которых есть столбцы или таблицы с относительно длинными или трудно читаемыми названиями. В этих случаях вы можете сделать эти имена более читабельными, создав псевдонимы – для этого есть ключевое слово AS. Псевдонимы, созданные с помощью AS, являются временными (они существуют только на время запроса, для которого они созданы):
Как видите, теперь SQL отображает столбец name как n, столбец birthdate как b и dessert как d.
На данный момент мы рассмотрели некоторые наиболее часто используемые ключевые слова и предложения в запросах SQL. Они полезны для базовых запросов, но они не помогут, если вам нужно выполнить вычисление или получить скалярное значение (одно значение, а не набор из нескольких различных значений) на основе ваших данных. Здесь вам понадобятся агрегатные функции.
Additional Modules (contrib)
| 13 | 12 | 11 | 10 | 9.6 | 9.5 | 9.4 | 9.3 | 9.2 | 9.1 | 9.0 | 8.4 | 8.3 | 8.2 | 8.1 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
|
contrib/adminpack |
Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | No |
|
contrib/auth_delay |
Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | No | No | No | No | No |
|
contrib/autoexplain |
Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | No | No | No |
|
contrib/btree_gin |
Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | No | No | No |
|
contrib/btree_gist |
Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes |
|
contrib/citext |
Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | No | No | No |
|
contrib/dblink |
Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes |
|
contrib/dblink asyncronous notification support |
Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | No | No | No | No |
|
contrib/dbsize |
Obsolete | Obsolete | Obsolete | Obsolete | Obsolete | Obsolete | Obsolete | Obsolete | Obsolete | Obsolete | Obsolete | Obsolete | Obsolete | Obsolete | Obsolete |
|
contrib/file_fdw |
Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | No | No | No | No | No |
|
contrib/fuzzystrmatch |
Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes |
|
contrib/hstore |
Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | No |
|
contrib/intarray |
Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes |
|
contrib/isn (ISBN) |
Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | No |
|
contrib/ltree |
Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes |
|
contrib/pageinspect |
Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | No | No |
|
contrib/passwordcheck |
Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | No | No | No | No |
|
contrib/pg_autovacuum |
Obsolete | Obsolete | Obsolete | Obsolete | Obsolete | Obsolete | Obsolete | Obsolete | Obsolete | Obsolete | Obsolete | Obsolete | Obsolete | Obsolete | Obsolete |
|
contrib/pgbench |
Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes |
|
contrib/pg_buffercache |
Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes |
|
contrib/pg_freespacemap |
Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | No |
|
contrib/pg_rewind |
Yes | Yes | Yes | Yes | Yes | Yes | No | No | No | No | No | No | No | No | No |
|
contrib/pg_standby |
Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | No | No |
|
contrib/pg_stat_statements |
Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | No | No | No |
|
contrib/pg_stat_statements improvements |
Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | No | No | No | No | No | No |
|
contrib/pgstattuple |
Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes |
|
contrib/pg_trgm |
Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes |
|
contrib/pg_trgm regular expressions indexing |
Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | No | No | No | No | No | No | No |
|
contrib/pg_upgrade |
Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | No | No | No | No |
|
contrib/pg_xlogdump |
Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | No | No | No | No | No | No | No |
|
contrib/seg |
Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes |
|
contrib/sepgsql |
Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | No | No | No | No | No |
|
contrib/sslinfo |
Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | No |
|
contrib/tablefunc |
Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes |
|
contrib/tcn |
Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | No | No | No | No | No | No |
|
contrib/tsearch2 |
Obsolete | Obsolete | Obsolete | Obsolete | Obsolete | Obsolete | Obsolete | Obsolete | Obsolete | Obsolete | Obsolete | Obsolete | Obsolete | Yes | Yes |
|
contrib/tsearch2 compat wrapper |
Obsolete | Obsolete | Obsolete | Obsolete | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | No | No |
|
contrib/tsearch2 UTF8 support |
