Шпаргалка по linux grep, домашний термостат на raspberry pi, эл. книга «ansible for devops» и postgresql на linux
Содержание:
- Difference between find and grep
- ПРИМЕРЫ ИСПОЛЬЗОВАНИЯ
- Grep OR Operator
- Команды для управления сетью
- Опции
- 11. Параметры для использования с командой Tree в Linux
- Регулярные выражения Linux
- Character classes and bracket expressions
- Other options
- Technical description
- Checking for full words, not for sub-strings using grep -w
- grep -E
- 1. Что такое команда GREP
- File and directory selection
- Разница между grep, egrep, fgrep, pgrep, zgrep
- msggrep, mboxgrep
- grep примеры использования
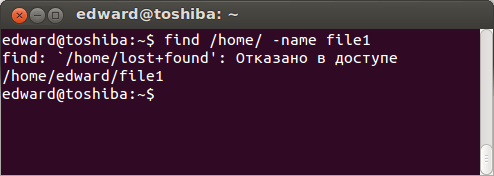
Difference between find and grep
For those just starting out on the Linux command line, it’s important to remember that find and grep are two commands with two very different functions, even though we use both to “find” something that the user specifies.
It’s handy to use grep to find a file when you use it to search through the output of the ls command as we showed in the first examples of the tutorial.
However, if you need to search recursively for the name of a file – or part of the file name if you use a wildcard (asterisk) – you’re much ahead to use the ‘find’ command.
$ find /path/to/search -name name-of-file
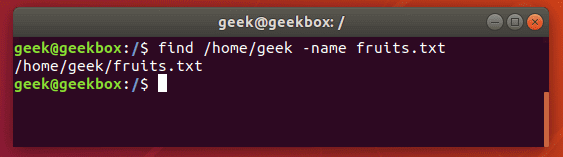
The output above shows that the find command was able to successfully locate the file we searched for.
ПРИМЕРЫ ИСПОЛЬЗОВАНИЯ
С теорией покончено, теперь перейдем к практике. Рассмотрим несколько основных примеров поиска внутри файлов Linux с помощью grep, которые могут вам понадобиться в повседневной жизни.
ПОИСК ТЕКСТА В ФАЙЛАХ
В первом примере мы будем искать пользователя User в файле паролей Linux. Чтобы выполнить поиск текста grep в файле /etc/passwd введите следующую команду:
В результате вы получите что-то вроде этого, если, конечно, существует такой пользователь:
А теперь не будем учитывать регистр во время поиска. Тогда комбинации ABC, abc и Abc с точки зрения программы будут одинаковы:
ВЫВЕСТИ НЕСКОЛЬКО СТРОК
Например, мы хотим выбрать все ошибки из лог файла, но знаем что в следующей сточке после ошибки может содержаться полезная информация, тогда с помощью grep отобразим несколько строк, ошибки будем искать в Xorg.log по шаблону «EE»:
Выведет строку с вхождением и 4 строчки после нее.
Выведет целевую строку и 4 строчки до нее
Выведет по две строки с верху и снизу от вхождения.
РЕГУЛЯРНЫЕ ВЫРАЖЕНИЯ В GREP
Регулярные выражения grep — очень мощный инструмент в разы расширяющий возможности поиска текста в файлах grep. Для активации этого режима используйте опцию -e. Рассмотрим несколько примеров:
Поиск вхождения в начале строки с помощью спецсимвола «^», например, выведем все сообщения за ноябрь:
Поиск в конце строки, спецсимвол «$»:
Найдем все строки которые содержат цифры:
Вообще, регулярные выражения grep это очень обширная тема, в этой статье я лишь показал несколько примеров, чтобы дать вам понять что это. Как вы увидели, таким образом, поиск текста в файлах grep становиться еще гибче. Но на полное объяснение этой темы нужна целая статья, поэтому пока пропустим их и пойдем дальше.
