Node.js
Содержание:
- Сравнение строк
- Жадность
- Replacing elements using JavaScript Array splice() method
- regexp.test(str)
- Описание
- Сравнение строк
- Как найти подстроку
- Доступ к символам
- str.replace(str|regexp, str|func)
- Улучшена поддержка юникода
- The slice() Method
- regexp.exec(str)
- Точка и перенос строки
- Поиск текста в строке
- Определение строки
Сравнение строк
Равенство
Как вы знаете, что сравнивая два строковых примитива, вы можете использовать операторы == или ===:
Если вы сравниваете строковый примитив с чем-то, что не является строкой, == и === ведут себя по-разному.
При использовании оператора == не-строка будет преобразована в строку. Это означает, что JavaScript попытается преобразовать его в строку перед сравнением значений.
Для строгого сравнения, когда не-строки не приводятся к строкам, используйте ===:
То же самое верно и для операторов неравенства != и !==:
Если вы не знаете, что использовать, отдавайте предпочтение строгому равенству ===.
Чувствительность к регистру
Когда требуется сравнение без учета регистра, обычно преобразуют обе строки в верхний или нижний регистры и сравнивают результат.
Однако иногда вам нужно больше контроля над сравнением. Об этом в следующем разделе …
Работа с диакритическими знаками в строках JavaScript
Диакритические знаки — это модификации буквы, например é или ž.
Возможно вы захотите указать, как они обрабатываются при сравнении двух строк.
Например, в некоторых языках принято исключать акценты при написании прописных букв.
Если вам нужно сравнение без учета регистра, простое преобразование двух строк в один и тот же регистр с помощью toUpperCase() или toLowerCase() не будет учитывать добавление / удаление акцентов и может не дать ожидаемого результата.
Если вам нужен более точный контроль над сравнением, используйте вместо него localeCompare:
Метод localeCompare позволяет указать «sensitivity» сравнения.
Здесь мы использовали base «sensitivity» для сравнения строк с использованием их «базовых» символов (что означает, что регистр и акценты игнорируются).
Поддержка localeCompare() браузерами:
Chrome: 24+
Edge: 12+
Firefox: 29+
Safari: 10+
Opera: 15+
Больше / меньше
При сравнении строк с использованием операторов < и > JavaScript будет сравнивать каждый символ в «лексикографическом порядке».
Это означает, что они сравниваются по буквам в том порядке, в котором они появляются в словаре:
True или false строки
Пустые строки в JavaScript считаются равными false при сравнении с использованием оператора == (но не при использовании ===)
Строки со значением являются «истинными», поэтому вы можете делать нечто подобное:
Жадность
Это не совсем особенность, скорее фича, но все же достойная отдельного абзаца.
Все регулярные выражения в javascript – жадные. То есть, выражение старается отхватить как можно больший кусок строки.
Например, мы хотим заменить все открывающие тэги
На что и почему – не так важно
При запуске вы увидите, что заменяется не открывающий тэг, а вся ссылка, выражение матчит её от начала и до конца.
Это происходит из-за того, что точка-звёздочка в «жадном» режиме пытается захватить как можно больше, в нашем случае – это как раз до последнего .
Последний символ точка-звёздочка не захватывает, т.к. иначе не будет совпадения.
Как вариант решения используют квадратные скобки: :
Это работает. Но самым удобным вариантом является переключение точки-звёздочки в нежадный режим. Это осуществляется простым добавлением знака «» после звёздочки.
В нежадном режиме точка-звёздочка пустит поиск дальше сразу, как только нашла совпадение:
В некоторых языках программирования можно переключить жадность на уровне всего регулярного выражения, флагом.
В javascript это сделать нельзя… Вот такая особенность. А вопросительный знак после звёздочки рулит – честное слово.
Replacing elements using JavaScript Array splice() method
The method allows you to insert new elements into an array while deleting existing elements simultaneously.
To do this, you pass at least three arguments with the second one that specifies the number of items to delete and the third one that indicates the elements to insert.
Note that the number of elements to delete needs not to be the same as the number of elements to insert.