Obsolete | Obsolete | Obsolete | Obsolete | Obsolete | Obsolete | Obsolete | Obsolete | Obsolete | Obsolete | Obsolete | Obsolete | Obsolete | Yes | No |
|
contrib/unaccent |
Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | No | No | No | No |
|
contrib/userlocks |
Obsolete | Obsolete | Obsolete | Obsolete | Obsolete | Obsolete | Obsolete | Obsolete | Obsolete | Obsolete | Obsolete | Obsolete | Obsolete | Obsolete | Yes |
|
contrib/uuid-ossp |
Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | No | No |
|
contrib/xml2 |
Obsolete | Obsolete | Obsolete | Obsolete | Obsolete | Obsolete | Obsolete | Obsolete | Obsolete | Obsolete | Obsolete | Obsolete | Yes | Yes | Yes |
|
KNN support for CUBE |
Yes | Yes | Yes | Yes | Yes | No | No | No | No | No | No | No | No | No | No |
Indexing & Constraints
| 13 | 12 | 11 | 10 | 9.6 | 9.5 | 9.4 | 9.3 | 9.2 | 9.1 | 9.0 | 8.4 | 8.3 | 8.2 | 8.1 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
|
Block-range (BRIN) indexes |
Yes | Yes | Yes | Yes | Yes | Yes | No | No | No | No | No | No | No | No | No |
| Yes | No | No | No | No | No | No | No | No | No | No | No | No | No | No | |
|
Concurrent GiST indexes |
Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes |
|
Covering Indexes for B-trees (INCLUDE) |
Yes | Yes | Yes | No | No | No | No | No | No | No | No | No | No | No | No |
|
Covering indexes for GiST (INCLUDE) |
Yes | Yes | No | No | No | No | No | No | No | No | No | No | No | No | No |
|
Deferrable unique constraints |
Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | No | No | No | No |
|
Exclusion constraints |
Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | No | No | No | No |
|
GIN (Generalized Inverted Index) Indexes |
Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | No |
| Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | No | No | No | |
|
GIN Index performance and size improvements |
Yes | Yes | Yes | Yes | Yes | Yes | Yes | No | No | No | No | No | No | No | No |
|
GiST (Generalized Search Tree) Indexes |
Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes |
|
Indexes on expressions |
Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes |
|
Index-only scans |
Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | No | No | No | No | No | No |
|
Index-only scans on GiST |
Yes | Yes | Yes | Yes | Yes | Yes | No | No | No | No | No | No | No | No | No |
|
Index support for IS NULL |
Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | No | No |
|
In-memory Bitmap Indexes |
Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes |
|
K-nearest neighbor SP-GiST Support |
Yes | Yes | No | No | No | No | No | No | No | No | No | No | No | No | No |
|
Non-blocking CREATE INDEX |
Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | No |
|
Parallel B-tree index scans |
Yes | Yes | Yes | Yes | No | No | No | No | No | No | No | No | No | No | No |
|
Parallelized CREATE INDEX for B-tree indexes |
Yes | Yes | Yes | No | No | No | No | No | No | No | No | No | No | No | No |
|
Space-Partitioned GiST (SP-GiST) Indexes |
Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | No | No | No | No | No | No |
|
SP-GiST indexes for range types |
Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | No | No | No | No | No | No | No |
|
WAL support for hash indexes |
Yes | Yes | Yes | Yes | No | No | No | No | No | No | No | No | No | No | No |
Performance
| 13 | 12 | 11 | 10 | 9.6 | 9.5 | 9.4 | 9.3 | 9.2 | 9.1 | 9.0 | 8.4 | 8.3 | 8.2 | 8.1 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
|
Abbreviated Keys |
Yes | Yes | Yes | Yes | Yes | Yes | No | No | No | No | No | No | No | No | No |
|
Accelerated partition pruning |
Yes | Yes | No | No | No | No | No | No | No | No | No | No | No | No | No |
|
Asynchronous Commit |
Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | No | No |
|
Automatic plan invalidation |
Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | No | No |
|
Background Checkpointer |
Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | No | No | No | No | No | No |
|
Background Writer |
Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes |
|
Base backup throttling |
Yes | Yes | Yes | Yes | Yes | Yes | Yes | No | No | No | No | No | No | No | No |
|
CREATE STATISTICS — most-common values (MCV) statistics |
Yes | Yes | No | No | No | No | No | No | No | No | No | No | No | No | No |
|
CREATE STATISTICS — multicolumn |
Yes | Yes | Yes | Yes | No | No | No | No | No | No | No | No | No | No | No |
|
CREATE STATISTICS — «OR» and «IN/ANY» statistics |
Yes | No | No | No | No | No | No | No | No | No | No | No | No | No | No |
|
Cross datatype hashing support |
Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | No | No |
|
Distributed checkpointing |
Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | No | No |