РЕКУРСИВНОЕ ИСПОЛЬЗОВАНИЕ GREP
Если вам нужно провести поиск текста grep в нескольких файлах, размещенных в одном каталоге или подкаталогах, например, в файлах конфигурации Apache — /etc/apache2/ — используйте рекурсивный поиск. Для включения рекурсивного поиска в grep есть опция -r. Следующая команда займется поиском текста в файлах Linux во всех подкаталогах /etc/apache2 на предмет вхождения строки mydomain.com:
В выводе вы получите:
Здесь перед найденной строкой указано имя файла в котором она была найдена. Вывод имени файла легко отключить с помощью опции -h:
ПОИСК СЛОВ В GREP
Когда вы ищете строку abc, grep будет выводить также kbabc, abc123, aafrabc32 и тому подобные комбинации. Вы можете заставить grep искать по содержимому файлов в linux только те строки, которые выключают искомые слова с помощью опции -w:
ПОИСК ДВУХ СЛОВ
Можно искать по содержимому файла не одно слово, а целых несколько. Чтобы искать два разных слова используйте команду egrep:
КОЛИЧЕСТВО ВХОЖДЕНИЙ СТРОКИ
Утилита Grep может сообщить сколько раз определенная строка была найдена в каждом файле. Для этого используется опция -c (счетчик):
C помощью опции -n можно выводить номер строки в которой найдено вхождение, например:
Получим:
ИНВЕРТИРОВАННЫЙ ПОИСК В GREP
Команда grep linux может быть использована для поиска строк в файле Linux которые не содержат указанное слово. Например, вывести только те строки, которые не содержат слово пар:
ВЫВОД ИМЕНИ ФАЙЛА
Вы можете указать grep выводить только имя файла в котом было найдено заданное слово с помощью опции -l. Например, следующая команда выведет все имена файлов, при поиске по содержимому которых было обнаружено вхождение primary:
Grep OR Operator
Use any one of the following 4 methods for grep OR. I prefer method number 3 mentioned below for grep OR operator.
1. Grep OR Using \|
If you use the grep command without any option, you need to use \| to separate multiple patterns for the or condition.
grep 'pattern1\|pattern2' filename
For example, grep either Tech or Sales from the employee.txt file. Without the back slash in front of the pipe, the following will not work.
$ grep 'Tech\|Sales' employee.txt 100 Thomas Manager Sales $5,000 200 Jason Developer Technology $5,500 300 Raj Sysadmin Technology $7,000 500 Randy Manager Sales $6,000
2. Grep OR Using -E
grep -E option is for extended regexp. If you use the grep command with -E option, you just need to use | to separate multiple patterns for the or condition.
grep -E 'pattern1|pattern2' filename
For example, grep either Tech or Sales from the employee.txt file. Just use the | to separate multiple OR patterns.
$ grep -E 'Tech|Sales' employee.txt 100 Thomas Manager Sales $5,000 200 Jason Developer Technology $5,500 300 Raj Sysadmin Technology $7,000 500 Randy Manager Sales $6,000
3. Grep OR Using egrep
egrep is exactly same as ‘grep -E’. So, use egrep (without any option) and separate multiple patterns for the or condition.
egrep 'pattern1|pattern2' filename
For example, grep either Tech or Sales from the employee.txt file. Just use the | to separate multiple OR patterns.
$ egrep 'Tech|Sales' employee.txt 100 Thomas Manager Sales $5,000 200 Jason Developer Technology $5,500 300 Raj Sysadmin Technology $7,000 500 Randy Manager Sales $6,000
4. Grep OR Using grep -e
Using grep -e option you can pass only one parameter. Use multiple -e option in a single command to use multiple patterns for the or condition.
grep -e pattern1 -e pattern2 filename
For example, grep either Tech or Sales from the employee.txt file. Use multiple -e option with grep for the multiple OR patterns.
$ grep -e Tech -e Sales employee.txt 100 Thomas Manager Sales $5,000 200 Jason Developer Technology $5,500 300 Raj Sysadmin Technology $7,000 500 Randy Manager Sales $6,000
Команды для управления сетью
В стандартный функционал «Терминала» входит и просмотр данных по параметрам сети, скорости и качестве передачи данных.
- ip – команда для работы с сетью, благодаря наличию множества опций она многофункциональна. К примеру, добавив функцию address show, можно посмотреть информацию о сетевых адресах, а с route управлять маршрутизацией.
- ping – помогает определить качество подключения к сети или наличие его как такового.
- nethogs – выводит данные о количестве израсходованного трафика.
- traceroute – команда, аналогичная ping, но дополнительно дающая информацию о полном маршруте передачи пакетов, скорости доставки на каждом узле и так далее.
- mtr – мощная утилита для диагностики сети, совмещающая функционал команд ping и traceroute.
Опции
-0- Использует во входном потоке символ-разделитель NULL («\0») вместо «пробела» и «перевода строки», хорошо сочетается с опцией -print0 команды find
-l -Выполнять команду для каждой группы из заданного числа непустых строк аргументов, прочитанных со стандартного ввода. Последний вызов команды может быть с меньшим числом строк аргументов. Считается, что строка заканчивается первым встретившимся символом перевода строки, если только перед ним не стоит пробел или символ табуляции; пробел/табуляция в конце сигнализируют о том, что следующая непустая строка является продолжением данной. Если число опущено, оно считается равным 1. Опция -l включает опцию -x.