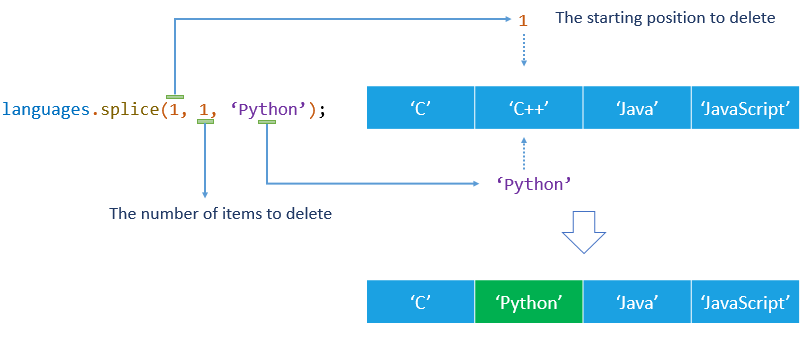
Suppose you have an array of programming languages with four elements as follows:
The following statement replaces the second element by a new one.
The array now still has four elements with the new second argument is instead of .
The following figure illustrates the method call above.
You can replace one element with multiple elements by passing more arguments into the method as follows:
The statement deletes one element from the second element i.e., and inserts three new elements into the array. The result is as follows.
In this tutorial, you have learned how to use the JavaScript Array method to delete existing elements, insert new elements, and replace elements in an array.
regexp.test(str)
The method looks for a match and returns whether it exists.
For instance:
An example with the negative answer:
If the regexp has flag , then looks from property and updates this property, just like .
So we can use it to search from a given position:
Same global regexp tested repeatedly on different sources may fail
If we apply the same global regexp to different inputs, it may lead to wrong result, because call advances property, so the search in another string may start from non-zero position.
For instance, here we call twice on the same text, and the second time fails:
That’s exactly because is non-zero in the second test.
To work around that, we can set before each search. Or instead of calling methods on regexp, use string methods , they don’t use .
Описание
Этот метод не изменяет объект , на котором он вызывается. Он просто возвращает новую строку.
Для выполнения глобального поиска и замены либо включите флаг в регулярное выражение, либо, если первый параметр является строкой, включите флаг в параметр .
строка замены может включать следующие специальные шаблоны замены:
| Шаблон | Замена |
| Вставляет символ доллара «$». | |
| Вставляет сопоставившуюся подстроку. | |
| Вставляет часть строки, предшествующую сопоставившейся подстроке. | |
| Вставляет часть строки, следующую за сопоставившейся подстрокой. | |
| или | Символы или являются десятичными цифрами, вставляет n-ную сопоставившуюся подгруппу из объекта в первом параметре. |
В качестве второго параметра вы можете передать функцию. В этом случае функция будет выполнена после произошедшего сопоставления
Результат вызова функции (её возвращаемое значение) будет использоваться в качестве строки замены (обратите внимание: описанные выше специальные шаблоны замены в этом случае не применяются). Обратите внимание, что функция будет вызвана несколько раз для каждого полного сопоставления, если регулярное выражение в первом параметре является глобальным
Функция принимает следующие аргументы:
| Возможное имя | Получаемое значение |
| Сопоставившаяся подстрока (соответствует шаблону замены , описанному выше). | |
| n-ная сопоставившаяся подгруппа из объекта в первом параметре метода (соответствует шаблонам замены , и так далее, описанным выше). Например, если в качестве шаблона передано регулярное выражение , параметр будет значение сопоставления с подгруппой , а параметр — с подгруппой . | |
| Смещение сопоставившейся подстроки внутри всей рассматриваемой строки (например, если вся строка равна , а сопоставившаяся подстрока равна , то этот аргумент будет равен 1). | |
| Вся рассматриваемая строка. |
Точное число аргументов будет зависеть от того, был ли первым аргументом объект и, если был, сколько подгрупп в нём определено.