|
Foreign keys marked as NOT VALID |
Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | No | No | No | No | No |
|
Frozen page map |
Yes | Yes | Yes | Yes | Yes | No | No | No | No | No | No | No | No | No | No |
|
Full Text Search |
Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | No | No |
|
Hash aggregation can use disk |
Yes | No | No | No | No | No | No | No | No | No | No | No | No | No | No |
|
Hashing support for DISTINCT/UNION/INTERSECT/EXCEPT |
Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | No | No | No |
|
Hashing support for FULL OUTER JOIN, LEFT OUTER JOIN and RIGHT OUTER JOIN |
Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | No | No | No | No | No |
|
Heap Only Tuples (HOT) |
Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | No | No |
| Yes | No | No | No | No | No | No | No | No | No | No | No | No | No | No | |
|
Inlined WITH Queries (Common Table Expressions) |
Yes | Yes | No | No | No | No | No | No | No | No | No | No | No | No | No |
|
Inlining of SQL-functions |
Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes |
|
Just-in-Time (JIT) compilation for expression evaluation and tuple deforming |
Yes | Yes | Yes | No | No | No | No | No | No | No | No | No | No | No | No |
|
K-nearest neighbor GiST support |
Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | No | No | No | No | No |
|
Multi-core scalability for read-only workloads |
Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | No | No | No | No | No | No |
|
Multiple temporary tablespaces |
Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | No | No |
|
Outer Join reordering |
Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | No |
|
Parallel bitmap heap scans |
Yes | Yes | Yes | Yes | No | No | No | No | No | No | No | No | No | No | No |
| Yes | Yes | Yes | Yes | Yes | No | No | No | No | No | No | No | No | No | No | |
| Yes | Yes | Yes | No | No | No | No | No | No | No | No | No | No | No | No | |
|
Parallel JOIN, aggregate |
Yes | Yes | Yes | Yes | Yes | No | No | No | No | No | No | No | No | No | No |
|
Parallel merge joins |
Yes | Yes | Yes | Yes | No | No | No | No | No | No | No | No | No | No | No |
|
Parallel query |
Yes | Yes | Yes | Yes | Yes | No | No | No | No | No | No | No | No | No | No |
|
Parallel restore |
Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | No | No | No |
|
Partial sort capability (top-n sorting) |
Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | No | No |
|
Partition pruning during query execution |
Yes | Yes | Yes | No | No | No | No | No | No | No | No | No | No | No | No |
|
pg_prewarm |
Yes | Yes | Yes | Yes | Yes | Yes | Yes | No | No | No | No | No | No | No | No |
|
Reduced lock levels for ALTER TABLE commands |
Yes | Yes | Yes | Yes | Yes | Yes | Yes | No | No | No | No | No | No | No | No |
|
SELECT … FOR UPDATE/SHARE NOWAIT |
Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes |
|
Set costs specific to TABLESPACEs |
Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | No | No | No | No |
|
Shared row level locking |
Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes |
|
SKIP LOCKED clause |
Yes | Yes | Yes | Yes | Yes | Yes | No | No | No | No | No | No | No | No | No |
|
Synchronized sequential scanning |
Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | No | No |
|
TABLESAMPLE clause |
Yes | Yes | Yes | Yes | Yes | Yes | No | No | No | No | No | No | No | No | No |
|
Tablespaces |
Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes |
|
Unlogged tables |
Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | No | No | No | No | No |
|
WAL Buffer auto-tuning |
Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | No | No | No | No | No |
Кому надо переходить на Postgres
И теперь, наверное, самое важное: кому точно надо переходить на Postgres?
-
Если у вас проходит новая инсталляция продуктовой системы. Если вы ставите новую систему, я бы рекомендовал перейти хотя бы на бесплатный Postgres. Рекомендую сразу это делать на Linux. Можно и на Windows, но тут проблема не столько в том, что Postgres плохой или Windows плохой – плохо работает их связка в части файловой системы. Опять же из-за наших структур баз данных, где у нас по 30 тыс. элементов в одной таблице (7 тыс. таблиц, 25 тыс. индексов). С таким количеством файлов винда работает плохо, а Postgres хранит каждый элемент системы в отдельном файле – более того, он эти файлы разбивает по 1 Гб, для каждого файла есть отдельные служебные файлы. И так на одну базу может получиться 100-300 тысяч файлов. Когда заходишь в папку, а там 300 тыс. файлов, можете оценить скорость этой работы. Linux же с этим работает прекрасно. Поэтому, если у вас новая инсталляция продукта, надо пробовать Postgres на Linux.