-I Режим вставки: команда выполняется для каждой строки стандартного ввода, причём вся строка рассматривается как один аргумент и подставляется в начальные_аргументы вместо каждого вхождения цепочки символов зам_цеп. Допускается не более 5 начальных_аргументов, содержащих одно или несколько вхождений зам_цеп. Пробелы и табуляции в начале вводимых строк отбрасываются. Сформированные аргументы не могут быть длиннее 255 символов. Если цепочка зам_цеп не задана, она полагается равной { }. Опция -I включает опцию -x.
-n Выполнить команду, используя максимально возможное количество аргументов, прочитанных со стандартного ввода, но не более заданного числа. Будет использовано меньше аргументов. Если их общая длина превышает размер (см. ниже опцию -s). Или если для последнего вызова их осталось меньше, чем заданное число. Если указана также опция -x, каждая группа из указанного числа аргументов должны укладываться в ограничение размера, иначе выполнение xargs прекращается.
-t Режим трассировки: команда и каждый построенный список аргументов перед выполнением выводится в стандартный поток ошибок.
-p Режим с приглашением: xargs перед каждым вызовом команды запрашивает подтверждение. Включается режим трассировки (-t), за счет чего печатается вызов команды, который должен быть выполнен, а за ним — приглашение ?…. Ответ y (за которым может идти что угодно) приводит к выполнению команды; при каком-либо другом ответе, включая возврат каретки, данный вызов команды игнорируется.
-x Завершить выполнение, если очередной список аргументов оказался длиннее, чем размер (в символах). Опция -x включается опциями -i и -l. Если ни одна из опций -i, -l или -n не указана, общая длина всех аргументов должна укладываться в ограничение размера.
-s Максимальный общий размер (в символах) каждого списка аргументов установить равным заданному размеру. Размер должен быть положительным числом, не превосходящим 470 (подразумеваемое значение). При выборе размера следует учитывать, что к каждому аргументу добавляется по одному символу; кроме того, запоминается число символов в имени команды.
-e Цепочка символов лконф_цеп считается признаком логического конца файла. Если опция -e не указана, признаком конца считается подчеркивание (_). Опция -e без лконф_цеп аннулирует возможность устанавливать логический конец файла (подчеркивание при этом рассматривается как обычный символ). Команда xargs читает стандартный ввод до тех пор, пока не дойдет до конца файла или не встретит цепочку лконф_цеп.
11. Параметры для использования с командой Tree в Linux
Параметры для использования с деревом
Далее Solvetic объяснит доступные параметры для использования с Tree:
-a: распечатать все файлы, помните, что по умолчанию дерево не печатает скрытые файлы.
-d: список только каталогов.
-l: продолжить символические ссылки, если они указывают на каталоги, притворяясь каталогами.
-f: вывести префикс полного пути к объектам.
-x: остается только в текущей файловой системе.
-L Level: позволяет определить максимальную глубину просмотра дерева каталогов в результате.
-R: Действовать рекурсивно, пересекая дерево в каталогах каждого уровня, и в каждом из них оно будет выполняться. дерево снова, добавив `-o 00Tree.html ‘.
-P шаблон: список только файлов, которые соответствуют шаблону подстановки.
-I шаблон: не перечислять файлы, которые соответствуют шаблону подстановки.
—matchdirs. Этот параметр указывает шаблон соответствия, который позволяет применять шаблон только к именам каталогов.
—prune: этот параметр удаляет пустые каталоги из выходных данных.
—noreport: пропускает печать файла и отчета каталога в конце списка выполненного дерева.
Общие параметры дерева
Это общие параметры, доступные для дерева, но у нас также есть эксклюзивные параметры для файлов, это:
-q: печатать непечатаемые символы в именах файлов.
-N: печать непечатных символов.
-Q: его функция заключается в назначении имен файлов в двойных кавычках.
-p: вывести тип файла и разрешения для каждого файла в каталоге.
-u: распечатать имя пользователя или UID файла.
-s: вывести размер каждого файла в байтах, а также его имя.
-g Распечатать имя группы или GID файла.
-h: его функция — распечатывать размер каждого файла разборчиво для пользователя.
—du: Он действует в каждом каталоге, генерируя отчет о его размере, включая размеры всех его файлов и подкаталогов.
—si: он использует степени 1000 (единицы СИ) для отображения размера файла.