Следующий пример установит переменную в значение :
Сравнение строк
Строки как и другие литералы в JavaScript, строки можно сравнить двумя способами, с помощью слудующих операторов:
- Оператор == — сравнение по значению
- Оператор === — сравнение по значению и по типу данных
var a = «one»;
var b = «two»;
var c = «one»;
var x = new string(«one»);
// (a == b) — false Значения не равны;
// (a == c) — true Значения равны;
// (a == x) — true Значения равны;
// (a === c) — true Значения и типы переменных равны;
// (a === x) — false Значения равны, а типы переменных нет, т.к. a — строка, x — объект.
|
1 |
vara=»one»; varb=»two»; varc=»one»; varx=newstring(«one»); // (a == b) — false Значения не равны; |
Как найти подстроку
includes
Проверяет, содержит ли строка указанную подстроку. Возвращает значение true или false. Вторым параметром можно указать позицию в строке, с которой следует начать поиск.
indexOf
Возвращает индекс первого найденного вхождения указанного значения. Поиск ведётся от начала до конца строки. Если совпадений нет, возвращает -1. Вторым параметром можно передать позицию, с которой следует начать поиск.
lastIndexOf
Возвращает индекс последнего найденного вхождения указанного значения. Поиск ведётся от конца к началу строки. Если совпадений нет, возвращает -1. Вторым параметром можно передать позицию, с которой следует начать поиск.
endsWith
Проверяет, заканчивается ли строка символами, заданными первым параметром. Возвращает true или false. Есть второй необязательный параметр — ограничитель по диапазону поиска. По умолчанию он равен длине строки.
startsWith
Проверяет, начинается ли строка с указанных символов. Возвращает true или false. Вторым параметром можно указать индекс, с которого следует начать проверку.
Доступ к символам
Продемонстрируем, как получить доступ к символам и индексам строки How are you?
"How are you?";
Используя квадратные скобки, можно получить доступ к любому символу строки.
"How are you?"; Вывод r
Мы также можем использовать метод charAt(), чтобы вернуть символ, передавая индекс в качестве параметра.
"Howareyou?".charAt(5); Вывод r
Также можно использовать indexOf(), чтобы вернуть индекс первого вхождения символа в строке.
"How are you?".indexOf("o");
Вывод
1
Несмотря на то, что символ «o» появляется в строке How are you? дважды, indexOf() вернёт позицию первого вхождения.
lastIndexOf() используется, чтобы найти последнее вхождение.
"How are you?".lastIndexOf("o");
Вывод
9
Оба метода также можно использовать для поиска нескольких символов в строке. Они вернут индекс первого символа.
"How are you?".indexOf("are");
Вывод
4
А вот метод slice() вернёт символы между двумя индексами.
"How are you?".slice(8, 11); Вывод you
Обратите внимание на то, что 11– это ?, но? не входит в результирующую строку. slice() вернёт всё, что между указанными значениями индекса
Если второй параметр опускается, slice() вернёт всё, начиная от первого параметра до конца строки.
"How are you?".slice(8); Вывод you?
Методы charAt() и slice() помогут получить строковые значения на основании индекса. А indexOf() и lastIndexOf() делают противоположное, возвращая индексы на основании переданной им строки.
str.replace(str|regexp, str|func)
Это универсальный метод поиска-и-замены, один из самых полезных. Этакий швейцарский армейский нож для поиска и замены в строке.
Мы можем использовать его и без регулярных выражений, для поиска-и-замены подстроки:
Хотя есть подводный камень.
Когда первый аргумент является строкой, он заменяет только первое совпадение.
Вы можете видеть это в приведённом выше примере: только первый заменяется на .
Чтобы найти все дефисы, нам нужно использовать не строку , а регулярное выражение с обязательным флагом :
Второй аргумент – строка замены. Мы можем использовать специальные символы в нем:
| Спецсимволы | Действие в строке замены |
|---|---|
| вставляет | |
| вставляет всё найденное совпадение | |
| вставляет часть строки до совпадения | |
| вставляет часть строки после совпадения | |
| если это 1-2 значное число, то вставляет содержимое n-й скобки | |
| вставляет содержимое скобки с указанным именем |
Например:
Для ситуаций, которые требуют «умных» замен, вторым аргументом может быть функция.
Она будет вызываться для каждого совпадения, и её результат будет вставлен в качестве замены.