-
Разработчикам 1С. В идеале, на всех ваших ноутбуках и рабочих ПК должен стоять бесплатный Postgres. И вы в идеале должны разворачивать себе клиент-серверную систему 1С. Да, возникнут вопросы, что серверные ключи для 1С дорогие. Ну купите мини-сервер на пять пользователей за 15 тыс. рублей. Почему надо? Очень часто сталкиваемся с тем, что разрабатываете вы для клиент-серверной системы. а разработка идет в файловой системе. А потом начинается… Так что разрабатывать надо на такой же системе, в которой планируете работать.
-
Если вы делаете переход с файловой. До этого мы обсуждали, что переходить на бесплатный Express бессмысленно, поскольку у вас база не влезет. Если вы разрабатываете базу с объемом в 100 Гб, и вам нужны данные для разработки, то переход на Express бессмысленен. На Postgres переходите и работаете – в том числе и на бесплатный.
-
Если вы работаете под Минкомсвязью, вам нужно брать ПО только из реестра Минкомсвязи – вам переход на PostgreSQL, причем только платный Postgres Pro. Других вариантов нет.
-
Причина, по которой в свое время моя команда перешла на Postgres – потому что я был смелый и любознательный патриот. Мы решили попробовать, реально ли наши умеют писать СУБД. Оказалось, умеют и круто. Более того, работать с техподдержкой Postgres Pro – одно удовольствие. Все люди говорят на русском, работают круглосуточно, подключаются быстро. Я такой техподдержки до сих пор ни у кого не видел. Кто хоть раз писал на v8@1c.ru знают, какой может быть техподдержка на русском языке. А это прямо небо и земля.
Но обычно у тех, кому надо переходить на PostgreSQL, у тех и не особо болит после перехода. А кому на Postgres не надо, но они переходят – те потом начинают говорить, что ничего не работает. Ну да, если ты не готов, то, наверное, и не работает.
2019
Включение в продукты DeviceLock
22 октября 2019 года стало известно, что DeviceLock включил в свои продукты поддержку Postgres Pro и PostgreSQL. Подробнее .
Запуск программы сертификации специалистов по СУБД PostgreSQL
21 мая 2019 года Postgres Professional сообщил о запуске программы сертификации специалистов по СУБД PostgreSQL.

Программа сертификации предусматривает три уровня с возрастающей квалификацией:
- «Профессионал»
- «Эксперт»
- «Мастер»
Для получения сертификата необходимо пройти тестирование в офисе компании Postgres Professional и набрать проходной балл. Материалом для подготовки могут служить авторские курсы Postgres Professional, доступные на сайте, а также регулярно читаемые в сертифицированных учебных центрах. Ежегодно слушателями курсов становятся более 500 человек.
Тест для первого уровня — «Профессионал» — включает в себя 50 вопросов по основам администрирования PostgreSQL и длится 75 минут. Поскольку для каждого релиза PostgreSQL характерны свои особенности администрирования, сертификация соотносится с конкретной версией СУБД. Например, на май 2019 года доступен тест для 10-ой версии PostgreSQL DBA1-10. Для прошедших тестирование на знание PostgreSQL 10 и желающих в будущем подтвердить свои навыки для 11-ой версии достаточно будет пройти короткое дополнительное тестирование, сфокусированное на отличиях продуктов.
Для получения сертификата уровня «Эксперт» понадобится успешно пройти уже три теста:
- DBA2-10 (настройка и мониторинг PostgreSQL)
- DBA3-10 (резервное копирование и репликация PostgreSQL)
- QPT-10 (оптимизация запросов)
А переход на уровень «Мастер» предполагает выполнение практических заданий по работе с PostgreSQL. В дальнейших планах компании Postgres Professional – запуск программы сертификации для разработчиков приложений на PostgreSQL.