-D: Распечатать дату последнего изменения файлов.
-F: Ваша задача — добавить `/ ‘для каталогов, a` =’ для файлов сокетов, a` * ‘для исполняемых файлов, `>’ для дверей (Solaris) и a` | ‘ для FIFO.
—inodes: вывести номер инода файла или каталога.
- —device: вывести номер устройства, к которому относится файл или каталог в результате.
- -v: Сортировать вывод по версии.
-U: не упорядочивает результаты.
-r: сортировать вывод в обратном порядке.
-t: сортировать результаты по времени последней модификации, а не по алфавиту.
-S: активировать линейную графику CP437
-n: отключает раскраску результата.
-C: активирует раскраску.
-X: активировать вывод XML.
-J: активировать вывод JSON.
-H baseHREF: активирует вывод HTML, включая ссылки HTTP.
—help: Помощь дерева доступа.
—version: показывает используемую версию команды Tree.
С помощью этих двух команд стало возможным гораздо более полное администрирование каждой задачи, выполняемой над файлами в Linux, дополняющей задачи поиска или управления этими файлами и доступа к интегральным результатам по мере необходимости.
Регулярные выражения Linux
В регулярных выражениях могут использоваться два типа символов:
- обычные буквы;
- метасимволы.
Обычные символы — это буквы, цифры и знаки препинания, из которых состоят любые строки. Все тексты состоят из букв и вы можете использовать их в регулярных выражениях для поиска нужной позиции в тексте.
Метасимволы — это кое-что другое, именно они дают силу регулярным выражениям. С помощью метасимволов вы можете сделать намного больше чем поиск одного символа. Вы можете искать комбинации символов, использовать динамическое их количество и выбирать диапазоны. Все спецсимволы можно разделить на два типа, это символы замены, которые заменяют собой обычные символы, или операторы, которые указывают сколько раз может повторяться символ. Синтаксис регулярного выражения будет выглядеть таким образом:
обычный_символ спецсимвол_оператор
спецсимвол_замены спецсимвол_оператор
Если оператор не указать, то будет считаться, что символ обязательно должен встретится в строке один раз. Таких конструкций может быть много. Вот основные метасимволы, которые используют регулярные выражения bash:
- \ — с обратной косой черты начинаются буквенные спецсимволы, а также он используется если нужно использовать спецсимвол в виде какого-либо знака препинания;
- ^ — указывает на начало строки;
- $ — указывает на конец строки;
- * — указывает, что предыдущий символ может повторяться 0 или больше раз;
- + — указывает, что предыдущий символ должен повторится больше один или больше раз;
- ? — предыдущий символ может встречаться ноль или один раз;
- {n} — указывает сколько раз (n) нужно повторить предыдущий символ;
- {N,n} — предыдущий символ может повторяться от N до n раз;
- . — любой символ кроме перевода строки;
- — любой символ, указанный в скобках;
- х|у — символ x или символ y;
- — любой символ, кроме тех, что указаны в скобках;
- — любой символ из указанного диапазона;
- — любой символ, которого нет в диапазоне;
- \b — обозначает границу слова с пробелом;
- \B — обозначает что символ должен быть внутри слова, например, ux совпадет с uxb или tuxedo, но не совпадет с Linux;
- \d — означает, что символ — цифра;
- \D — нецифровой символ;
- \n — символ перевода строки;
- \s — один из символов пробела, пробел, табуляция и так далее;
- \S — любой символ кроме пробела;
- \t — символ табуляции;
- \v — символ вертикальной табуляции;
- \w — любой буквенный символ, включая подчеркивание;
- \W — любой буквенный символ, кроме подчеркивания;
- \uXXX — символ Unicdoe.
Важно отметить, что перед буквенными спецсимволами нужно использовать косую черту, чтобы указать, что дальше идет спецсимвол. Правильно и обратное, если вы хотите использовать спецсимвол, который применяется без косой черты в качестве обычного символа, то вам придется добавить косую черту
Например, вы хотите найти в тексте строку 1+ 2=3. Если вы используете эту строку в качестве регулярного выражения, то ничего не найдете, потому что система интерпретирует плюс как спецсимвол, который сообщает, что предыдущая единица должна повториться один или больше раз. Поэтому его нужно экранировать: 1 \+ 2 = 3. Без экранирования наше регулярное выражение соответствовало бы только строке 11=3 или 111=3 и так далее. Перед равно черту ставить не нужно, потому что это не спецсимвол.