Функция вызывается с аргументами :
- – найденное совпадение,
- – содержимое скобок (см. главу Скобочные группы).
- – позиция, на которой найдено совпадение,
- – исходная строка,
- – объект с содержимым именованных скобок (см. главу Скобочные группы).
Если скобок в регулярном выражении нет, то будет только 3 аргумента: .
Например, переведём выбранные совпадения в верхний регистр:
Заменим каждое совпадение на его позицию в строке:
В примере ниже две скобки, поэтому функция замены вызывается с 5-ю аргументами: первый – всё совпадение, затем два аргумента содержимое скобок, затем (в примере не используются) индекс совпадения и исходная строка:
Если в регулярном выражении много скобочных групп, то бывает удобно использовать остаточные аргументы для обращения к ним:
Или, если мы используем именованные группы, то объект с ними всегда идёт последним, так что можно получить его так:
Использование функции даёт нам максимальные возможности по замене, потому что функция получает всю информацию о совпадении, имеет доступ к внешним переменным и может делать всё что угодно.
Улучшена поддержка юникода
Внутренняя кодировка строк в JavaScript – это UTF-16, то есть под каждый символ отводится ровно два байта.
Но под всевозможные символы всех языков мира 2 байт не хватает. Поэтому бывает так, что одному символу языка соответствует два юникодных символа (итого 4 байта). Такое сочетание называют «суррогатной парой».
Самый частый пример суррогатной пары, который можно встретить в литературе – это китайские иероглифы.
Заметим, однако, что не всякий китайский иероглиф – суррогатная пара. Существенная часть «основного» юникод-диапазона как раз отдана под китайский язык, поэтому некоторые иероглифы – которые в неё «влезли» – представляются одним юникод-символом, а те, которые не поместились (реже используемые) – двумя.
Например:
В тексте выше для первого иероглифа есть отдельный юникод-символ, и поэтому длина строки , а для второго используется суррогатная пара. Соответственно, длина – .
Китайскими иероглифами суррогатные пары, естественно, не ограничиваются.
Ими представлены редкие математические символы, а также некоторые символы для эмоций, к примеру:
В современный JavaScript добавлены методы String.fromCodePoint и str.codePointAt – аналоги и , корректно работающие с суррогатными парами.
Например, считает суррогатную пару двумя разными символами и возвращает код каждой:
…В то время как возвращает его Unicode-код суррогатной пары правильно:
Метод корректно создаёт строку из «длинного кода», в отличие от старого .
Например:
Более старый метод в последней строке дал неверный результат, так как он берёт только первые два байта от числа и создаёт символ из них, а остальные отбрасывает.
Есть и ещё синтаксическое улучшение для больших Unicode-кодов.
В JavaScript-строках давно можно вставлять символы по Unicode-коду, вот так:
Синтаксис: , где – четырёхзначный шестнадцатиричный код, причём он должен быть ровно четырёхзначным.
«Лишние» цифры уже не войдут в код, например:
Чтобы вводить более длинные коды символов, добавили запись , где – максимально восьмизначный (но можно и меньше цифр) код.
Например:
Во многих языках есть символы, которые получаются как сочетание основного символа и какого-то значка над ним или под ним.
Например, на основе обычного символа существуют символы: . Самые часто встречающиеся подобные сочетания имеют отдельный юникодный код. Но отнюдь не все.
Для генерации произвольных сочетаний используются несколько юникодных символов: основа и один или несколько значков.
Например, если после символа идёт символ «точка сверху» (код ), то показано это будет как «S с точкой сверху» .
Если нужен ещё значок над той же буквой (или под ней) – без проблем. Просто добавляем соответствующий символ.
К примеру, если добавить символ «точка снизу» (код ), то будет «S с двумя точками сверху и снизу» .
Пример этого символа в JavaScript-строке:
Такая возможность добавить произвольной букве нужные значки, с одной стороны, необходима, а с другой стороны – возникает проблемка: можно представить одинаковый с точки зрения визуального отображения и интерпретации символ – разными сочетаниями Unicode-кодов.