Иван Панченко прокомментировал запуск программы сертификации:
|
Специалисты по Postgres становятся все более востребованными на российском рынке, что подтверждают данные кадровых агентств. В такой ситуации необходимы единые стандарты и критерии для оценки уровня знаний. Во многом наша программа сертификации стала ответом на запросы заказчиков и партнеров, заинтересованных в независимом инструменте оценки и повышения квалификации своих сотрудников. Иван Панченко, заместитель генерального директора Postgres Professional |
Совместимость с Live Universal Interface
15 апреля 2019 года компания ФОРС Телеком сообщила о появлении в экосистеме программно-инструментальных средств, совместимых с открытой платформой Postgres Pro/PostgreSQL конструктора пользовательских веб-интерфейсов к базам данных — Live Universal Interface (LUI). Подробнее здесь.
Совместимость с TerraLink xDE
12 марта 2019 года TerraLink сообщил, что TerraLink xDE поддерживает OC семейства Linux и СУБД PostgreSQL. Подробнее .
Технические характеристики
Доступны версии СУБД: PostgreSQL 11, 12, 13 и 11-TimescaleDB, 12-TimescaleDB, 13-TimescaleDB.
Для создания кластера БД доступны фиксированные и произвольные конфигурации нод.
Фиксированные конфигурации с предзаданным количеством ресурсов:
- 2 vCPU, 4 ГБ RAM, 32 ГБ локального диска;
- 2 vCPU, 8 ГБ RAM, 64 ГБ локального диска;
- 4 vCPU, 16 ГБ RAM, 128 ГБ локального диска;
- 8 vCPU, 32 ГБ RAM, 256 ГБ локального диска;
- 16 vCPU, 64 ГБ RAM, 512 ГБ локального диска;
- 32 vCPU, 128 ГБ RAM, 1024 ГБ локального диска.
В произвольных конфигурациях можно выбрать количество ресурсов:
- vCPU — от 1 до 8 ядер;
- RAM — от 4 ГБ до 64 ГБ;
- локальный диск — от 15 ГБ до 512 ГБ.
Примечание: на локальном диске зарезервировано около 5 ГБ под операционную систему, компоненты сервиса и хранение логов. Остальной объем доступен для размещения баз данных.
Кластеры БД можно создавать только в приватных и публичных сетях:
- Приватная сеть — к кластеру БД можно подключиться только из выбранной приватной сети;
- Публичная сеть — к кластеру БД можно подключиться из интернета.
Импорт дампа базы данных PostgreSQL в pgAdmin 4
Дамп готов, теперь можно переходить к восстановлению базы данных из этого дампа. Однако перед тем как приступать к импорту, необходимо создать пустую базу данных, в которую собственно и импортировать все данные, как это делается, я подробно рассказывал в отдельном материале.
Все действия по созданию базы данных и восстановлению данных этой базы из архивной копии мы будем делать все на том же компьютере с помощью того же pgAdmin 4, только для этого необходимо подключиться к нужному нам серверу (пункт контекстного меню «Создать сервер» и ввести настройки для подключения, подробнее, как это делается, я рассказывал в той же статье, которая посвящена установке PostgreSQL на Debian).
Импорт сжатого дампа базы данных
Чтобы импортировать базу данных, дамп который был создан в «специальном» формате, необходимо на целевом сервере выбрать базу данных, которую требуется восстановить из дампа (мы ее предварительно создали), в контекстном меню выбрать пункт «Восстановить», затем в пункте «Имя файла», используя кнопку с тремя точками, указать файл дампа, который мы создали чуть ранее с расширением backup.
Больше никаких настроек вводить не требуется, нужный формат выбран по умолчанию, мы можем сразу нажимать кнопку «Восстановить».

Когда появится сообщение «Успешно завершено», процесс будет завершен.
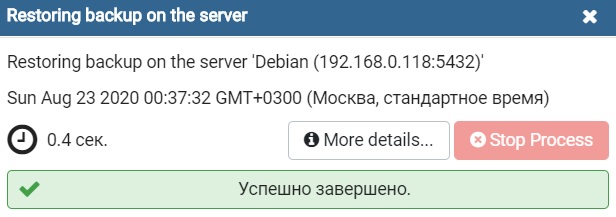
В результате все данные будут восстановлены из дампа, и таким образом мы перенесли базу данных PostgreSQL на новый сервер.