Character classes and bracket expressions
A bracket expression is a list of characters enclosed by and . It matches any single character in that list; if the first character of the list is the caret ^ then it matches any character not in the list. For example, the regular expression matches any single digit.
Within a bracket expression, a range expression consists of two characters separated by a hyphen. It matches any single character that sorts between the two characters, inclusive, using the locale’s collating sequence and character set. For example, in the default C locale, is equivalent to . Many locales sort characters in dictionary order, and in these locales is often not equivalent to ; it might be equivalent to , for example. To obtain the traditional interpretation of bracket expressions, you can use the C locale by setting the LC_ALL environment variable to the value C.
Finally, certain named classes of characters are predefined within bracket expressions, as follows. Their names are self explanatory, and they are , , , , , , , , , , and . For example, ] means the character class of numbers and letters in the current locale. In the C locale and ASCII character set encoding, this is the same as . (Note that the brackets in these class names are part of the symbolic names, and must be included in addition to the brackets delimiting the bracket expression.) Most metacharacters lose their special meaning inside bracket expressions. To include a literal place it first in the list. Similarly, to include a literal ^ place it anywhere but first. Finally, to include a literal —, place it last.
Other options
| —line-buffered | Use line buffering on output. This can cause a performance penalty. |
| —mmap | If possible, use the mmap system call to read input, instead of the default read system call. In some situations, —mmap yields better performance. However, —mmap can cause undefined behavior (including core dumps) if an input file shrinks while grep is operating, or if an I/O error occurs. |
| -U, —binary | Treat the file(s) as binary. By default, under MS-DOS and MS-Windows, grep guesses the file type by looking at the contents of the first 32 KB read from the file. If grep decides the file is a text file, it strips the CR characters from the original file contents (to make regular expressions with ^ and $ work correctly). Specifying -U overrules this guesswork, causing all files to be read and passed to the matching mechanism verbatim; if the file is a text file with CR/LF pairs at the end of each line, this causes some regular expressions to fail. This option has no effect on platforms other than MS-DOS and MS-Windows. |
| -z, —null-data | Treat the input as a set of lines, each terminated by a zero byte (the ASCII NUL character) instead of a newline. Like the -Z or —null option, this option can be used with commands like sort -z to process arbitrary file names. |
Technical description
grep searches the named input FILEs (or standard input if no files are named, or if a single dash («—«) is given as the file name) for lines containing a match to the given PATTERN. By default, grep prints the matching lines.
Also, three variant programs egrep, fgrep and rgrep are available:
- egrep is the same as running grep -E. In this mode, grep evaluates your PATTERN string as an extended regular expression (ERE). Nowadays, ERE does not «extend» very far beyond basic regular expressions, but they can still be very useful. For more information about extended regular expressions, see: , below.
- fgrep is the same as running grep -F. In this mode, grep evaluates your PATTERN string as a «fixed string» — every character in your string is treated literally. For example, if your string contains an asterisk («*«), grep will try to match it with an actual asterisk rather than interpreting this as a wildcard. If your string contains multiple lines (if it contains newlines), each line will be considered a fixed string, and any of them can trigger a match.
- rgrep is the same as running grep -r. In this mode, grep performs its search recursively. If it encounters a directory, it traverses into that directory and continue searching. (Symbolic links are ignored; if you want to search directories that are symbolically linked, use the -R option instead).
In older operating systems, egrep, fgrep and rgrep were distinct programs with their own executables. In modern systems, these special command names are shortcuts to grep with the appropriate flags enabled. They are functionally equivalent.
Checking for full words, not for sub-strings using grep -w
If you want to search for a word, and to avoid it to match the substrings use -w option. Just doing out a normal search will show out all the lines.
The following example is the regular grep where it is searching for «is». When you search for «is», without any option it will show out «is», «his», «this» and everything which has the substring «is».
$ grep -i "is" demo_file THIS LINE IS THE 1ST UPPER CASE LINE IN THIS FILE. this line is the 1st lower case line in this file. This Line Has All Its First Character Of The Word With Upper Case. Two lines above this line is empty. And this is the last line.
The following example is the WORD grep where it is searching only for the word «is». Please note that this output does not contain the line «This Line Has All Its First Character Of The Word With Upper Case», even though «is» is there in the «This», as the following is looking only for the word «is» and not for «this».
$ grep -iw "is" demo_file THIS LINE IS THE 1ST UPPER CASE LINE IN THIS FILE. this line is the 1st lower case line in this file. Two lines above this line is empty. And this is the last line.
grep -E
С некоторыми задачами обычный grep не справляется, поэтому нужен расширеный режим.