Вот пример:
В первой строке после основы идёт сначала значок «верхняя точка», а потом – нижняя, во второй – наоборот. По кодам строки не равны друг другу. Но символ задают один и тот же.
С целью разрешить эту ситуацию, существует юникодная нормализация, при которой строки приводятся к единому, «нормальному», виду.
В современном JavaScript это делает метод str.normalize().
Забавно, что в данной конкретной ситуации приведёт последовательность из трёх символов к одному: \u1e68 (S с двумя точками).
Это, конечно, не всегда так, просто в данном случае оказалось, что именно такой символ в юникоде уже есть. Если добавить значков, то нормализация уже даст несколько символов.
Для большинства практических задач информации, данной выше, должно быть вполне достаточно, но если хочется более подробно ознакомиться с вариантами и правилами нормализации – они описаны в приложении к стандарту юникод Unicode Normalization Forms.
The slice() Method
extracts a part of a string and returns the
extracted part in a new string.
The method takes 2 parameters: the start position, and the end position (end
not included).
This example slices out a portion of a string from position 7 to position 12 (13-1):
let str = «Apple, Banana, Kiwi»;
str.slice(7, 13) // Returns Banana
Remember: JavaScript counts positions from zero. First position is 0.
If a parameter is negative, the position is counted from the
end of the string.
This example slices out a portion of a string from position -12 to position
-6:
let str = «Apple, Banana, Kiwi»;
str.slice(-12, -6) // Returns Banana
If you omit the second parameter, the method will slice out the rest of the string:
str.slice(7); // Returns Banana,Kiwi
or, counting from the end:
regexp.exec(str)
The method returns a match for in the string . Unlike previous methods, it’s called on a regexp, not on a string.
It behaves differently depending on whether the regexp has flag .
If there’s no , then returns the first match exactly as . This behavior doesn’t bring anything new.
But if there’s flag , then:
- A call to returns the first match and saves the position immediately after it in the property .
- The next such call starts the search from position , returns the next match and saves the position after it in .
- …And so on.
- If there are no matches, returns and resets to .
So, repeated calls return all matches one after another, using property to keep track of the current search position.
In the past, before the method was added to JavaScript, calls of were used in the loop to get all matches with groups:
This works now as well, although for newer browsers is usually more convenient.
We can use to search from a given position by manually setting .
For instance:
If the regexp has flag , then the search will be performed exactly at the position , not any further.
Let’s replace flag with in the example above. There will be no matches, as there’s no word at position :
That’s convenient for situations when we need to “read” something from the string by a regexp at the exact position, not somewhere further.
Точка и перенос строки
Для поиска в многострочном режиме почти все модификации перловых регэкспов используют специальный multiline-флаг.
И javascript здесь не исключение.
Попробуем же сделать поиск и замену многострочного вхождения. Скажем, будем заменять на тэг подчёркивания: :
Попробуйте запустить. Заменяет? Как бы не так!
Дело в том, что в javascript мультилайн режим (флаг ) влияет только на символы ^ и $, которые начинают матчиться с началом и концом строки, а не всего текста.
Точка по-прежнему – любой символ, кроме новой строки. В javascript нет флага, который устанавливает мультилайн-режим для точки. Для того, чтобы заматчить совсем что угодно – используйте .
Работающий вариант:
Поиск текста в строке
Найти позицию подстроки
Вы можете искать строку внутри другой строки в JavaScript с помощью indexOf().
Этот метод вернет позицию первого упоминания искомой подстроки в строке или -1, если подстрока не найдена:
Вы также можете использовать метод регулярных выражений search(), чтобы сделать то же самое:
Чтобы найти последнее вхождение поискового запроса, используйте lastIndexOf():
Все эти методы вернут -1, если подстрока не найдена в целевой строке.
Начинается с / заканчивается на
Вы можете использовать методы indexOf(), указанные выше, чтобы проверить, начинается ли строка с поискового запроса или заканчивается им.