Импорт дампа базы данных в формате SQL
В случае с простым форматом, т.е. с обычными SQL инструкциями, использовать отдельный функционал для восстановления не получится, поэтому мы можем просто выполнить SQL скрипт, который содержится в этом файле.
Для этого открываем Query Tool (запросник) в контексте нужной нам базы данных, затем используя кнопку «Открыть файл» выбираем наш дамп в формате SQL и нажимаем кнопку «Выполнить».
Если инструкция выполнится без ошибок, значит, все хорошо.

В итоге мы перенесли базу данных PostgreSQL с одного сервера, который управляется операционной системой Windows, на другой, который управляется Linux, хотя это, как Вы понимаете, в нашем случае было не так принципиально.
Стоит отметить, что если требуется перенести базу данных, размер которой достаточно большой, например, несколько десятков или сотен гигабайт, то лучше напрямую использовать консольные утилиты pg_dump или pg_dumpall, т.е. без графического интерфейса pgAdmin 4.
42.2.10
Changed
(!) Regression: remove receiving EOF from backend after cancel PR 1641. The regression is that the subsequent query might receive the cancel signal.
Fixed
- Cleanup PGProperty, sort values, and add some missing to docs PR 1686
- Fixing LocalTime rounding (losing precision) PR 1570
- Network Performance of PgDatabaseMetaData.getTypeInfo() method PR 1668
- Issue #1680 updating a boolean field requires special handling to set it to t or f instead of true or false PR 1682
- bug in pgstream for replication PR 1681
- Issue #1677 NumberFormatException when fetching PGInterval with small value PR 1678
- Metadata queries improvements with large schemas. PR 1673
- Utf 8 encoding optimizations PR 1444
- interval overflow PR 1658
- Issue #1482 where the port was being added to the GSSAPI service name PR 1651
- remove receiving EOF from backend after cancel since according to protocol the server closes the connection once cancel is sent (connection reset exception is always thrown) PR 1641
- Unable to register out parameter Issue #1646 PR 1648
2017
Документация версии 10 локализована для России
11 октября 2017 года компания Postgres Professional сообщила о переводе документации по PostgreSQL 10.0 на русский язык. Материалы доступны в форматах Html, epub и pdf. Общий объем текста составляет почти 2 600 страниц.
Помимо документации на русском языке, российским пользователям PostgreSQL также доступна техническая поддержка в режиме 24/7, помощь в миграции с других СУБД на PostgreSQL, обучающие курсы и технические конференции.
В ближайшее время Postgres Professional планирует выпуск обновленной версии российской СУБД Postgres Pro Standard на основе PostgreSQL 10.0.
PostgreSQL 10
5 октября 2017 года состоялся релиз PostgreSQL версии 10. В целом с каждой версией, выходящей раз в год, PostrgeSQL получает возможности, расширяющие область эффективного применения СУБД.
Основные нововведения:
- Логическая репликация: отдельные части этого механизма были добавлены в PostgreSQL уже довольно давно, а в этой версии логическая репликация стала полностью доступна для пользователей. С ее помощью можно выборочно реплицировать отдельные таблицы на другой сервер, который при этом может выполнять как читающие, так и пишущие запросы. Серверы, участвующие в репликации, могут работать под управлением разных версий PostgreSQL, что позволяет проводить обновление кластера с минимальным временем простоя.
- Декларативное секционирование избавляет администратора от необходимости вручную определять иерархию таблиц, создавать триггеры и ограничения целостности.
- Параллельное выполнение запросов стало возможным для сканирования битовых карт и индексов, для соединения слиянием и подзапросов в дополнение к тем возможностям, которые появились в предыдущей версии.
- Синхронная репликация с учетом кворума позволяет фиксировать изменения, если их подтвердило необходимое число произвольных реплик.
- SCRAM-аутентификация является более криптостойким вариантом используемой ранее MD5-аутентификации.
Всего, по словам разработчиков, в версию 10 вошло более 100 изменений и улучшений, часть из которых выполнена в компании Postgres Professional.