Найти в файле file
все foobar или foo bar с ровно одним пробелом
grep -E ‘foo\s?bar’ file
Найти в файле file
все foobar или foo bar с ровно двумя пробелами
grep -E ‘foo\s{2}bar’ file
Более сложный пример. Сотрудникам
TopBicycle
нужно понять у каких велосипедов в списке отсутствует или неправильно записан порядковый номер.
Номер должен быть в формате 111-11-1111 то есть три цифры дефис две цифры дефис четыре цифры
cat bikes.txt
Stels,Pilot,111-22-3333
Merida,BigNine,,
Stark,Cobra,xxx-xx-xxx
Forward,Tracer,1234-0
Author,Grand,444-55-6666
Stels,Pilot21,111-22-3344
Giant,Lannister,555-66-7777
Helkama,Jopo,,
grep -vE ‘\b{3}-{2}-{4}\b’ bikes.txt
Merida,BigNine,,
Stark,Cobra,xxx-xx-xxx
Forward,Tracer,1234-0
Helkama,Jopo,,
Правильные записи
grep -E ‘\b{3}-{2}-{4}\b’ bikes.txt
Stels,Pilot,111-22-3333
Author,Grand,444-55-6666
Stels,Pilot21,111-22-3344
Giant,Lannister,555-66-7777
1. Что такое команда GREP
Что такое команда Grep
Grep — это команда, разработанная для выполнения задач текстового поиска, Grep отвечает за поиск в файле, в котором мы указываем строки, в которых обнаруживается совпадение, либо со словами, либо со строкой, которую мы назначаем во время выполнения этого. Его название происходит от редактора UNIX g / re / p. Во время выполнения Grep будет возможно указать имя файла или можно оставить стандартный ввод, таким образом, Grep отвечает за генерацию совпадающих строк.
Grep переменные
В процессе Grep управляются три (3) переменные:
-G, —basic-regexp: отвечает за интерпретацию шаблона как основного регулярного выражения, это значение по умолчанию.
-E, —extended-regexp: эта опция проверяет шаблон как расширенное регулярное выражение.
-F, —fixed-strings: с этой опцией шаблон интерпретируется как список строк фиксированных символов, разделенных переносами строк, где в любом из них будет выполняться поиск соответствия.
Команда Grep (Global Regular Expression Print) — это команда, которая позволит нам анализировать в системе, чтобы найти совпадения, и после обнаружения приступить к печати результатов, чтобы можно было централизованно управлять этими результатами.
Grep синтаксис
Синтаксис использования команды Grep следующий:
grep (Опция) Шаблон (файл)
Параметры команды Grep
Есть ряд параметров, которые мы можем использовать с командой grep для получения наилучших результатов, это:
-E, —extended-regexp: шаблоны понимаются как регулярные выражения
-F, —fixed-strings: шаблоны являются строками
-G, —basic-regexp: шаблоны являются основными регулярными выражениями
-P, —perl-regexep: шаблоны являются выражениями Perl
-e, regexp = PATTERNS: поиск шаблонов совпадений
-f. –File (File): использует шаблоны в виде файла.
-i, —ignore-case: игнорировать прописные буквы
-w, —word-regexp: сопоставить все одинаковые слова
-x, —line-regexp: сопоставить все строки
-s, —no-messages: устранить сообщения об ошибках
-v, —invert-match: выбрать строки, которые не соответствуют критериям поиска
-V, —version: отображает версию используемого grep
-m, —max-count = NUM: останавливает поиск после определенного количества строк
-b, —byte-offset = Отображает смещение байта рядом с выходными строками
-n, —line-number: вывести количество строк
-H, —with-filename: отображать имя файла в выходных строках
-q, —quiet: Подавить все результаты
-d, —directories = Action: Указывает, как обрабатываются каталоги
-l, —files-without-match = выводить только имена файлов без учета строк
-c, —count: печать выбранных строк в файле
У меня нет команды Grep
Команда grep по умолчанию используется в худших дистрибутивах Linux, если по какой-то причине у вас ее нет, вы можете установить ее с помощью следующих команд:
sudo apt-get установить grep (Debian и Ubuntu) sudo yum установить grep (Redhat, CentOS и Fedora)
Шаг 1 Общий синтаксис, который может содержать несколько параметров, выглядит следующим образом:
grep num] pattern | -f файл] файлов ...