Однако ES6 добавил для этого специальные методы:
Поддержка startsWith() и endsWith() браузерами:
Chrome: 41+
Edge: 12+
Firefox: 17+
Safari: 9+
Opera: 28+
Includes
Если вам не важна конкретная позиция подстроки и важно только, находится ли она вообще в целевой строке, вы можете использовать includes():
Поддержка includes() браузерами:
Chrome: 41+
Edge: 12+
Firefox: 40+
Safari: 9+
Opera: 28+
Регулярные выражения
Чтобы найти первое совпадение регулярного выражения, используйте .search().
Чтобы вернуть массив, содержащий все совпадения регулярного выражения, используйте match() с модификатором /g (global):
(использование match() без модификатора /g вернет только первое совпадение и некоторые дополнительные свойства, такие как индекс результата в исходной строке и любые именованные группы захвата)
Если вам нужна дополнительная информация о каждом совпадении, включая их индекс в исходной строке, вы можете использовать matchAll.
Этот метод возвращает итератор, поэтому вы можете использовать цикл for … of для результатов. Вы должны использовать регулярное выражение с модификатором /g/ в matchAll():
Подробнее о регулярных выражениях.
Определение строки
Строкой считается любая последовательность символов в пределах двойных или одинарных кавычек.
var someString = «This is a string»;
var anotherString = ‘This is another string’;
|
1 |
varsomeString=»This is a string»; varanotherString=’This is another string’; |
Для создания строки с кавычками, нужно их экранировать (обособить) с помощью символа обратный слэш или использовать два разных вида кавычек.
var string = «String with \»quoted\» word»;
var string = ‘String with \’quoted\’ word’;
var string = ‘String with «quoted» word’;
var string = «String with ‘quoted’ word»;
var string = «It’s single quote string»; //Апостроф внутри строки
var string = ‘<div id=»block»>This is block</div>’; //В строке может содержаться код HTML
|
1 |
varstring=»String with \»quoted\» word»; varstring=’String with \’quoted\’ word’; varstring=’String with «quoted» word’; varstring=»String with ‘quoted’ word»; varstring=»It’s single quote string»;//Апостроф внутри строки varstring='<div id=»block»>This is block</div>’;//В строке может содержаться код HTML |
Помимо двойных и одинарных кавычек, экранизации подлежат и другие символы (escape последовательности), управляющие форматированием текста.
| Символ | Обозначение |
|---|---|
| \’ | одинарная кавычка |
| \» | двойная кавычка |
| \\ | обратный слэш (не путать с // — знаком начала комментария) |
| \n | новая строка (работает как кнопка Enter) |
| \r | возврат каретки в начало строки (работает как кнопка Home) |
| \t | табуляция (работает как кнопка Tab) |
| \b | удаление символа (работает как кнопка Backspace) |
| \f | печать с новой страницы (устаревшее) |
| \v | вертикальная табуляция (устаревшее) |
| \a | звуковой сигнал (устаревшее) |
| \xXX | символ из Latin-1, где XX шестнадцатеричные цифры (например: \xAF — символ ‘-‘) |
| \XXX | символ из Latin-1, где XXX восьмеричные цифры от 1 до 377 (например: \300 — символ ‘À’) |
| \ucXXXX | символ из Unicode, где XXXX шестнадцатеричные цифры (например: \uc454 — символ ‘쑔’) |
В случае если строка достаточно длинная, то для более легкого чтения ее можно разбить на подстроки с помощью символа обратного слэша , не нарушая при этом самой структуры строки.
var longString = «Lorem ipsum dolor sit amet, consectetur adipisicing elit.\
Aliquam eligendi non ipsum autem facere repellendus doloremque, \
architecto obcaecati culpa dolores eveniet qui, beatae suscipit ab nisi ad vero, sed cum!»;
|
1 |
varlongString=»Lorem ipsum dolor sit amet, consectetur adipisicing elit.\ Aliquam eligendi non ipsum autem facere repellendus doloremque, \ architecto obcaecati culpa dolores eveniet qui, beatae suscipit ab nisi ad vero, sed cum!»; |
Однако использование следующего приема для разбиения кода недопустимо.
var string = «Lorem ipsum dolor sit amet,» + \
«consectetur adipisicing elit.»;
|
1 |
varstring=»Lorem ipsum dolor sit amet,»+\ «consectetur adipisicing elit.»; |