Интеграция с Ethereum
14 сентября 2017 года российская компания Postgres Professional объявила о создании прототипа расширения Posthereum для интеграции полнофункциональной СУБД PostgreSQL с блокчейн-платформой Ethereum, предназначенной для регистрации сделок с любыми видами активов на основе системы «умных контрактов». По замыслу компании, крупные российские банки, корпорации и госструктуры, работающие с СУБД PostgreSQL, с помощью данной разработки смогут объединить базы данных с блокчейн-приложениями на основе Ethereum. Подробнее здесь.
SQL
| 13 | 12 | 11 | 10 | 9.6 | 9.5 | 9.4 | 9.3 | 9.2 | 9.1 | 9.0 | 8.4 | 8.3 | 8.2 | 8.1 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Yes | No | No | No | No | No | No | No | No | No | No | No | No | No | No | |
| Yes | Yes | Yes | Yes | Yes | Yes | No | No | No | No | No | No | No | No | No | |
|
INSERT/UPDATE/DELETE RETURNING |
Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | No |
|
LATERAL clause |
Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | No | No | No | No | No | No | No |
|
Multirow VALUES |
Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | No |
|
ORDER BY NULLS FIRST/LAST |
Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | No | No |
|
Recursive Queries |
Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | No | No | No |
|
Row-wise comparison |
Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | No |
|
SELECT FOR NO KEY UPDATE/SELECT FOR KEY SHARE lock modes |
Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | No | No | No | No | No | No | No |
| Yes | Yes | No | No | No | No | No | No | No | No | No | No | No | No | No | |
|
SQL standard interval handling |
Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | No | No | No |
|
TABLE statement |
Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | No | No | No |
|
Upsert (INSERT … ON CONFLICT DO …) |
Yes | Yes | Yes | Yes | Yes | Yes | No | No | No | No | No | No | No | No | No |
|
Window functions |
Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | No | No | No |
| Yes | Yes | Yes | Yes | Yes | Yes | Yes | No | No | No | No | No | No | No | No | |
| Yes | Yes | Yes | Yes | Yes | Yes | Yes | No | No | No | No | No | No | No | No | |
|
WITH Queries (Common Table Expressions) |
Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | No | No | No |
|
Writable WITH Queries (Common Table Expressions) |
Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | No | No | No | No | No |
Путь поиска
Так называемое “Квалифицированное имя” состоит из явно указанной схемы и имени объекта (как абсолютный путь в файловой системе). Например: <схема.имя>.
Если мы не указываем схему, то нужно понять, в какой схеме искать или создавать объект. Определяют схему с помощью пути поиска, который задается параметром search_path.
В параметре search_path можно через запятую перечислить схемы, в которых нужно искать объект, если мы не указываем схему явно. search_path это что-то вроде переменной окружения PATH в Linux, для поиска команд.
Из search_path исключаются:
- несуществующие схемы;
- схемы к которым нет доступа.
А некоторые схемы всегда добавляются в search_path, даже если мы их туда не запишем. Например pg_catalog.
Реальное значение search_path показывает функция current_schemas().
postgres@postgres=# SELECT current_schemas(true);
current_schemas
---------------------
{pg_catalog,public}
(1 row)
Time: 1,945 ms
При создании нового объекта, он будет помещаться в первую указанную в search_path схему. Если посмотреть пример выше, то так как у нас нет права писать в схему pg_catalog, объекты будут создаваться в public.