Шаг 2 Мы увидим несколько примеров использования Grep, прежде чем узнаем его параметры. Если мы хотим посмотреть в каталоге / etc / passwd все, что касается специального пользователя, мы можем выполнить следующее:
grep "пользователь" / etc / passwd
Шаг 3 Результат будет следующим:
Шаг 4 Также будет возможно заставить команду Grep игнорировать прописные и строчные буквы, то есть разрешить сопоставление Solventic, Solvetic или SOLVETIC вместе со всеми комбинациями, используя параметр -i:
grep -i "resoltic" / etc / passwd
Шаг 5 Эта опция также может быть выполнена с помощью команды cat следующим образом:
кошка / etc / passwd | grep -i "решитель"
File and directory selection
| -a, —text | Process a binary file as if it were text; this is equivalent to the —binary-files=text option. |
| —binary-files=TYPE | If the first few bytes of a file indicate that the file contains binary data, assume that the file is of type TYPE. By default, TYPE is binary, and grep normally outputs either a one-line message saying that a binary file matches, or no message if there is no match. If TYPE is without-match, grep assumes that a binary file does not match; this is equivalent to the -I option. If TYPE is text, grep processes a binary file as if it were text; this is equivalent to the -a option. Warning: grep —binary-files=text might output binary garbage, which can have nasty side effects if the output is a terminal and if the terminal driver interprets some of it as commands. |
| -D ACTION,—devices=ACTION | If an input file is a device, FIFO or socket, use ACTION to process it. By default, ACTION is read, which means that devices are read as if they were ordinary files. If ACTION is skip, devices are silently skipped. |
| -d ACTION,—directories=ACTION | If an input file is a directory, use ACTION to process it. By default, ACTION is read, i.e., read directories as if they were ordinary files. If ACTION is skip, silently skip directories. If ACTION is recurse, read all files under each directory, recursively, following symbolic links only if they are on the command line. This is equivalent to the -r option. |
| —exclude=GLOB | Skip files whose base name matches GLOB (using wildcard matching). A file-name glob can use *, ?, and as wildcards, and \ to quote a wildcard or backslash character literally. |
| —exclude-from=FILE | Skip files whose base name matches any of the file-name globs read from FILE (using wildcard matching as described under —exclude). |
| —exclude-dir=DIR | Exclude directories matching the pattern DIR from recursive searches. |
| -I | Process a binary file as if it did not contain matching data; this is equivalent to the —binary-files=without-match option. |
| —include=GLOB | Search only files whose base name matches GLOB (using wildcard matching as described under —exclude). |
| -r, —recursive | Read all files under each directory, recursively, following symbolic links only if they are on the command line. This is equivalent to the -d recurse option. |
| -R,—dereference-recursive | Read all files under each directory, recursively. Follow all symbolic links, unlike -r. |
Разница между grep, egrep, fgrep, pgrep, zgrep
Различные переключатели grep исторически были включены в различные двоичные файлы. В современных системах Linux вы найдете эти переключатели доступными в команде base grep, но часто дистрибутивы поддерживают и другие команды.
Со страницы руководства для grep:
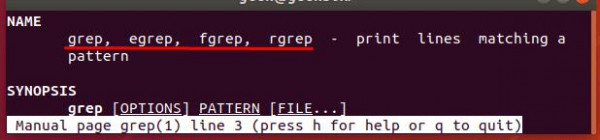
egrep является эквивалентом grep -E
Этот переключатель будет интерпретировать шаблон как расширенное регулярное выражение . Есть множество разных вещей, которые вы можете сделать с этим, но вот пример того, как выглядит использование регулярного выражения с grep.
Давайте найдем в текстовом документе строки, которые содержат две последовательные буквы «р»:
$ egrep p\{2} fruits.txt
или
$ grep -E p\{2} fruits.txt

fgrep является эквивалентом grep -F
Этот переключатель будет интерпретировать шаблон как список фиксированных строк и попытаться сопоставить любую из них. Это полезно, когда вам нужно искать символы регулярного выражения. Это означает, что вам не нужно экранировать специальные символы, как если бы вы использовали обычный grep.
$ fgrep $ License.txt There is a $100 free for commercial use.
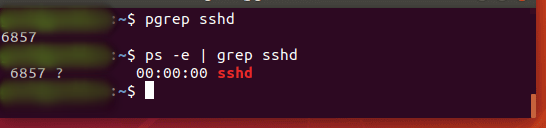
pgrep — это команда для поиска имени запущенного процесса в вашей системе и возврата соответствующих идентификаторов процесса. Например, вы можете использовать его, чтобы найти идентификатор процесса демона SSH:
$ pgrep sshd
По функциям это похоже на простую передачу вывода команды ‘ps’ в grep.
Вы можете использовать эту информацию, чтобы убить работающий процесс или устранить проблемы со службами, работающими в вашей системе.
zgrep используется для поиска сжатых файлов по шаблону. Это позволяет вам искать файлы внутри сжатого архива без необходимости сначала распаковывать этот архив, в основном экономя вам дополнительный шаг или два.
$ zgrep apple fruits.txt.gz
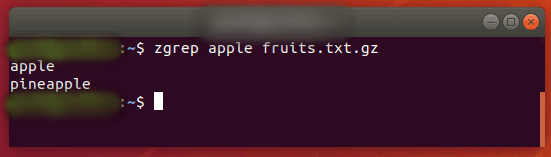
zgrep также работает с tar-файлами, но кажется, что он говорит только о том, удалось ли найти совпадение.
$ zgrep apple fruits.tar.gz
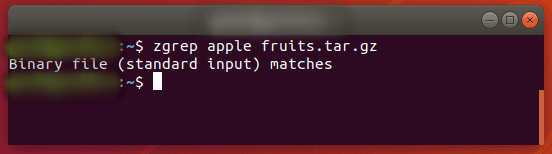
Мы упоминаем об этом, потому что файлы, сжатые с помощью gzip, обычно являются архивами tar.
msggrep, mboxgrep
Это совсем уже узко специализированная штуковина, чтобы парсить каталоги локализации. Идет в комплекте с пакетом gettext. Программа не из разряда пользовательских, но если очень нужно, можно запустить с командной строки.
Следующий экспонат — парсер почтовых ящиков mboxgrep. Проект так и не взлетел, его разработка прекращена. По идее он должен был находить паттерны в письмах и обрабатывать вывод так как будто это отдельные файлы. Однако, для начала он эти паттерны должен уметь находить.
А он не находит.
Что странно, системные вызовы все время одни и те же, вне зависимости от поиска.
Любопытно было бы узнать, завелась ли данная программа успешно у кого-нибудь?
Ну ладно, мы увлеклись, а греп семейство еще не инвентаризировано полностью.
grep примеры использования
В принципе для работы grep не обязательно указывать даже файл или директорию, но это крайне желательно, если Вы хотите найти всё быстрее и точнее. Например:
Найдет файлы с упоминанием меня любимого, если таковые есть. Точнее не файлы, а строки с упоминанием указанного слова, т.е в данном случае sonikelf. Здесь стоит упомянуть, что строкой grep считает все символы, находящиеся между двумя символами новой строки.
| grep sonikelf file.txt | поиск sonikelf в файле file.txt, с выводом полностью совпавшей строкой |
| grep -o sonikelf file.txt | поиск sonikelf в файле file.txt и вывод только совпавшего куска строки |
| grep -i sonikelf file.txt | игнорирование регистра при поиске |
| grep -bn sonikelf file.txt | показать строку (-n) и столбец (-b), где был найден sonikelf |
| grep -v sonikelf file.txt | инверсия поиска (найдет все строки, которые не совпадают с шаблоном sonikelf) |
| grep -A 3 sonikelf file.txt | вывод дополнительных трех строк, после совпавшей |
| grep -B 3 sonikelf file.txt | вывод дополнительных трех строк, перед совпавшей |
| grep -C 3 sonikelf file.txt | вывод три дополнительные строки перед и после совпавшей |
| grep -r sonikelf $HOME | рекурсивный поиск по директории $HOME и всем вложенным |
| grep -c sonikelf file.txt | подсчет совпадений |
| grep -L sonikelf *.txt | вывести список txt-файлов, которые не содержат sonikelf |
| grep -l sonikelf *.txt | вывести список txt-файлов, которые содержат sonikelf |
| grep -w sonikelf file.txt | совпадение только с полным словом sonikelf |
| grep -f sonikelfs.txt file.txt | поиск по нескольким sonikelf из файла sonikelfs.txt, шаблоны разделяются новой строкой |
| grep -I sonikelf file.txt | игнорирование бинарных файлов |
| grep -v -f file2 file1 > file3 | вывод строк, которые есть в file1 и нет в file2 |
| grep -in -e ‘python’ `find -type f` | рекурсивный поиск файлов, содержащих слово python с выводом номера строки и совпадений |
| grep -inc -e ‘test’ `find -type f` | grep -v :0 | рекурсивный поиск файлов, содержащих слово python с выводом количества совпадений |
| grep . *.py | вывод содержимого всех py-файлов, предваряя каждую строку именем файла |
| grep «Http404» apps/**/*.py | рекурсивный поиск упоминаний Http404 в директории apps в py-файлах |