Custom Functions, Stored Procedures, & Triggers
| 13 | 12 | 11 | 10 | 9.6 | 9.5 | 9.4 | 9.3 | 9.2 | 9.1 | 9.0 | 8.4 | 8.3 | 8.2 | 8.1 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
|
ALTER TABLE ENABLE/DISABLE TRIGGER |
Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes |
|
ALTER TABLE / ENABLE REPLICA TRIGGER/RULE |
Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | No | No |
|
CALL syntax for executing procedures |
Yes | Yes | Yes | No | No | No | No | No | No | No | No | No | No | No | No |
|
Column level triggers |
Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | No | No | No | No |
|
CREATE PROCEDURE syntax for SQL stored procedures |
Yes | Yes | Yes | No | No | No | No | No | No | No | No | No | No | No | No |
|
Event triggers |
Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | No | No | No | No | No | No | No |
|
FILTER clause for aggregate functions |
Yes | Yes | Yes | Yes | Yes | Yes | Yes | No | No | No | No | No | No | No | No |
|
ORDER BY support within aggregates |
Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | No | No | No | No |
|
Per function GUC settings |
Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | No | No |
|
Per function statistics |
Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | No | No | No |
|
RETURN QUERY EXECUTE |
Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | No | No | No |
|
RETURNS TABLE |
Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | No | No | No |
|
Statement level triggers |
Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes |
|
Statement level TRUNCATE triggers |
Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | No | No | No |
|
Triggers on views |
Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | No | No | No | No | No |
|
Variadic functions |
Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | No | No | No |
|
WHEN clause for CREATE TRIGGER |
Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes | No | No | No | No |
Выявляем и оптимизируем ресурсоемкие запросы 1С:Предприятия
Обычно предметом оптимизации являются заранее определенные ключевые операции, т.е. действия, время выполнения которых значимо для пользователей. Причиной недостаточно быстрого выполнения ключевых операций может быть неоптимальный код, неоптимальные запросы либо же проблемы параллельности. Если выясняется, что основная доля времени выполнения ключевой операции приходится на запросы, то осуществляется оптимизация этих запросов.
При высоких нагрузках на сервер СУБД в оптимизации нуждаются и те запросы, которые потребляют наибольшие ресурсы. Такие запросы не обязательно связаны с ключевыми операциями и заранее неизвестны. Но их также легко выявить и определить контекст их выполнения, чтобы оптимизировать стандартными методами.
Индексы в PostgreSQL
В базах данных, таких как PostgreSQL, индекс формируется из значений одного или нескольких столбцов таблицы и указателей на строки этой таблицы.
Рассмотрим запрос:
Здесь выражение означает, что значение в колонке удовлетворяет некоторому условию (предикату) .
В отсутствии индекса для колонки , PostgreSQL для выполнения этого запроса был бы вынужден просмотреть таблицу целиком, вычисляя для каждой строки значение предиката и, если значение истинно, добавлял бы строку к результатам запроса.
Имея индекс для колонки , PostgreSQL может быстро, не просматривая таблицу целиком, получить из индекса указатели на строки таблицы, которые удовлетворяют условию , и затем уже по этим указателям прочитать данные из таблицы и сформировать результат. Это аналогично тому, как мы, вместо того чтобы просматривать всю книгу целиком, смотрим только ее оглавление, читаем номера страниц, соответствующие интересующим нам главам, а затем переходим на эти страницы.
Предикат может вычисляться от значения нескольких колонок. В этом случае для ускорения запроса используется индекс, построенный не для одной колонки, а для нескольких. Такие индексы называют составными.
Если мы хотим ускорить выполнение запроса, условие которого вычисляется по одной или нескольким колонкам, в PostgreSQL нам необходимо создать для этих колонок индекс с помощью команды :
Эта команда имеет большой перечень дополнительных параметров, с полным списком которых можно ознакомиться в документации.
Например, индекс может поддерживать ограничение на уникальность и не допускать появления в таблице нескольких строк, значения индексируемых столбцов у которых совпадают. Для этого при создании индекса указывают ключевое слово :
Или мы можем создать индекс не по полю таблицы, а по функции или скалярному выражению с одной или несколькими колонками таблицы (такие индексы называют функциональными или индексами по выражению). Это позволяет быстро находить данные в таблице по результатам вычислений. Например, мы хотим ускорит запрос регистронезависимого поиска по текстовому полю:
Если мы создадим обычный индекс по полю , он нам никак не поможет, т. к. PostgreSQL проиндексирует те значения, которые хранятся в этом поле в исходном виде (необязательно в нижнем регистре), а мы хотим искать по значениям этого поля, приведенные к нижнему регистру вызовом функции . Однако мы можем создать индекс по результатам вычисления выражения :
И такой индекс уже может успешно применяться для ускорения нашего запроса.
В зависимости от типа индексируемых данных, для индексирования применяются разные подходы. По умолчанию при создании индекса используется индекс на основе B-дерева. Но PostgreSQL поддерживает разные типы индексов для очень широкого круга задач, и при необходимости мы можем указать другой тип индекса, отличный от B-tree. Для этого перед списком индексируемых полей необходимо указать директиву . Например, для использования индекса типа GiST: